
Post updated on February 3, 2025 with details about CUDA 12.8.
CUDA Graphs can provide a significant performance increase, as the driver is able to optimize execution using the complete description of tasks and dependencies. Graphs provide incredible benefits for static workflows where the overhead of graph creation can be amortized over many successive launches.
However, nearly all problems involve some form of decision-making, which can require splitting up graphs and returning control to the CPU to decide which work to launch next. Breaking up the work like this compromises CUDA’s ability to make optimizations, ties up CPU resources, and adds overhead with each graph launch.
In CUDA 12.8, which supports the NVIDIA Blackwell architecture, CUDA Graphs supports conditional nodes, which enable the conditional or repeated execution of portions of a graph without returning control to the CPU. This frees up CPU resources, enabling many more workflows to be represented in a single graph.
Conditional nodes
In CUDA 12.4 conditional nodes came in two flavors:
- IF nodes: the body is executed once each time the node is evaluated if the condition value is true.
- WHILE nodes: the body is executed repeatedly when the node is evaluated as long as the condition value is true.
Starting in CUDA 12.8, two more conditional node types are supported:
- IF nodes: support an optional second graph which is executed once each time the node is evaluated if the condition value is false. This allows a single conditional node to function as an IF/ELSE node.
- SWITCH nodes: the conditional node can contain n graphs. The nth graph is executed once each time the node is evaluated if the condition value is n. If the condition value is greater or equal to n, no graph is executed when the node is evaluated.
Conditional nodes are container nodes, similar to child graph nodes, but the execution of the graph contained within the node is dependent on the value of a condition variable. The condition value associated with a node is accessed by a handle that must be created prior to the node. The condition value can be set in a CUDA kernel by calling cudaGraphSetConditional. An initialization, applied at each start of the graph, can also be specified when the handle is created.
When the conditional node is created, an empty graph is also created, and the handle is returned to the user. This graph is tied to the node and will be executed based on the condition value. This conditional body graph can be populated using either the graph API or by capturing asynchronous CUDA calls using cudaStreamBeginCaptureToGraph.
Conditional nodes can also be nested. For example, you can create a conditional WHILE node with a body graph that contains a conditional IF node.
Conditional node body graphs can contain any of the following:
- Kernel nodes (CNP, cooperative not currently supported)
- Empty nodes
- Child graph nodes
- Memset nodes
- Memcopy nodes
- Conditional nodes
This applies recursively to child graphs and conditional bodies. All kernels, including kernels in nested conditionals or child graphs at any level, must belong to the same CUDA context. Memcopies and memsets must act on memory reachable from the conditional node’s context.
Complete samples are available in the CUDA samples repository. The next section runs through some examples to show what you can do with conditional nodes.
Conditional IF nodes
The body graph of an IF node will be executed once if the condition is non-zero whenever the IF node is evaluated. Figure 1 depicts a graph where the middle node, B, is an IF conditional node containing a four-node graph:

To show how this graph could be created, the following example uses node A, a kernel upstream of the conditional node, B, to set the value of the conditional based on the results of work done by that kernel. The body of the conditional is populated using the graph API.
First, define the node A kernel. This kernel sets the conditional handle depending on the result of some arbitrary calculations performed by the user.
__global__ void setHandle(cudaGraphConditionalHandle handle)
{
unsigned int value = 0;
// We could perform some work here and set value based on the result of that work.
if (someCondition) {
// Set ‘value’ to non-zero if we want the conditional body to execute
value = 1;
}
cudaGraphSetConditional(handle, value);
}
Next, define a function to construct the graph. This function allocates the conditional handle, creates the nodes, and populates the body of the conditional graph. For clarity, the code to launch and execute the graph is omitted.
cudaGraph_t createGraph() {
cudaGraph_t graph;
cudaGraphNode_t node;
void *kernelArgs[1];
cudaGraphCreate(&graph, 0);
cudaGraphConditionalHandle handle;
cudaGraphConditionalHandleCreate(&handle, graph);
// Use a kernel upstream of the conditional to set the handle value
cudaGraphNodeParams kParams = { cudaGraphNodeTypeKernel };
kParams.kernel.func = (void *)setHandle;
kParams.kernel.gridDim.x = kParams.kernel.gridDim.y = kParams.kernel.gridDim.z = 1;
kParams.kernel.blockDim.x = kParams.kernel.blockDim.y = kParams.kernel.blockDim.z = 1;
kParams.kernel.kernelParams = kernelArgs;
kernelArgs[0] = &handle;
cudaGraphAddNode(&node, graph, NULL, 0, &kParams);
cudaGraphNodeParams cParams = { cudaGraphNodeTypeConditional };
cParams.conditional.handle = handle;
cParams.conditional.type = cudaGraphCondTypeIf;
cParams.conditional.size = 1;
cudaGraphAddNode(&node, graph, &node, 1, &cParams);
cudaGraph_t bodyGraph = cParams.conditional.phGraph_out[0];
// Populate the body of the conditional node
cudaGraphNode_t bodyNodes[4];
cudaGraphNodeParams params[4] = { ... }; // Setup kernel parameters as needed.
