
CUDA Toolkit 12.0 introduces a new nvJitLink library for Just-in-Time Link Time Optimization (JIT LTO) support. In the early days of CUDA, to get maximum performance, developers had to build and compile CUDA kernels as a single source file in whole programming mode. This limited SDKs and applications with large swaths of code, spanning multiple files that required separate compilation from porting to CUDA. The performance gain was not on par with whole program compilation.
With the CUDA Toolkit 11.2 release, NVCC added support for Offline Link Time Optimization (LTO) to enable separately compiled applications and libraries to gain similar GPU runtime performance as a fully optimized program compiled from a single translation unit. In some cases, the performance gain was reported to be ~20% or higher. To learn more, see Improving GPU Application Performance with NVIDIA CUDA 11.2 Device Link Time Optimization.
In the paper, Enhancements Supporting IC Usage of PEM Libraries on Next-Gen Platforms, Lawrence Livermore National Laboratory reported the performance improvement thus obtained through offline LTO “provided speedups in all cases; the maximum speedup was 27.1%.”
CUDA Toolkit 12.0 expands LTO support further with the official introduction of JIT LTO. This extends the same performance benefits LTO provides to applications using runtime linking.
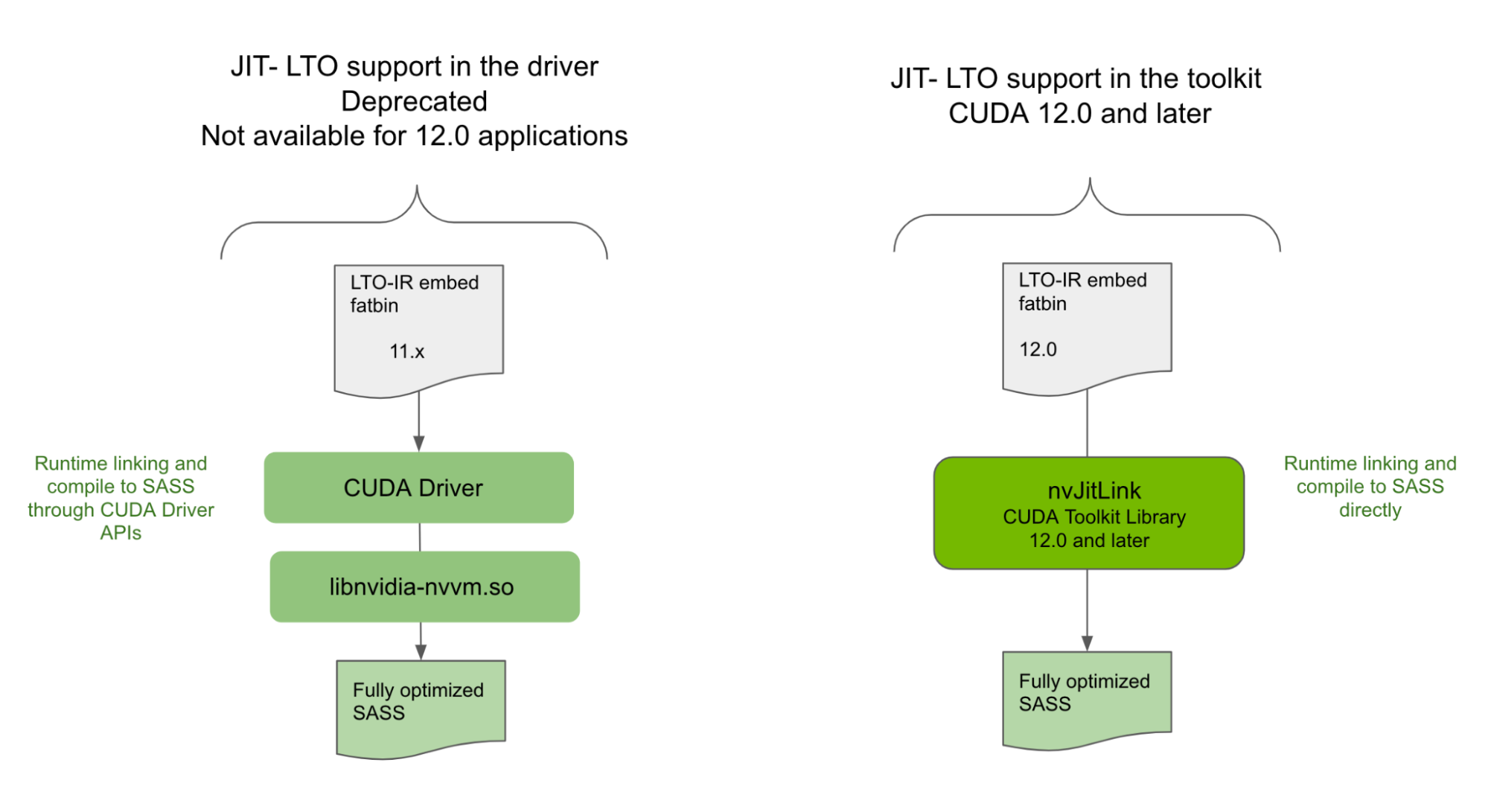
Deprecation of JIT LTO support in the driver
While JIT LTO was introduced in CUDA 11.4, that version of JIT LTO was through the cuLink APIs in the CUDA driver. It also relied on using a separate optimizer library shipped with the CUDA driver for performing link time optimizations at runtime. Due to dependency on the CUDA driver, JIT LTO as released in 11.4 did not provide the minor version compatibility, and in some cases backward compatibility guarantees of CUDA.
As a result, we had to rethink our design, taking into consideration the various deployment scenarios in which CUDA could be used and the different use models of libraries and standalone applications at large.
NVIDIA is deprecating the JIT LTO feature as exposed in the CUDA driver and introducing it as a CUDA Toolkit feature for CUDA 12.0 and later applications. For more details, see the deprecation notice in the CUDA 12.0 Release Notes.
New library offers JIT LTO support
