
CUDA Graphs significantly reduce the overhead of launching a large batch of user operations by defining them as a task graph, which may be launched in a single operation. Knowing the workflow upfront enables the CUDA driver to apply various optimizations, which cannot be performed when launching through a stream model.
However, this performance comes at the cost of flexibility. If the full workflow is not known in advance, then GPU execution must be interrupted to return to the CPU to make a decision.
CUDA device graph launch solves this problem by enabling a task graph to be performantly launched from a running GPU kernel, based on data that is determined at run time. To enable a wide range of applications and use, CUDA device graph launch offers two distinct launch modes:
- Fire-and-forget launch
- Tail launch
This post demonstrates how to use device graph launch and the two launch modes. It features the example of a device-side work scheduler, which decompresses files for data processing.
Device graph initialization
Executing a task graph involves the following process:
- Create the graph.
- Instantiate the graph into an executable graph.
- Upload the executable graph’s work descriptors to the GPU.
- Launch the executable graph.
By separating the launch step from the other steps, CUDA can optimize the workflow and keep the graph launch as lightweight as possible. As a convenience, CUDA also combines the upload step with the launch step the first time a graph is launched, if the upload step has not been called explicitly.
To launch a graph from a CUDA kernel, the graph first must have been initialized for device launch during the instantiation step. Before it can be launched from the device, the device graph must also have been uploaded to the device, either explicitly through a manual upload step or implicitly through a host launch. The following code example, which performs the host-side steps to set up the device scheduler example, shows both options:
// This is the signature of our scheduler kernel
// The internals of this kernel will be outlined later
__global__ void schedulerKernel(
fileData *files,
int numFiles,
int *currentFile,
void **currentFileData,
cudaGraphExec_t zipGraph,
cudaGraphExec_t lzwGraph,
cudaGraphExec_t deflateGraph);
void setupAndLaunchScheduler() {
cudaGraph_t zipGraph, lzwGraph, deflateGraph, schedulerGraph;
cudaGraphExec_t zipExec, lzwExec, deflateExec, schedulerExec;
// Create the source graphs for each possible operation we want to perform
// We pass the currentFileData ptr to this setup, as this ptr is how the scheduler will
// indicate which file to decompress
create_zip_graph(&zipGraph, currentFileData);
create_lzw_graph(&lzwGraph, currentFileData);
create_deflate_graph(&deflateGraph, currentFileData);
// Instantiate the graphs for these operations and explicitly upload
cudaGraphInstantiate(&zipExec, zipGraph, cudaGraphInstantiateFlagDeviceLaunch);
cudaGraphUpload(zipExec, stream);
cudaGraphInstantiate(&lzwExec, lzwGraph, cudaGraphInstantiateFlagDeviceLaunch);
cudaGraphUpload(lzwExec, stream);
cudaGraphInstantiate(&deflateExec, deflateGraph, cudaGraphInstantiateFlagDeviceLaunch);
cudaGraphUpload(deflateExec, stream);
// Create and instantiate the scheduler graph
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
schedulerKernel<<<1, 1, 0, stream>>>(files, numFiles, currentFile, currentFileData, zipExec, lzwExec, deflateExec);
cudaStreamEndCapture(stream, &schedulerGraph);
cudaGraphInstantiate(&schedulerExec, schedulerGraph, cudaGraphInstantiateFlagDeviceLaunch);
// Launch the scheduler graph - this will perform an implicit upload
cudaGraphLaunch(schedulerExec, stream);
}
Device graphs can be launched either from the host or from the device. The same cudaGraphExec_t handles may be passed to the scheduler for launch on the device as for launch on the host.
Fire-and-forget launch
A scheduler kernel dispatches work based on incoming data. When a graph is launched using fire-and-forget launch, it is dispatched immediately. It executes independently of both the launching graph and subsequent graphs launched using fire-and-forget mode. Because the work executes immediately, a fire-and-forget launch is preferable for work dispatched by a scheduler, as it starts running as quickly as possible.