cudaGraphAddNode(&bodyNodes[0], bodyGraph, NULL, 0, ¶ms[0]);
cudaGraphAddNode(&bodyNodes[1], bodyGraph, &bodyNodes[0], 1, ¶ms[1]);
cudaGraphAddNode(&bodyNodes[2], bodyGraph, &bodyNodes[0], 1, ¶ms[2]);
cudaGraphAddNode(&bodyNodes[3], bodyGraph, &bodyNodes[1], 2, ¶ms[3]);
return graph;
}
Conditional IF nodes with ELSE branch
Beginning with CUDA 12.8, IF nodes support an optional, second graph which is executed when the condition value is false. This ELSE graph is populated in the same way as the first graph. Figure 2 depicts a graph where the middle node, B, is an IF conditional node containing a four-node graph as well as a three-node ELSE graph.
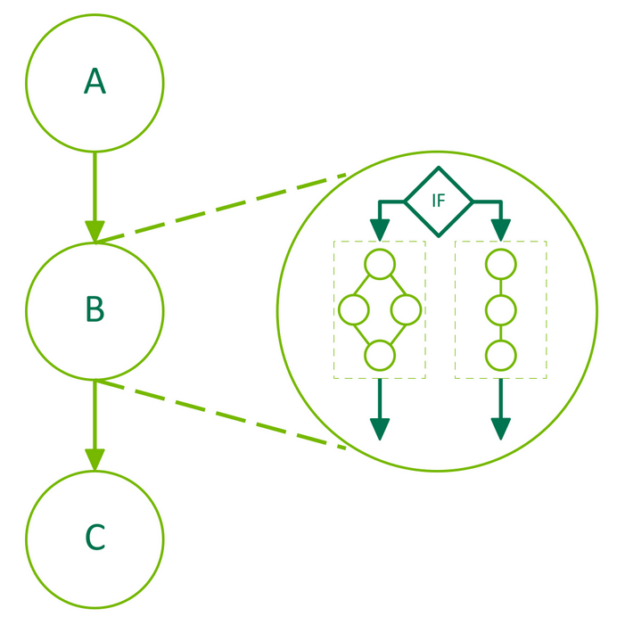
A second, empty graph will be created inside the conditional node when we set the size parameter to 2. We can then populate this second graph as we have done before. We define a new createGraph() function below which demonstrates this. For clarity, the code to launch and execute the graph is omitted.
cudaGraph_t createGraph() {
cudaGraph_t graph;
cudaGraphNode_t kernelNode, conditionalNode;
void *kernelArgs[1];
cudaGraphCreate(&graph, 0);
cudaGraphConditionalHandle handle;
cudaGraphConditionalHandleCreate(&handle, graph);
// Use a kernel upstream of the conditional to set the handle value
cudaGraphNodeParams kParams = { cudaGraphNodeTypeKernel };
kParams.kernel.func = (void *)setHandle;
kParams.kernel.gridDim.x = kParams.kernel.gridDim.y = kParams.kernel.gridDim.z = 1;
kParams.kernel.blockDim.x = kParams.kernel.blockDim.y = kParams.kernel.blockDim.z = 1;
kParams.kernel.kernelParams = kernelArgs;
kernelArgs[0] = &handle;
cudaGraphAddNode(&kernelNode, graph, NULL, 0, &kParams);
cudaGraphNodeParams cParams = { cudaGraphNodeTypeConditional };
cParams.conditional.handle = handle;
cParams.conditional.type = cudaGraphCondTypeIf;
cParams.conditional.size = 2; // Size is now 2 to indicate we want an ELSE graph
cudaGraphAddNode(&conditionalNode, graph, &kernelNode, 1, &cParams);
cudaGraph_t ifGraph = cParams.conditional.phGraph_out[0];
cudaGraph_t elseGraph = cParams.conditional.phGraph_out[1];
cudaGraphNode_t bodyNodes[4]; // Reused for both IF and ELSE graphs
// Populate the body of the IF graph within the conditional node
cudaGraphNodeParams ifParams[4] = { ... }; // Setup kernel parameters as needed.