In CUDA Toolkit 12.0, you will find a new library, nvJitLink, with APIs to support JIT LTO during runtime linking. The usage of nvJitLink library is similar to that of any of the other familiar libraries such as nvrtc and nvptxcompiler. Add the link time option -lnvJitLink to your build options. There will be static and dynamic versions of the nvJitLink library for Linux, Windows and Linux4Tegra platforms that will be shipped with the CUDA Toolkit.
With proper considerations, JIT LTO exposed through nvJitLink library will comply with CUDA compatibility guarantees. This post primarily covers JIT LTO capabilities as available through nvJitLink library highlighting differences with earlier drive-based implementation as and when appropriate. We dive into the details of the feature with code samples, the compatibility guarantees, and benefits. As an added bonus, we also include a sneak peek of how and why NVIDIA math library plans to leverage the feature.
How to get JIT LTO working
Follow the three main steps outlined below for runtime LTO.
1. Create the linker handle that will be referenced later to link relevant objects together. You will want to pass -lto as one of the options.
nvJitLinkCreate (&handle, numOptions, options)2. Add objects to be linked together with either of the following scripts:
nvJitLinkAddFile (handle, inputKind, fileName);nvJitLinkAddData (handle, inputKind, data, size, name);Input kinds generally can be ELF, PTX, fatbinary, host object, and host library. For JIT LTO, the input kind is LTOIR or a format that includes LTOIR, such as fatbinary.
3. Perform actual linking using the script below:
nvJitLinkComplete (handle);You may also retrieve the resulting linked cubin. In order to do that, explicit buffer allocation is needed. So, you can query the size of the buffer and use that buffer to fetch the linked cubin. For example:
nvJitLinkGetLinkedCubinSize (handle, &size);
void *cubin = malloc(size);
nvJitLinkGetLinkedCubin(handle, cubin);LTO-IR as target format
JIT LTO is performed on the intermediate representation format based on LLVM: LTO-IR. This intermediate representation is the same as what is generated by NVCC and consumed by the nvlink device linker in Offline LTO (CUDA 11.2). The input for runtime linking for JIT LTO needs to be either in the LTO-IR format or have LTO-IR embedded in an encompassing format. LTO-IR can be stored inside a fatbinary, for example.
