
Organizations of all kinds are incorporating AI into their research, development, product, and business processes. This helps them meet and exceed their particular goals, and also helps them gain experience and knowledge to take on even bigger challenges. However, traditional compute infrastructures aren’t suitable for AI due to slow CPU architectures and varying system requirements for different workloads and project phases. This drives up complexity, increases cost, and limits scale.
To help organizations overcome these challenges and succeed in a world that desperately needs the power of AI to solve big challenges, NVIDIA designed the world’s first family of systems purpose-built for AI—NVIDIA DGX systems. By leveraging powerful NVIDIA GPUs and optimized AI software from NVIDIA NGC, DGX systems deliver unprecedented performance and eliminate integration complexity.
Now, NVIDIA has introduced NVIDIA DGX A100. Built on the brand new NVIDIA A100 Tensor Core GPU, DGX A100 is the third generation of DGX systems and is the universal system for AI infrastructure. Featuring five petaFLOPS of AI performance, DGX A100 excels on all AI workloads: analytics, training, and inference. It allows organizations to standardize on a single system that can speed through any type of AI task at any time and dynamically adjust to changing compute needs over time. This unmatched flexibility reduces costs, increases scalability, and makes DGX A100 the foundational building block of the modern AI data center.
In this post, we look at the design and architecture of DGX A100.
System architecture

NVIDIA A100 GPU: Eighth-generation data center GPU for the age of elastic computing
At the core, the NVIDIA DGX A100 system leverages the NVIDIA A100 GPU, designed to efficiently accelerate large complex AI workloads as well as several small workloads, including enhancements and new features for increased performance over the V100 GPU. The A100 GPU incorporates 40 GB high-bandwidth HBM2 memory, larger and faster caches, and is designed to reduce AI and HPC software and programming complexity.

The NVIDIA A100 GPU includes the following new features to further accelerate AI workload and HPC application performance:
- Third-generation Tensor Cores
- Sparsity Acceleration
- Multi-Instance GPU
Third-generation Tensor Cores
The NVIDIA A100 GPU includes new third-generation Tensor Cores. Tensor Cores are specialized, high-performance, compute cores that perform mixed-precision matrix multiply and accumulate (MMA) calculations in a single operation, providing accelerated performance for AI workloads and HPC applications.
The first-generation Tensor Cores used in the NVIDIA DGX-1 with V100 provided accelerated performance with mixed-precision MMA in FP16 and FP32. This latest generation in the DGX A100 uses larger matrix sizes, improving efficiency and providing twice the performance of the V100 Tensor Cores along with improved performance for INT4 and binary data types. The A100 Tensor Core GPU also adds the following new data types:
- TF32
- IEEE Compliant FP64
- BF16 (BF16/FP32 mixed-precision Tensor Core operations perform at the same speed as FP16/FP32 mixed-precision Tensor Core operations, providing another choice for deep learning training)
Structured sparsity
Sparsity is a relatively new approach to neural networks, and promises to increase the capacity of deep neural network models by reducing the number of required connections in a network and by conserving resources. With the NVIDIA A100 GPU, NVIDIA positions itself at the forefront of this effort by incorporating structured sparsity.
With structured sparsity, each node in a sparse network performs the same amount of data fetches and computations, and results in balanced workload distribution and better utilization of compute nodes. Additionally, sparsity is used to perform matrix compression which provides benefits such as doubling multiply-accumulate operations.
The result is accelerated Tensor Core computation across a variety of AI networks, and increased throughput of FP training as well as inference training.
- INT8 on A100 offers 20X more performance than INT8 on V100.
- TF32 Tensor Core operations on A100 offer 20X more performance than standard FP32 FFMA operations on V100.
- IEEE Compliant FP64 Tensor Core operations on A100 provide 2.5X more performance than standard FP64 operations on V100 for HPC applications.
