Many workloads can be sped up greatly by offloading compute-intensive parts onto GPUs. In CUDA terms, this is known as launching kernels. When those kernels are many and of short duration, launch overhead sometimes becomes a problem.
One way of reducing that overhead is offered by CUDA Graphs. Graphs work because they combine arbitrary numbers of asynchronous CUDA API calls, including kernel launches, into a single operation that requires only a single launch. They do incur some overhead when they are created, so their greatest benefit comes from reusing them many times.
At their introduction in toolkit version 10, CUDA graphs could already be updated to reflect some minor changes in their instantiations. Coverage and efficiency of such update operations have since improved markedly. In this post, I describe some scenarios for improving performance of real-world applications by employing CUDA graphs, some including graph update functionality.
Context
Consider an application with a function that launches many short-running kernels, for example:
tight_loop(); //function containing many small kernels
If this function is executed identically each time it is encountered, it is easy to turn it into a CUDA graph using stream capture. You must introduce a switch—the Boolean captured, in this case—to signal whether a graph has already been created. Place the declaration and initialization of this switch in the source code such that its scope includes every invocation of function tight_loop.
cudaGraphExec_t instance; static bool captured = false;
Next, wrap any actual invocation of the function with code to create its corresponding CUDA graph, if it does not already exist, and subsequently launch the graph.
if (!captured)
{// you haven’t captured the graph yet
cudaGraph_t graph;
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
tight_loop(); //function containing many small kernels
//aggregate all info about the stream capture into “graph”
cudaStreamEndCapture(stream, &graph);
//turn this info into executable CUDA Graph “instance”
cudaGraphInstantiate(&instance, graph, NULL, NULL, 0);
//no need to hang on to the stream info
cudaGraphDestroy(graph);
captured = true;
}
cudaGraphLaunch(instance, stream);//launch the executable graph
The call to the tight_loop function does not actually execute any kernel launches or other CUDA operations. It merely records all such operations and stores them in a data structure.
Focus on the function launching the kernels. In the actual application, it looked like the following code:
void tight_loop(int first_step, MyStruct params, int delta, dim3 grid_dim, dim3 block_dim, cudaStream_t stream)
{
for (int step = first_step; step >= 0; --step, params.size -= delta)
{
tiny_kernel1<<<grid_dim, block_dim, 0, stream>>>(params);
tiny_kernel2<<<grid_dim, block_dim, 0, stream>>>(params);
}
}
Obviously, if the parameters of the function change upon successive invocations, the CUDA graph representing the GPU work inside should change as well. You can’t reuse the original graph. However, assuming that the same function parameter sets are encountered numerous times, you can handle this situation in at least a couple of different ways: Saving and recognizing graphs or updating graphs.
Save and recognize CUDA graphs
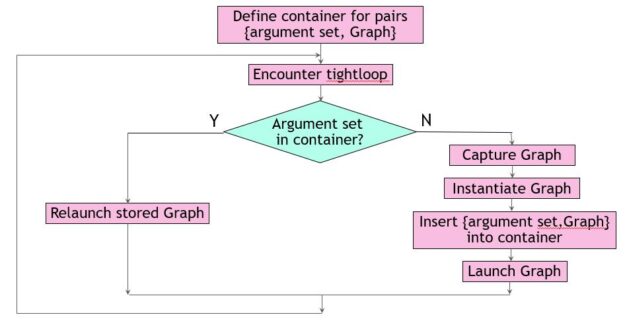
The first approach introduces a container from the C++ Standard Template Library to store parameter sets. Whenever you encounter a new parameter set uniquely defining function tight_loop, add it to the container, along with its corresponding executable graph.
When you encounter a parameter set already in the container, launch the corresponding CUDA graph. Assume that, in this case, the variables first, params.size, and delta uniquely define tight_loop. This triplet is the key used to distinguish graphs. You define it and the container to be used in the source code such that its scope includes every invocation of function tight_loop.
typedef struct
{ //define the fields of a key
int first;
double delta;
int size;
} Key;
//define the container (map) containing (key,value) pairs
map<Key, cudaGraphExec_t, cmpKeys> MapOfGraphs;
Wherever function tight_loop occurs, you wrap it with code that fills the key and looks it up in your container. If the key is found, the code launches the corresponding executable CUDA graph. Otherwise, it creates a new graph, adds it to the container, and then launches it (Figure 1).