CUDA introduces a new device-side named stream to perform a fire-and-forget launch of a graph. The following code example shows a simple dispatcher.
enum compressionType {
zip = 1,
lzw = 2,
deflate = 3
};
struct fileData {
compressionType comprType;
void *data;
};
__global__ void schedulerKernel(
fileData *files,
int numFiles
int *currentFile,
void **currentFileData,
cudaGraphExec_t zipGraph,
cudaGraphExec_t lzwGraph,
cudaGraphExec_t deflateGraph)
{
// Set the data ptr to the current file so the dispatched graph
// is operating on the correct file data
*currentFileData = files[*currentFile].data;
switch (files[*currentFile].comprType) {
case zip:
cudaGraphLaunch(zipGraph, cudaStreamGraphFireAndForget);
break;
case lzw:
cudaGraphLaunch(lzwGraph, cudaStreamGraphFireAndForget);
break;
case deflate:
cudaGraphLaunch(deflateGraph, cudaStreamGraphFireAndForget);
break;
default:
break;
}
}
Graph launches can also be nested and recursive, so more device graphs can be dispatched from fire-and-forget launches. Although not shown in this example, the graphs that are decompressing the file data could dispatch more graphs to do further processing on that data after it is fully decompressed (image processing, for example). Device graph flow is hierarchical, just like the graphs themselves.
Tail launch
CUDA work is launched asynchronously to the GPU, which means that the launching thread must explicitly wait for the work to complete before consuming any result or output. This is typically done from a CPU thread using a synchronization operation such as cudaDeviceSynchronize or cudaStreamSynchronize.
It is not possible for a launching thread on the GPU to synchronize on device graph launches through traditional methods such as cudaDeviceSynchronize. When you need operation ordering, use the tail launch.
When a graph is submitted for tail launch, it executes only after the completion of the launching graph. CUDA encapsulates all dynamically generated work as part of the parent graph, so a tail launch also waits for all generated fire-and-forget launches before executing. This is true whether the tail launch was issued before or after any fire-and-forget launches.
Tail launches themselves execute in the order in which they are enqueued. A special case is self-relaunch, where the currently running device graph is enqueued to relaunch through tail launch. Only one pending self-relaunch is permitted at a time.
Using tail launch, you can upgrade the previous dispatcher to become a full scheduler kernel by having it relaunch itself repeatedly, effectively creating a loop in the execution flow.
__global__ void schedulerKernel(
fileData *files,
int numFiles,
int *currentFile,
void **currentFileData,
cudaGraphExec_t zipGraph,
cudaGraphExec_t lzwGraph,
cudaGraphExec_t deflateGraph)
{
// Set the data ptr to the current file so the dispatched graph
// is operating on the correct file data
*currentFileData = files[*currentFile].data;
switch (files[*currentFile].comprType) {
case zip:
cudaGraphLaunch(zipGraph, cudaStreamGraphFireAndForget);
break;
case lzw:
cudaGraphLaunch(lzwGraph, cudaStreamGraphFireAndForget);
break;
case deflate:
cudaGraphLaunch(deflateGraph, cudaStreamGraphFireAndForget);
break;
default:
break;
}
// If we have not finished iterating over all the files, relaunch
(*currentFile)++;
if (*currentFile < numFiles) {
// Query the current graph handle so we can relaunch it
cudaGraphExec_t currentGraph = cudaGetCurrentGraphExec();
cudaGraphLaunch(currentGraph, cudaStreamGraphTailLaunch);
}
}
The relaunch operation uses cudaGetCurrentGraphExec to retrieve a handle to the currently executing graph. It can relaunch itself without needing a handle to its own executable graph.
The use of tail launch for the self-relaunch has the added effect of synchronizing on or waiting for the dispatched fire-and-forget launches before the next scheduler kernel relaunch begins. A device graph can only have one pending launch at a time, plus one self-relaunch.
To relaunch the graph that was just dispatched, make sure that the previous launch is completed first. Performing a self-relaunch accomplishes this goal so that you can dispatch whatever graph is needed for the next iteration.
Device compared to host launch performance
How would this example fare against a host-launched graph? Figure 1 compares fire-and-forget launch, tail launch, and host launch latencies for various topologies.