There are two ways to generate LTO-IR for input to the nvJitLink library, as shown in Figure 2.
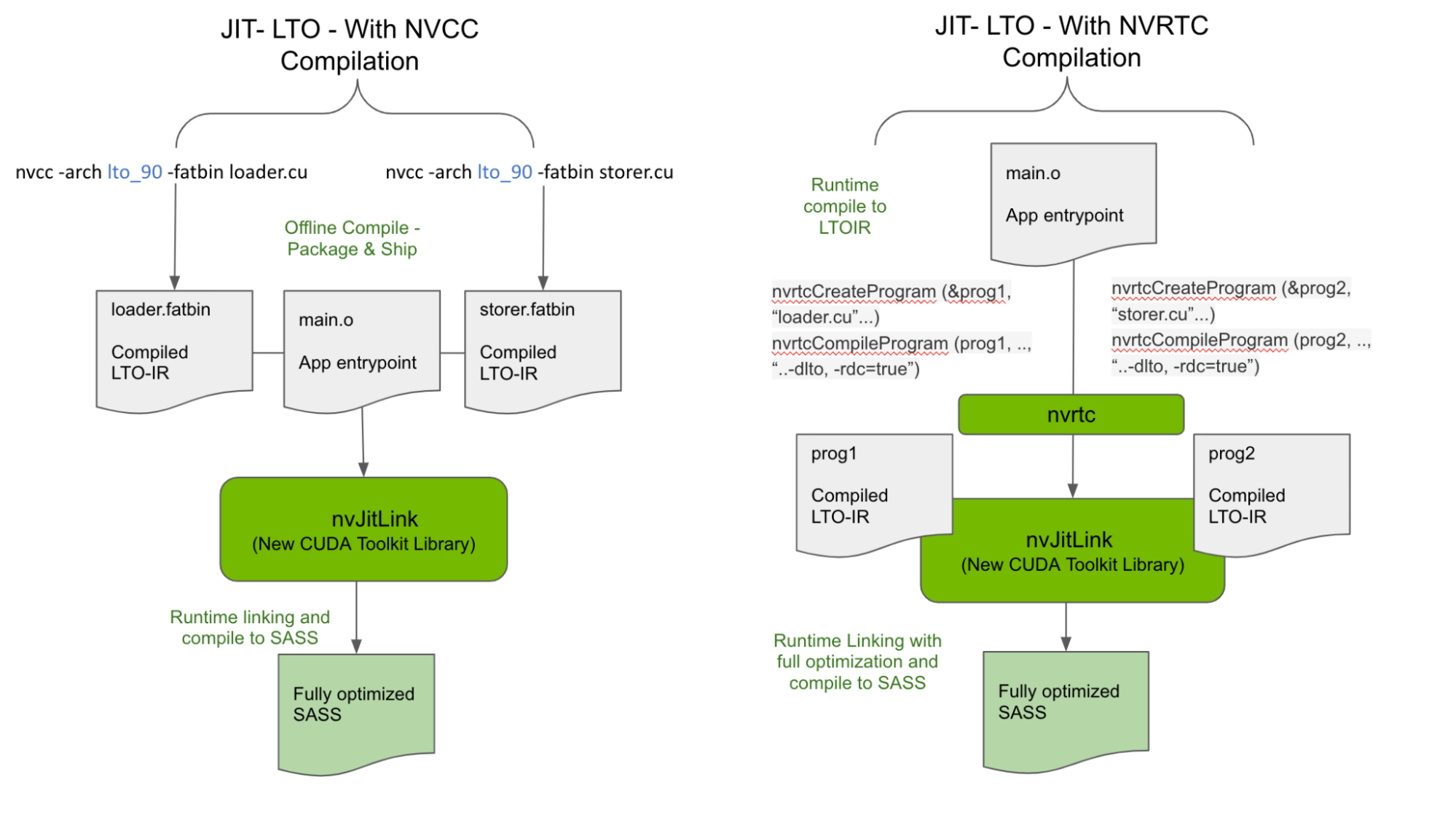
Generate LTO-IR offline with NVCC
CUDA 11.2 introduced the LTO-IR format and how it can be generated with NVCC using the -dlto build option. We are retaining this capability as one of the accepted forms of input for valid linking of LTO-IR objects at runtime. As a result, offline generated LTO-IR objects stored in a fatbinary such as the loader.fatbin and storer.fatbin generated below can be linked at runtime to avail the maximizing performance benefits of LTO.