Multi-Instance GPU
The NVIDIA A100 GPU incorporates the new Multi-Instance GPU (MIG) feature. MIG uses spatial partitioning to carve the physical resources of a single A100 GPU into as many as seven independent GPU instances. With MIG, the NVIDIA A100 GPU can deliver guaranteed quality of service at up to 7x higher throughput than V100 with simultaneous instances per GPU.
On an NVIDIA A100 GPU with MIG enabled, parallel compute workloads can access isolated GPU memory and physical GPU resources as each GPU instance has its own memory, cache, and streaming multiprocessor. This allows multiple users to share the same GPU and run all instances simultaneously, maximizing GPU efficiency.
MIG can be enabled selectively on any number of GPUs in the DGX A100 system—not all GPUs need to be MIG-enabled. However, if all GPUs in a DGX A100 system are MIG-enabled, up to 56 users can simultaneously and independently take advantage of GPU acceleration.
Typical uses cases that can benefit from MIG are as follows:
- Multiple inference jobs with batch sizes of one that involve small, low-latency models and which don’t require all the performance of a full GPU
- Jupyter notebooks for model exploration
- Single-tenant multi-user and other shared resource usage
Taking it further on DGX A100 with 8xA100 GPUs, you can configure different GPUs for vastly different workloads, as shown in the following example:
- 4xGPUs for AI training
- 2xGPUs for HPC or data analytics
- 2xGPUs in MIG mode, partitioned into 14-MIG instances, each one running inference

Third-generation NVLink and NVSwitch to accelerate large complex workloads
The DGX A100 system contains six second-generation NVIDIA NVSwitch fabrics that interconnect the A100 GPUs using third-generation NVIDIA NVLink high-speed interconnects. Each A100 GPU uses twelve NVLink interconnects to communicate with all six NVSwitch nodes, which means that there are two links from each GPU to each switch. This provides a maximum amount of bandwidth to communicate across GPUs over the links.
The second-generation NVSwitch is two times faster than the previous version, which was first introduced in NVIDIA DGX-2 system. The combination of six NVSwitch and third-generation NVLink interconnects enables individual GPU-to-GPU communication to peak at 600 GB/s, which means that if all GPUs are communicating with each other, the total amount of data transferred peaks at 4.8 TB/s for both directions.

Highest networking throughput with Mellanox ConnectX-6
Multi-system scaling of AI deep learning and HPC computational workloads requires strong communications between GPUs in multiple systems to match the significant GPU performance of each system. In addition to NVLink for high speed communication internally between GPUs, the DGX A100 server is configured with eight single-port Mellanox ConnectX-6 200Gb/s HDR InfiniBand ports (also configurable as 200-Gb/s Ethernet ports) that can be used to build a high-speed cluster of DGX A100 systems.
The most common methods of moving data to and from the GPU involve leveraging the on-board storage and using the Mellanox ConnectX-6 network adapters through remote direct memory access (RDMA). The DGX A100 incorporates a one-to-one relationship between the I/O cards and the GPUs, which means each GPU can communicate directly with external sources without blocking other GPU access to the network.
The Mellanox ConnectX-6 I/O cards offer flexible connectivity as they can be configured as HDR Infiniband or 200-Gb/s Ethernet. This allows the NVIDIA DGX A100 to be clustered with other nodes to run HPC and AI workloads using low latency, high bandwidth InfiniBand, or RDMA over Converged Ethernet (RoCE).
The DGX A100 GPU includes an additional dual-port ConnectX-6 card that can be used for high-speed connection to external storage. The flexibility in I/O configuration also allows connectivity to a variety of high speed networked storage options.

The ConnectX-6 VPI cards in the DGX A100 server provide the following:
- 200 Gb/s per port (four data lanes operating at 50 Gb/s or 200 Gb/s total)
- Both IBTA RDMA and RoCE technologies
- Low-latency communication and built-in primitives and collectives to accelerate large computations across multiple systems
- High-performance network topology support to enable data transfer between multiple systems simultaneously with minimal contention
- NVIDIA GPUDirect RDMA across InfiniBand for direct transfers between GPUs in multiple systems
The latest DGX A100 multi-system clusters use a network based on a fat tree topology using advanced Mellanox adaptive routing and Sharp collective technologies to provide well-routed, predictable, contention-free communication from each system to every other system.