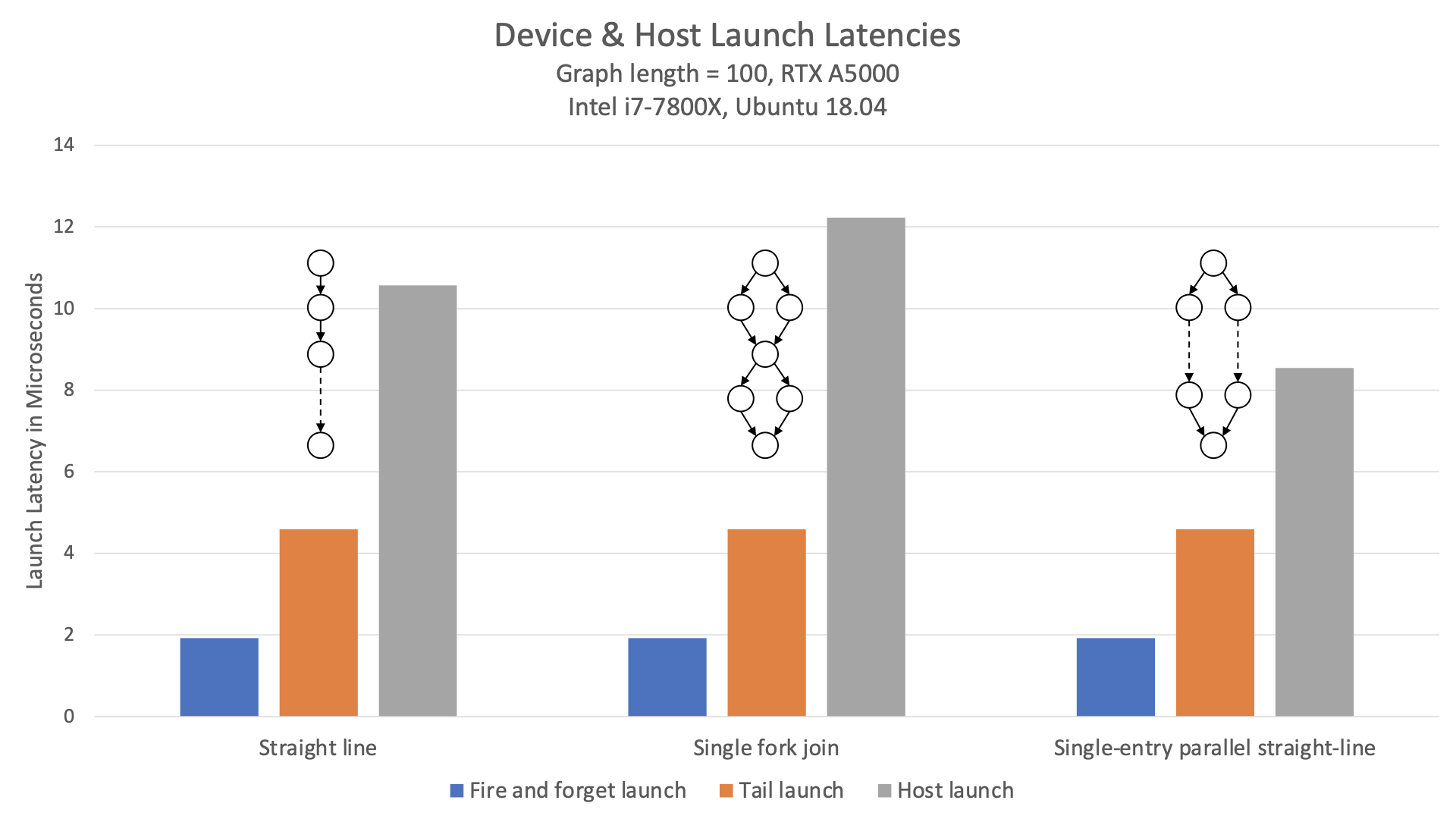
This chart shows that not only is the device-side launch latency better than 2x lower than that of the host launch, but it is also not impacted by graph structure. The latency is identical for each of the given topologies.
Device launch also scales much better to the width of the graph (Figure 2).