nvcc -arch lto_90 -fatbin loader.cu // stores LTO-IR inside a fatbinary
nvcc -arch lto_90 -fatbin storer.cuApplications and libraries could, therefore, ship independent LTO-IR fragments instead of SASS or PTX to be linked with optimizations performed at runtime across multiple LTO-IR fragments. Note that careful consideration of the nvJitLink library version on the target is needed when shipping LTO-IR.
char smbuf[16];
memset(smbuf,0,16);
sprintf(smbuf, "-arch=sm_%d", arch)
// Load the generated LTO IR and link them together
nvJitLinkHandle handle;
const char *lopts[] = {"-lto", smbuf};
nvJitLinkCreate (&handle, 2, lopts)
nvJitLinkAddFile (handle, NVJITLINK_INPUT_FATBIN, loader.fatbin);
nvJitLinkAddFile (handle, NVJITLINK_INPUT_FATBIN, storer.fatbin);
nvJitLinkComplete (handle);This possibility opens new ways to reduce binary size significantly by composing kernels at runtime without compromising performance. For example, fragments of user and library kernels can be shipped separately in LTO-IR format and JIT linked and compiled to a single kernel at runtime appropriate for the target config. Since linking of fragments and optimizations happen at runtime, optimization techniques are applied across user and library code, maximizing performance.
Generate LTO-IR at runtime
In addition to the offline compile – runtime linking model described above and shown in Figure 2, LTO-IR objects can also be entirely constructed at runtime using NVRTC by passing -dlto at compile time and linked at runtime using the nvJitLinkAddData API. Sample code from CUDA samples is shown below, with relevant modifications for using nvJitLink APIs.
nvrtcProgram prog1, prog2;
char *ltoIR1, *ltoIR2
...
...
/* Compile using –dlto option */
const char* opts = (“--gpu-architecture=compute_80”, “--dlto”, "--relocatable-device-code=true"});
NVRTC_SAFE_CALL(nvrtcCompileProgram(&prog1, 3, opts);
NVRTC_SAFE_CALL(nvrtcCompileProgram(&prog2, 3, opts);
...
nvrtcGetLTOIRSize(prog1, <oIR1Size);
ltoIR1 = malloc(ltoIR1Size);
nvrtcGetLTOIRSize(prog2, <oIR2Size);
ltoIR2 = malloc(ltoIR2Size);
nvrtcGetLTOIR(prog1, ltoIR1);
nvrtcGetLTOIR(prog2, ltoIR2);
char smbuf[16];
memset(smbuf,0,16);
sprintf(smbuf, "-arch=sm_%d", arch)
// Load the generated LTO IR and link them together
nvJitLinkHandle handle;
const char *lopts[] = {"-lto", smbuf};
nvJitLinkCreate(&handle, 2, lopts);
nvJitLinkAddData(handle, NVJITLINK_INPUT_LTOIR,
(void *)ltoIR1, ltoIR1Size, "lto_saxpy");
nvJitLinkAddData(handle, NVJITLINK_INPUT_LTOIR,
(void *)ltoIR2, ltoIR2Size,"lto_compute");
// Call to nvJitLinkComplete causes linker to link together the
// two LTO IR modules, do optimization on the linked LTO IR,
// and generate cubin from it.
nvJitLinkComplete(handle);
. . .