A fat tree is a tree-structured network topology with systems at the leaves that connect up through multiple switch levels to a central top-level switch. Each level in a fat tree has the same number of links providing equal non-blocking bandwidth. The fat tree topology ensures the highest communication bisection bandwidth and lowest latency for all-to-all or all-gather type collectives that are common in computational and deep learning applications.
With the fastest I/O architecture of any DGX system, NVIDIA DGX A100 is the foundational building block for large AI clusters such as NVIDIA DGX SuperPOD, the enterprise blueprint for scalable AI infrastructure.
First accelerated system with all PCIe Gen4
The NVIDIA A100 GPUs are connected to the PCI switch infrastructure over x16 PCI Express Gen 4 (PCIe Gen4) buses that provide 31.5 GB/s each for a total of 252 GB/s, doubling the bandwidth of PCIe 3.0/3.1. These are the links that provide access to the Mellanox ConnectX-6, NVMe storage, and CPUs.
Training workloads commonly involve reading the same datasets many times to improve accuracy. Rather than use up all the network bandwidth to transfer this data over and over, high performance local storage is implemented with NVMe drives to cache this data. This increases the speed at which the data is read into memory, and it also reduces network and storage system congestion.
Each DGX A100 system comes with dual 1.92 TB NVMe M.2 boot OS SSDs configured in a RAID 1 volume, and four 3.84 TB PCIe gen4 NVMe U.2 cache SSDs configured in a RAID 0 volume. The base RAID 0 volume has a total capacity of 15 TB, but an additional 4 SSDs can be added to the system for a total capacity of 30 TB. These drives use CacheFS to increase the speed at which workloads access data and to reduce network data transfers.
The DGX A100 system includes two CPUs for boot, storage management, and deep learning framework coordination. Each CPU runs at up to 3.4 GHz, has 64 cores with two threads per core and offers 128 PCIe Gen4 links used for I/O and inter-socket communication. The system is configured with 1 TB of base memory and is upgradable to 2 TB.
Similar to previous DGX systems, DGX A100 is designed to be air-cooled in a data center with operating temperature ranging from 5oC – 30oC.
Fully optimized DGX software stack
The DGX A100 software has been built to run AI workloads at scale. A key goal is to enable practitioners to deploy deep learning frameworks, data analytics, and HPC applications on the DGX A100 with minimal setup effort. The design of the platform software is centered around a minimal OS and driver install on the server, and provisioning of all application and SDK software available through the NGC Private Registry.
The NGC Private Registry provides GPU-optimized containers for deep learning, machine learning, and high performance computing (HPC) applications, along with pretrained models, model scripts, Helm charts, and SDKs. This software has been developed, tested, and tuned on DGX systems, and is compatible with all DGX products: DGX-1, DGX-2, DGX Station, and DGX A100.
The NGC Private Registry also provides a secure space for storing custom containers, models, model scripts, and Helm charts that can be shared with others within the enterprise. For more information, see Securing and Accelerating End-to-End AI Workflows with the NGC Private Registry.
Figure 6 shows how all these pieces fit together as part of the DGX software stack.