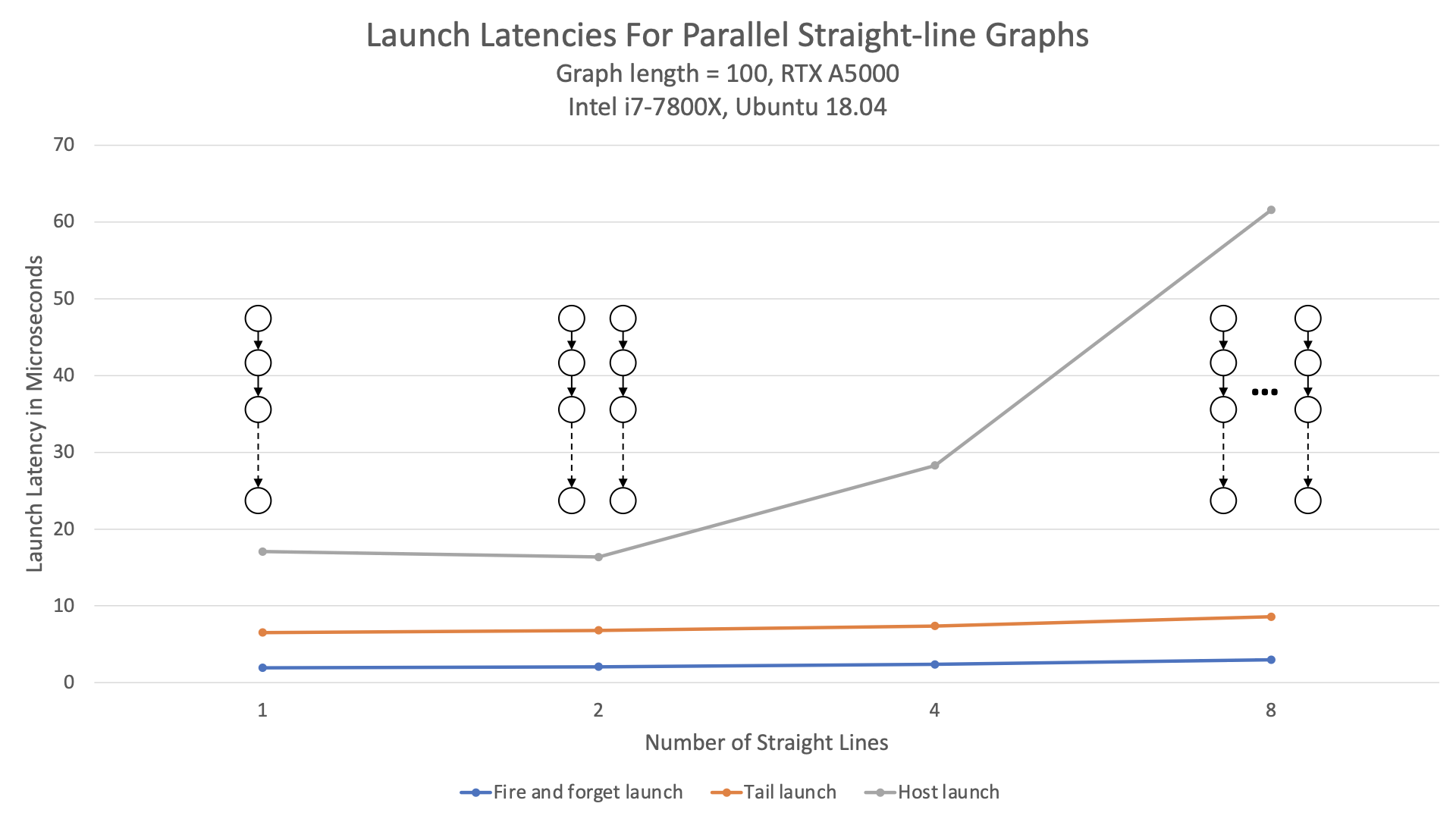
By comparison with host launch, device launch latency stays almost constant regardless of how much parallelism is in the graph.
Conclusion
CUDA device graph launch offers a performant way to enable dynamic control flow within CUDA kernels. While the example presented in this post provides a means of getting started with the feature, it is but a small representation of the ways this feature can be used.
For more information, see the Device Graph Launch section of the NVIDIA CUDA Programming Guide. To try the device graph launch, download CUDA Toolkit 12.0.