// get linked cubin
size_t cubinSize;
NVJITLINK_SAFE_CALL(handle, nvJitLinkGetLinkedCubinSize(handle, &cubinSize));
void *cubin = malloc(cubinSize);
NVJITLINK_SAFE_CALL(handle, nvJitLinkGetLinkedCubin(handle, cubin));
NVJITLINK_SAFE_CALL(handle, nvJitLinkDestroy(&handle));
delete[] ltoIR1;
delete[] ltoIR2;
// cubin is linked, so now load it
CUDA_SAFE_CALL(cuModuleLoadData(&module, cubin));
CUDA_SAFE_CALL(cuModuleGetFunction(&kernel, module, "saxpy"));To see the complete example, visit NVIDIA/cuda-samples on GitHub.
LTO-IR object compatibility
The nvJitLink library performs JIT link on the LTO-IR directly to generate SASS, removing any reliance on the CUDA driver version for linking. It is the toolkit version of the nvJitLink library that processes the LTO-IR, and the toolkit version of the compiled LTO-IR that matters.
The nvJitLink library will retain support for older LTO-IR, but only if they are within the major release. This restriction primarily stems from any ABI breaking changes that LLVM may introduce for functionality or for performance that may be absorbed at major release boundaries.
However, older nvJitLink libraries cannot process the LTO-IR from newer NVCC even within the same major release. So the nvJitLink library version on the target system must always be from the highest version of the toolkit used for generating any individual module’s LTO-IR within the CUDA major release.
LTO-IR targets are link compatible only within a major release. For this reason, in order to link objects across major releases, use ELF level linking in PTX or SASS following the use case and install configurations. To aid this workflow, nvJitLink will also support new APIs for ELF linking similar to cuLinkAPIs that driver provided.
CUDA and JIT LTO compatibility
The GTC talk on JIT LTO use case was based on a driver-based solution. Due to the reliance on CUDA driver for cuLinkAPIs and nvvm optimizer, that implementation of JIT LTO did not support key compatibility guarantees of CUDA.
The following sections discuss how the new library can be used to leverage CUDA compatibility guarantees even when using JIT LTO.
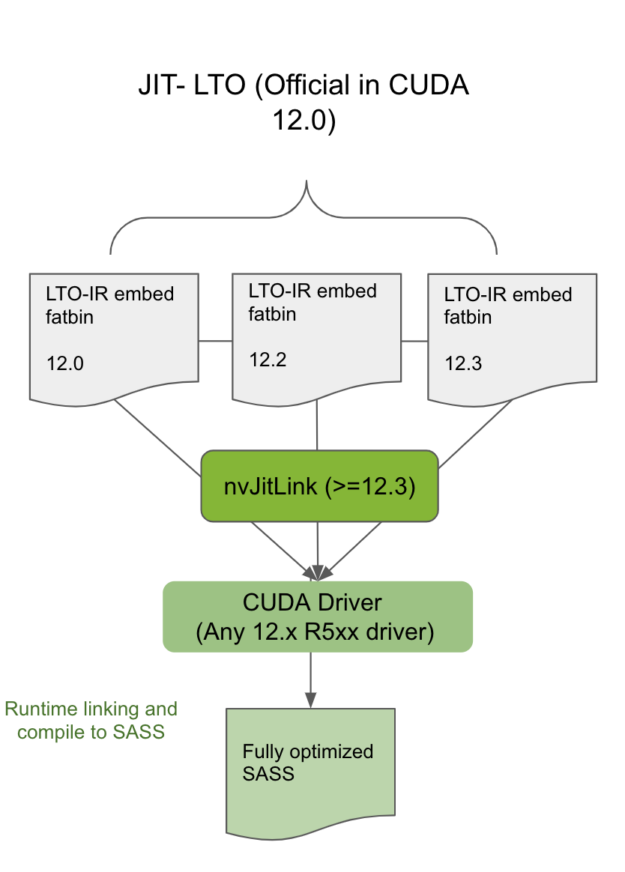
CUDA minor version compatibility
Linking the modules compiled and containing LTO-IR with the nvJitLink library from the same or a newer toolkit within the same CUDA major release will allow such applications using JIT LTO to work on any minor version compatible driver (Figure 3). Statically or dynamically link the highest version of nvJitLink library from the major release. To determine which CUDA driver is minor-version compatible with the toolkit version, see Table 2 in the CUDA 12.0 Release Notes.