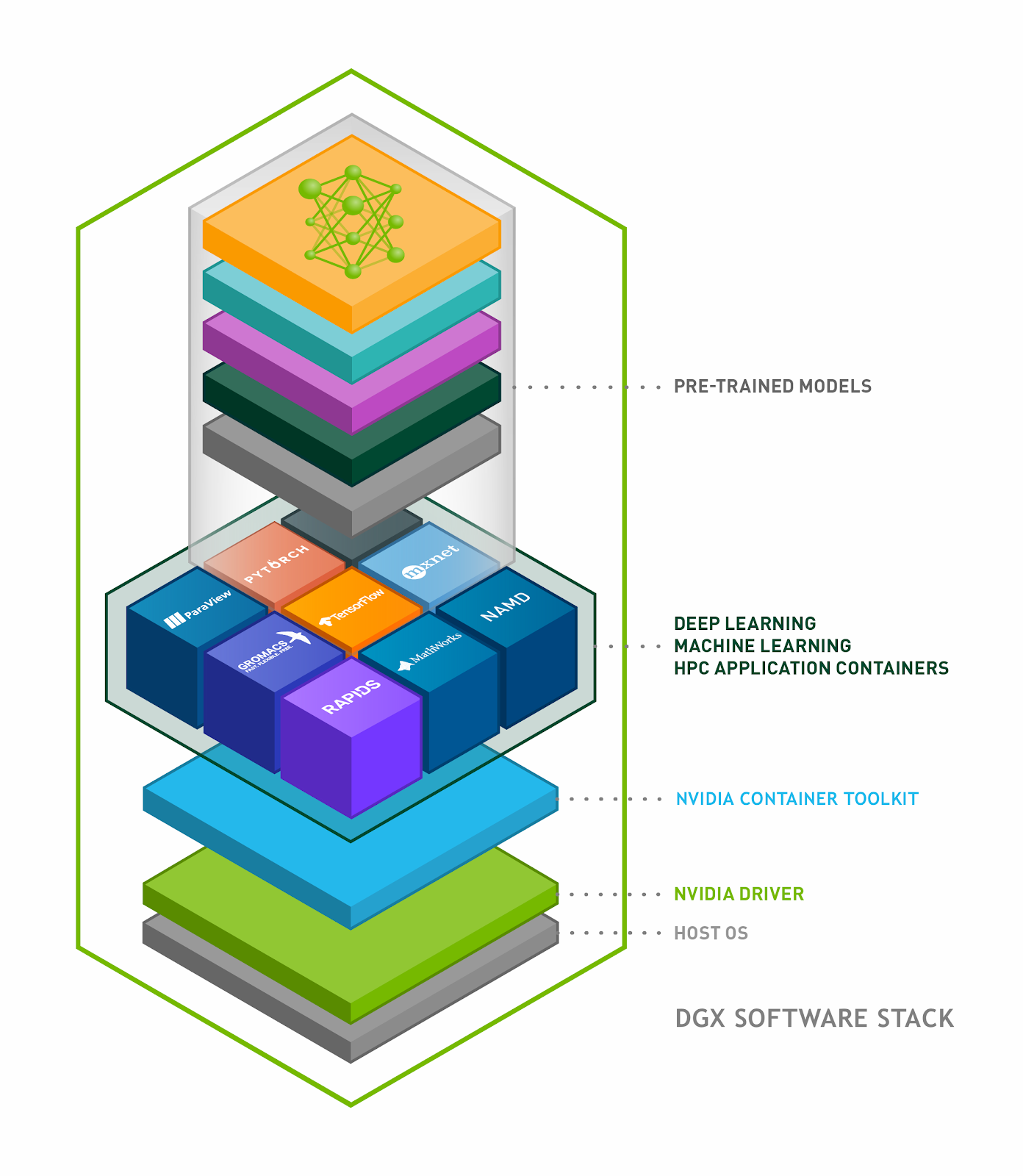
The DGX software stack includes the following major components:
- The NVIDIA Container Toolkit allows you to build and run GPU accelerated Docker containers. The toolkit includes a container runtime library and utilities to automatically configure containers and leverage NVIDIA GPUs.
- GPU-accelerated containers feature software to support the following:
- Deep learning frameworks for training, such as PyTorch, MXNet, and TensorFlow
- Inference platforms, such as TensorRT
- Data analytics, such as RAPIDS, the suite of software libraries for executing end-to-end data science and analytics pipelines entirely on GPUs.
- High performance computing (HPC), such as CUDA-X HPC, OpenACC, and CUDA.