Key triplet = {first_step, delta, params.size};
map<Key, cudaGraphExec_t, cmpKeys>::iterator it = MapOfGraphs.find(triplet);
if (it == MapOfGraphs.end())
{ // new parameters, so need to capture new graph
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
tight_loop(first_step, params, delta, grid_dim, block_dim, stream);
cudaStreamEndCapture(stream, &graph);
cudaGraphInstantiate(&instance, graph, NULL, NULL, 0);
cudaGraphDestroy(graph);
// add this graph to the container of saved graphs
MapOfGraphs.insert(make_pair(trio,instance));
cudaGraphLaunch(instance, stream);
}
else
{// recognized parameters, so can launch previously captured graph
cudaGraphLaunch(it->second, stream);
}
This method often works well but it has some inherent dangers. In this instance, you determined that only three parameters are needed to define keys in the container. That may be different for a different workload, or another development team member may silently add fields to structure MyStruct. This affects how the non-trivial function cmpKeys is written. This function is required by the container and is used to determine whether a certain key is smaller than another.
Writing a nontrivial comparison function for an STL container is usually not difficult but may be tedious when a key consists of multiple non-trivial entities. A generally applicable method is to use a lexicographical comparison. For this example, the following code example works:
struct cmpKeys {
bool operator()(const Key& a, const Key& b) const {
if (a.first != b.first) return(a.first < b.first);
else
{
if (a.delta != b.delta ) return (a.delta < b.delta);
else return(a.size < b.size);
}
}
}
Update CUDA graphs
Remember that to reuse a previously captured executable CUDA graph, it must match the invocation context exactly:
- Same topology
- Same number and type of graph nodes
- Same dependencies between graph nodes
- Same node parameters
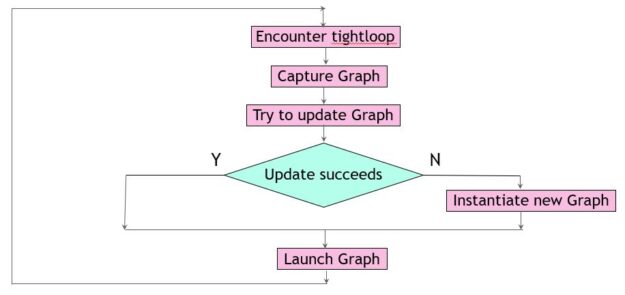
However, it is possible to tweak a CUDA graph to make it conform to new needs, if its topology remains unchanged. A convenient mechanism exists to confirm topological equivalence and at the same time adjust node parameters to return a modified executable graph. It is offered by cudaGraphExecUpdate, which works by comparing an existing executable graph with a newly derived graph (for example, conveniently obtained by stream capture). The difference is used to make changes, if possible.
The benefit of this approach is twofold. First, you can avoid an expensive instantiation of a new CUDA graph when an update suffices. Second, you don’t have to know what makes graphs unique. Any graph comparisons are carried out implicitly by the update function. The following code example implements this method. As before, it starts with declaration and initialization of a switch to indicate the prior creation of a graph.
static bool captured = false;
The invocation site of tight_loop is changed as follows:
cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal);
tight_loop(first_step, params, delta, grid_dim, block_dim, stream);
cudaStreamEndCapture(stream, &graph);
if (!captured) {
cudaGraphInstantiate(&instance, graph, NULL, NULL, 0);
captured = true;
} else {
// graph already exists; try to apply changes
if (cudaGraphExecUpdate(instance, graph, NULL, &update) != cudaSuccess)
{// only instantiate a new graph if update fails
cudaGraphExecDestroy(instance);
cudaGraphInstantiate(&instance, graph, NULL, NULL, 0)
{
}
cudaGraphDestroy(graph);
cudaGraphLaunch(instance, stream);
In this scenario, you always do a stream capture to collect information about the CUDA operations in tight_loop. This is a relatively inexpensive operation that is carried out entirely on the host, not the GPU. It can be overlapped with previous CUDA graph launches, which are themselves asynchronous operations (Figure 2).
A word of caution is in order. The complexity of cudaGraphExecUpdate is roughly proportional to the number of changes made to CUDA graph nodes, so it becomes less efficient if the bulk of the nodes change.
Results
The application that motivated these two approaches to manage CUDA graphs in flexible ways has two different workload sizes with somewhat different behaviors (Table 1). All kernels involved take 2–8 microseconds to execute on a single NVIDIA A100 GPU. Speedups reported are for the sections of the code that can be turned into CUDA graphs.
| Workload size | ||||
| Small | Large | |||
| Kernels per Graph | 504 | 2520 | ||
| Graph launches | 70 | 1540 | ||
| Method | Update | Recognize | Update | Recognize |
| Stream captures | 70 | 5 | 1540 | 3 |
| Graph updates | 69 | N.A | 1539 | N.A |
| Graph instantiations | 3 | 5 | 1 | 3 |
| Speedup | 16% | 19% | 26% | 24% |
Conclusion
Applications with many small CUDA kernels can often be accelerated using CUDA graphs, even if the pattern of kernel launches changes throughout the application. The best method depends on the specifics of your application, given such dynamic environments. Hopefully, you find the two examples described in this post to be easy to understand and implement.