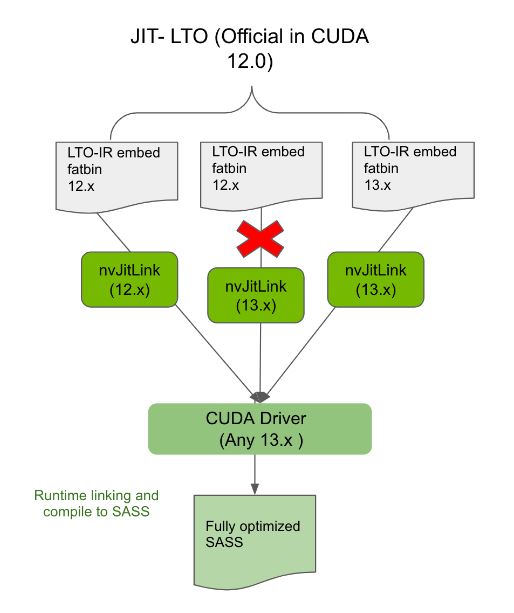
Backward compatibility
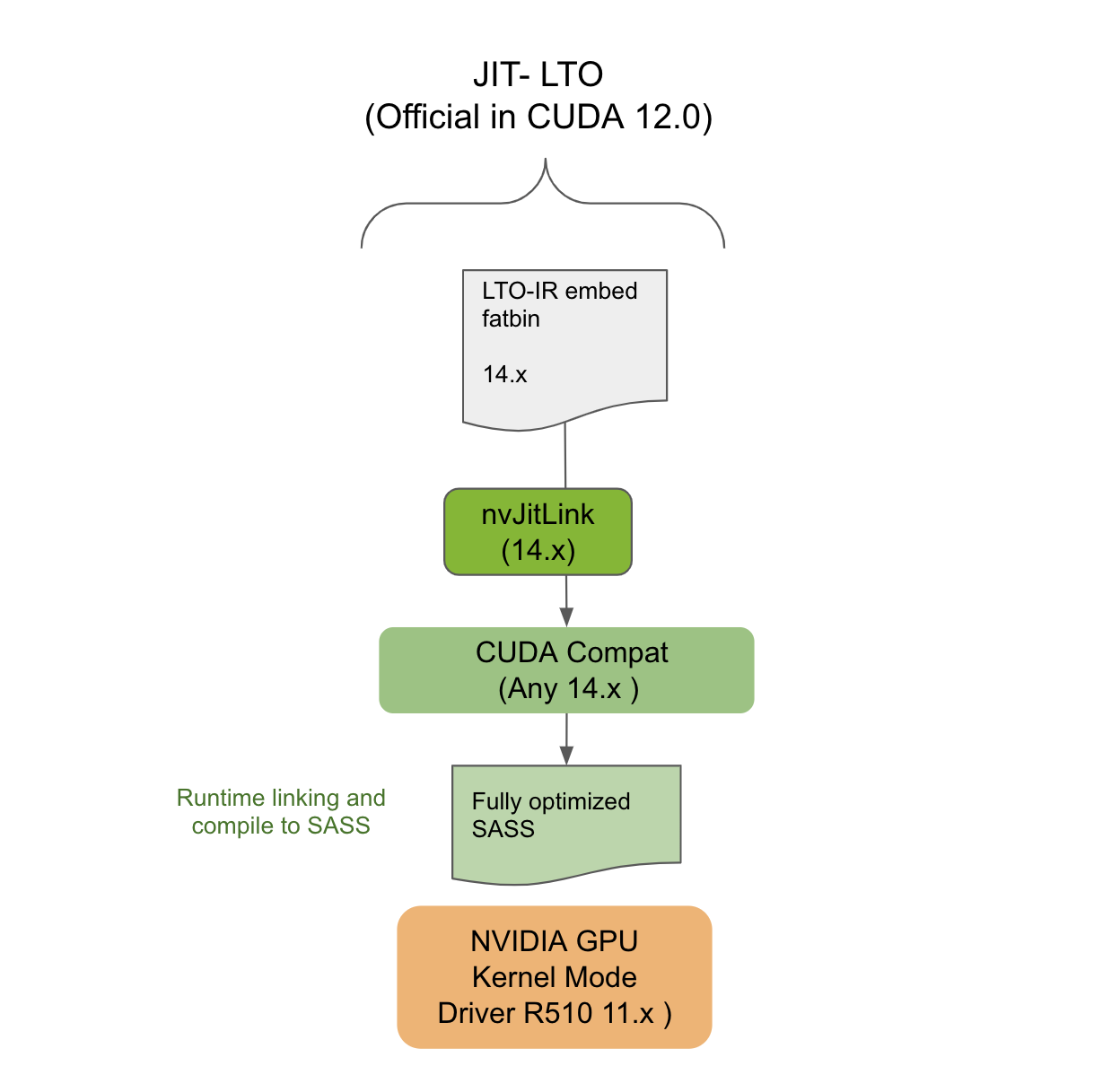
Always linking applications compiled to LTO-IR with the compatible nvJitLink library from the same major release will ensure such applications are backward compatible on any future CUDA driver. For example, the 12.x application linked with the 12.x nvJitLink library will work on the 13.x driver (Figure 4).
CUDA Forward Compatibility
This section explains how applications targeting LTO-IR for JIT LTO can still work in CUDA Forward Compatible deployment. Forward Compatibility is meant to allow deployment of the latest CUDA applications on NVIDIA GPU driver installations from an older release branch of a different major release. For example, the driver belongs to the 10.x era, but the application is from the 12.x era.
Using Forward Compatibility requires installation of a special CUDA compat package on the target system. The CUDA compat package is associated with the NVIDIA GPU CUDA driver but versioned by the toolkit. For the CUDA 11.4 version of JIT LTO to work, the CUDA compat package contained the needed components to make JIT LTO work in forward compatible mode.
However, now that the feature is part of the CUDA Toolkit new nvJitLink library, the presence of this library on the target system is like any other toolchain dependency. It must ensure its presence on the deployment system. The version of the nvJitLink library, once again, must match the toolkit version of the NVCC or NVRTC used for generating the LTO-IR. As shown in Figure 5, JIT LTO will work on systems in Forward Compatibility mode.
JIT LTO and cuFFT
This section shows how NVIDIA libraries like cuFFT leverage JIT LTO. Read on to get a sneak peek of what is coming for cuFFT users.