cudaGraphAddNode(&bodyNodes[0], ifGraph, NULL, 0, &ifParams[0]);
cudaGraphAddNode(&bodyNodes[1], ifGraph, &bodyNodes[0], 1, &ifParams[1]);
cudaGraphAddNode(&bodyNodes[2], ifGraph, &bodyNodes[0], 1, &ifParams[2]);
cudaGraphAddNode(&bodyNodes[3], ifGraph, &bodyNodes[1], 2, &ifParams[3]);
// Populate the body of the ELSE graph within the conditional node
cudaGraphNodeParams elseParams[3] = { ... }; // Setup kernel parameters as needed.
cudaGraphAddNode(&bodyNodes[0], elseGraph, NULL, 0, &elseParams[0]);
cudaGraphAddNode(&bodyNodes[1], elseGraph, &bodyNodes[0], 1, &elseParams[1]);
cudaGraphAddNode(&bodyNodes[2], elseGraph, &bodyNodes[1], 1, &elseParams[2]);
return graph;
}
Conditional WHILE nodes
The body graph of a WHILE node will be executed repeatedly as long as the condition is non-zero. The condition will be evaluated when the node is executed and after each completion of the body graph. The following diagram depicts a three-node graph where the middle node, B, is a WHILE conditional node containing a three-node graph.

To see how this graph could be created, the following example sets the handle’s default value to a non-zero value so the WHILE loop executes by default. Setting the default value to non-zero and leaving the conditional value in a kernel upstream of the conditional unmodified effectively makes a do-while loop, where the conditional body always executes at least once. Creating a WHILE loop, where the loop body only executes when the condition is true, requires performing some calculations and setting the conditional handle appropriately in node A.
In the previous example, the conditional body is populated with the graph API. In this example, the body of the conditional is populated using stream capture.
The first step is to define a kernel that sets the conditional value during each execution of the conditional body. In this example, the handle is set based on the value of a down counter.
__global__ void loopKernel(cudaGraphConditionalHandle handle)
{
static int count = 10;
cudaGraphSetConditional(handle, --count ? 1 : 0);
}
Next, define a function to construct the graph. This function allocates the conditional handle, creates the nodes, and populates the body of the conditional graph. For clarity, the code to launch and execute the graph is omitted.
cudaGraph_t createGraph() {
cudaGraph_t graph;
cudaGraphNode_t nodes[3];
cudaGraphCreate(&graph, 0);
// Insert kernel node A
cudaGraphNodeParams params = ...;
cudaGraphAddNode(&nodes[0], graph, NULL, 0, ¶ms);
cudaGraphConditionalHandle handle;
cudaGraphConditionalHandleCreate(&handle, graph, 1, cudaGraphCondAssignDefault);
// Insert conditional node B
cudaGraphNodeParams cParams = { cudaGraphNodeTypeConditional };
cParams.conditional.handle = handle;
cParams.conditional.type = cudaGraphCondTypeWhile;
cParams.conditional.size = 1;
cudaGraphAddNode(&nodes[1], graph, &nodes[0], 1, &cParams);
cudaGraph_t bodyGraph = cParams.conditional.phGraph_out[0];
cudaStream_t captureStream;
cudaStreamCreate(&captureStream);
// Fill out body graph with stream capture.
cudaStreamBeginCaptureToGraph(captureStream,
bodyGraph,
nullptr,
nullptr,
0,
cudaStreamCaptureModeRelaxed);
myKernel1<<<..., captureStream>>>(...);
myKernel2<<<..., captureStream>>>(...);
loopKernel<<<1, 1, 0, captureStream>>>(handle);
cudaStreamEndCapture(captureStream, nullptr);
cudaStreamDestroy(captureStream);
// Insert kernel node C.
params = ...;
cudaGraphAddNode(&nodes[2], graph, &nodes[1], 1, ¶ms);
return graph;
}
This example uses cudaStreamBeginCaptureToGraph, a new API added in CUDA 12.3 that enables stream capture to insert nodes into an existing graph. Using this API, multiple separate captures can be composed into a single graph object. This API also enables populating the conditional body graph object, which is created along with the conditional node.