- The NVIDIA CUDA Toolkit, incorporated within each GPU-accelerated container, is the development environment for creating high performance GPU-accelerated applications. CUDA 11 enables software developers and DevOps engineers to reap the benefits of the major innovations in the new NVIDIA A100 GPU, including the following:
- Support for new input data type formats, Tensor Cores, and performance optimizations in CUDA libraries for linear algebra, FFTs, and matrix multiplication
- Configuration and management of MIG instances on Linux operating systems, part of the DGX Software stack
- Programming and APIs for task graphs, asynchronous data movement, fine-grained synchronization, and L2 cache residency control
For more information, see CUDA 11 Features Revealed.
Game-changing performance
Packed with innovative features and a balanced system design, the DGX A100 delivers unprecedented performance in deep learning training and inference. The graph in Figure 7 demonstrates the following performance results:
- DGX A100 delivers 6x the training performance of an 8xV100 GPU system, such as DGX-1. DGX A100 using TF32 precision achieves 1289 sequences per second compared to 216 sequences per second on DGX-1 using FP32.
- DGX A100 offers inference performance that is 172x the performance of a CPU server. DGX A100 using INT8 with structural sparsity achieves inference peak compute of 10 PetaOPS, where a Peta equals to 1000 trillions, compared to 58 trillion operations per second (TOPS) on 2x Intel Platinum 8280 CPU server using INT8.
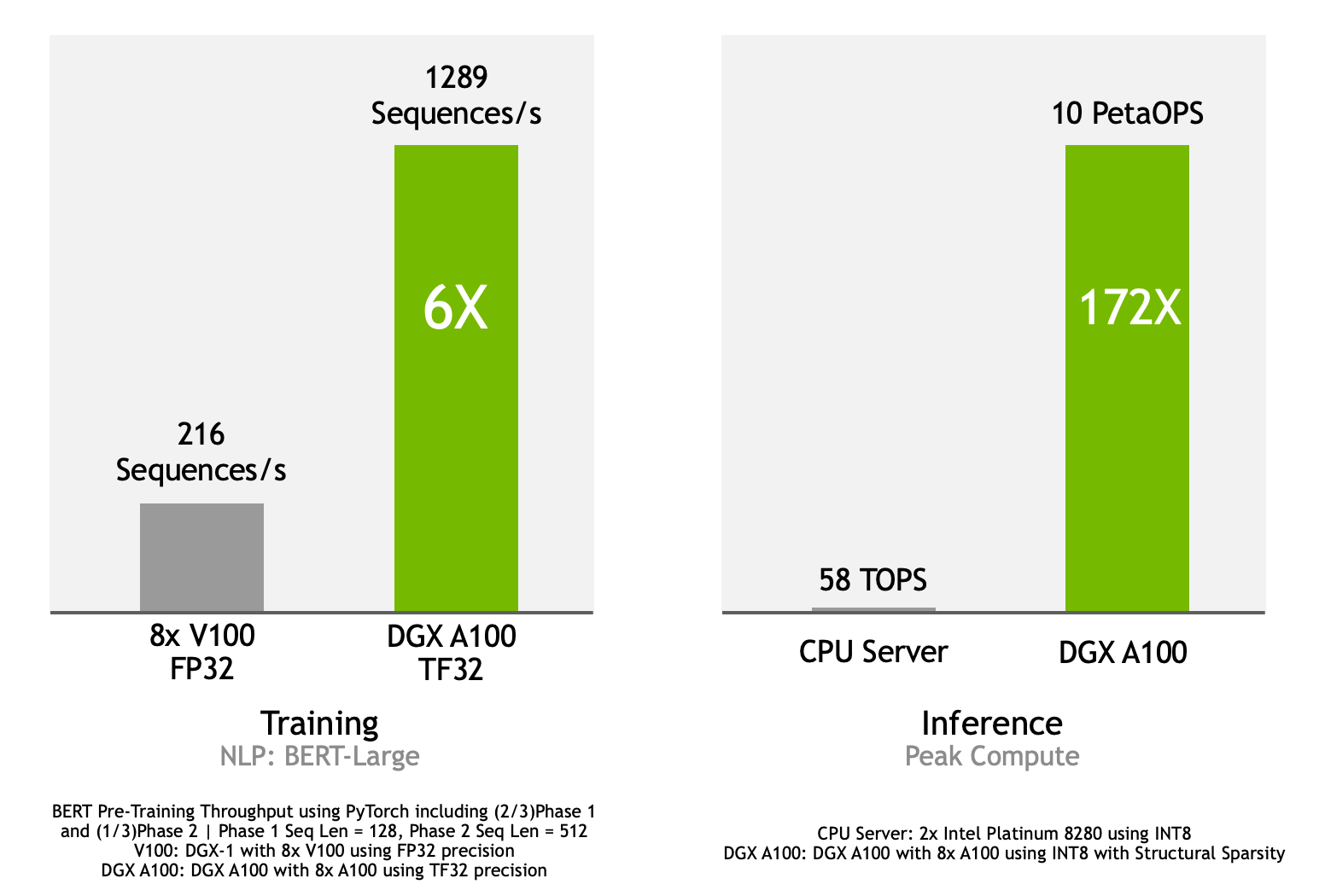
Here are details on the benchmarks.