Conditional SWITCH nodes
SWITCH nodes, added in CUDA 12.8, execute 1 of n different graphs within the conditional node. The nth graph will be executed when the SWITCH node is evaluated if the condition value is n. If the condition value is greater than or equal to n, no graph will be executed. Figure 4 depicts a graph where the middle node, B, is a SWITCH conditional node containing 3 different body graphs:
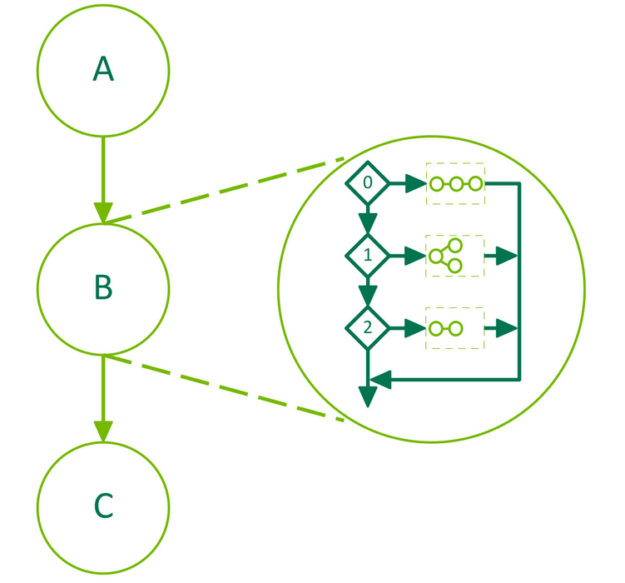
To show how this graph could be created, the following example uses node A, a kernel upstream of the conditional node, B, to set the value of the conditional based on the results of work done by that kernel. The body of the conditional is populated using the graph API.
First, define the node A kernel. This kernel sets the conditional handle depending on the result of some arbitrary calculations performed by the user.
__global__ void setHandle(cudaGraphConditionalHandle handle)
{
unsigned int value = 0;
// We could perform some work here and set value based on the result of that work.
if (someCondition) {
// Set ‘value’ to non-zero if we want the conditional body to execute
value = 1;
}
cudaGraphSetConditional(handle, value);
}
Next, define a function to construct the graph. This function allocates the conditional handle, creates the nodes, and populates the body of the conditional graph. For clarity, the code to launch and execute the graph is omitted.
cudaGraph_t createGraph() {
cudaGraph_t graph;
cudaGraphNode_t kernelNode, conditionalNode;
void *kernelArgs[1];
cudaGraphCreate(&graph, 0);
cudaGraphConditionalHandle handle;
cudaGraphConditionalHandleCreate(&handle, graph);
// Use a kernel upstream of the conditional to set the handle value
cudaGraphNodeParams kParams = { cudaGraphNodeTypeKernel };
kParams.kernel.func = (void *)setHandle;
kParams.kernel.gridDim.x = kParams.kernel.gridDim.y = kParams.kernel.gridDim.z = 1;
kParams.kernel.blockDim.x = kParams.kernel.blockDim.y = kParams.kernel.blockDim.z = 1;
kParams.kernel.kernelParams = kernelArgs;
kernelArgs[0] = &handle;
cudaGraphAddNode(&kernelNode, graph, NULL, 0, &kParams);
cudaGraphNodeParams cParams = { cudaGraphNodeTypeConditional };
cParams.conditional.handle = handle;
cParams.conditional.type = cudaGraphCondTypeSwitch;
cParams.conditional.size = 3;
cudaGraphAddNode(&conditionalNode, graph, &kernelNode, 1, &cParams);
cudaGraph_t bodyGraph = cParams.conditional.phGraph_out[0];
cudaGraphNode_t bodyNodes[3];
cudaGraphNodeParams params[3][3] = { ... }; // Setup kernel parameters as needed.
// Populate body graph 0
cudaGraphAddNode(&bodyNodes[0], bodyGraph, NULL, 0, ¶ms[0][0]);
cudaGraphAddNode(&bodyNodes[1], bodyGraph, &bodyNodes[0], 1, ¶ms[0][1]);
cudaGraphAddNode(&bodyNodes[2], bodyGraph, &bodyNodes[1], 1, ¶ms[0][2]);
// Populate body graph 1
bodyGraph = cParams.conditional.phGraph_out[1];
cudaGraphAddNode(&bodyNodes[0], bodyGraph, NULL, 0, ¶ms[1][0]);
cudaGraphAddNode(&bodyNodes[1], bodyGraph, &bodyNodes[0], 1, ¶ms[1][1]);
cudaGraphAddNode(&bodyNodes[2], bodyGraph, &bodyNodes[0], 1, ¶ms[1][2]);
// Populate body graph 2
bodyGraph = cParams.conditional.phGraph_out[2];
cudaGraphAddNode(&bodyNodes[0], bodyGraph, NULL, 0, ¶ms[2][0]);
cudaGraphAddNode(&bodyNodes[1], bodyGraph, &bodyNodes[0], 1, ¶ms[2][1]);
return graph;
}
Conclusion
CUDA Graphs provide incredible benefits for static workflows where the overhead of graph creation can be amortized over many successive launches. Using CUDA Graphs with conditional nodes enables the conditional or repeated execution of portions of a graph without returning control to the CPU. This frees up CPU resources and enables a single graph to represent substantially more complex workflows.
For more information on conditional nodes, see the CUDA Programming Guide. To explore simple, complete examples, visit NVIDIA/cuda-samples on GitHub. And join the conversation on the NVIDIA Developer CUDA forums.