Training:
- DGX A100 system with 8xNVIDIA A100 GPUs, TF32 precision vs. DGX-1 system with 8xNVIDIA V100 GPUs, FP32 precision.
- Deep learning language model: the large version of one of the world’s most advanced AI language models, Bidirectional Encoder Representations from Transformers (BERT) on the popular PyTorch framework.
- Pretraining throughput using PyTorch including (2/3) Phase 1 and (1/3) Phase 2 | Phase 1 Sequence Length = 128, Phase 2 Sequence Length = 512.
Inference:
- DGX A100 system with 8xNVIDIA A100 GPUs using INT8 with Structural Sparsity vs. a CPU server with 2xIntel Platinum 8280 using INT8.
The combination of the groundbreaking A100 GPUs with massive computing power and high-bandwidth access to large DRAM, and fast interconnect technologies, makes the NVIDIA DGX A100 system optimal for dramatically accelerating complex networks like BERT.
A single DGX A100 system features five petaFLOPs of AI computing capability to process complex models. The large model size of BERT requires a huge amount of memory, and each DGX A100 provides 320 GB of high bandwidth GPU memory. NVIDIA interconnect technologies like NVLink, NVSwitch, and Mellanox networking bring all GPUs together to work as one on large AI models with high-bandwidth communication for efficient scaling.
With Tensor Core acceleration of INT8 and structural sparsity in NVIDIA A100 GPU, the DGX A100 sets a new bar for inference workloads. Using the MIG capability in A100 GPU, you can assign resources that are right-sized for specific workloads.
Direct access to NVIDIA DGXperts
NVIDIA DGXperts are a global team of over 14,000 AI-fluent professionals who have gained the experience of thousands of DGX system deployments and who have expertise in full-stack AI development. Their skill set includes system design and planning, data center design, workload testing, job scheduling, resource management, and ongoing optimizations.
Owning an NVIDIA DGX A100 or any other DGX system gives you direct access to these experts. NVIDIA DGXperts complement your in-house AI expertise and let you combine an enterprise-grade platform with augmented AI-fluent talent to achieve your organization’s AI project goals.
Summary
The innovations in DGX A100 make it possible for developers, researchers, IT managers, business leaders, and more to push the boundaries of what’s possible and realize the full benefits of AI in their projects and across their organizations. DGX A100 is available now.
To learn more, visit:
- NVIDIA DGX A100 webpage
- NVIDIA DGX A100 data sheet
- NVIDIA Ampere Architecture In-depth post
Join a live GTC 2020 webinar on May 20, 2020 at 9AM Pacific Time where NVIDIA’s Charlie Boyle, VP/GM DGX Systems, Christopher Lamb, Vice President, Compute Software, and Rajeev Jayavant, Vice President, GPU Systems Engineering, will discuss NVIDIA DGX A100.