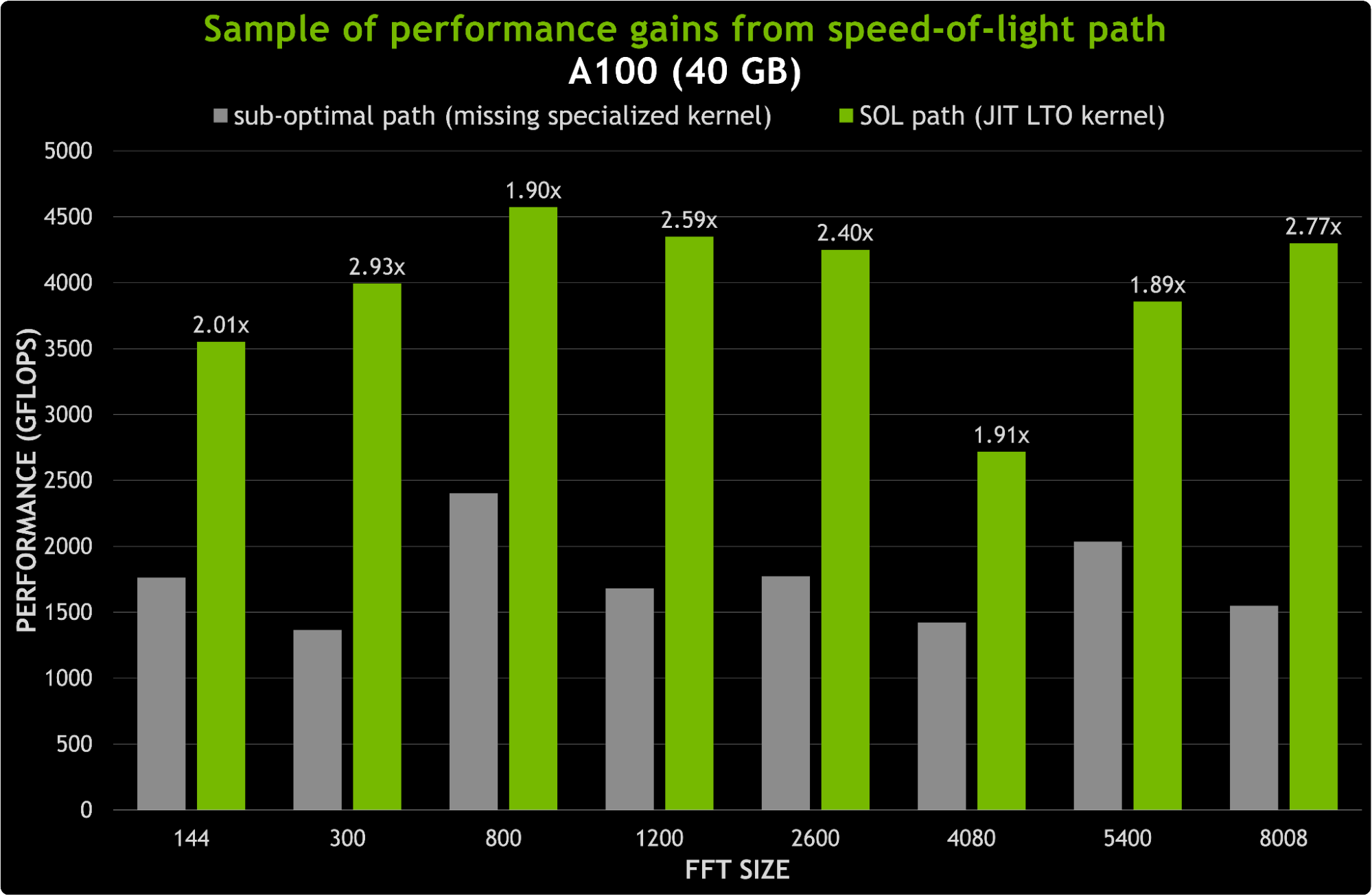
For some CUDA Math Libraries, such as cuFFT, the size of the binary is a limiting factor when delivering functionality and performance. More performance often means shipping more specialized kernels, which in turn means shipping larger binaries. For example, shipping a specialized kernel for every combination of data type, problem size, GPU, and transform (R2C, C2R, C2C) can cause the binary size to be larger than all math libraries combined. Therefore, decisions must be made when deciding which kernels to ship.
JIT LTO minimizes the impact on binary size by enabling the cuFFT library to build LTO optimized speed-of-light (SOL) kernels for any parameter combination, at runtime. This is achieved by shipping the building blocks of FFT kernels instead of specialized FFT kernels. Figure 6 shows possible speedups replacing suboptimal paths with new JIT LTO kernels. For sizes under 8K, the speedups can be as much as 3x.
The ideal application for this is incorporating user callback functions in the cuFFT kernels. Using JIT LTO to specialize the kernels removes the distinction between callback and non-callback kernels.
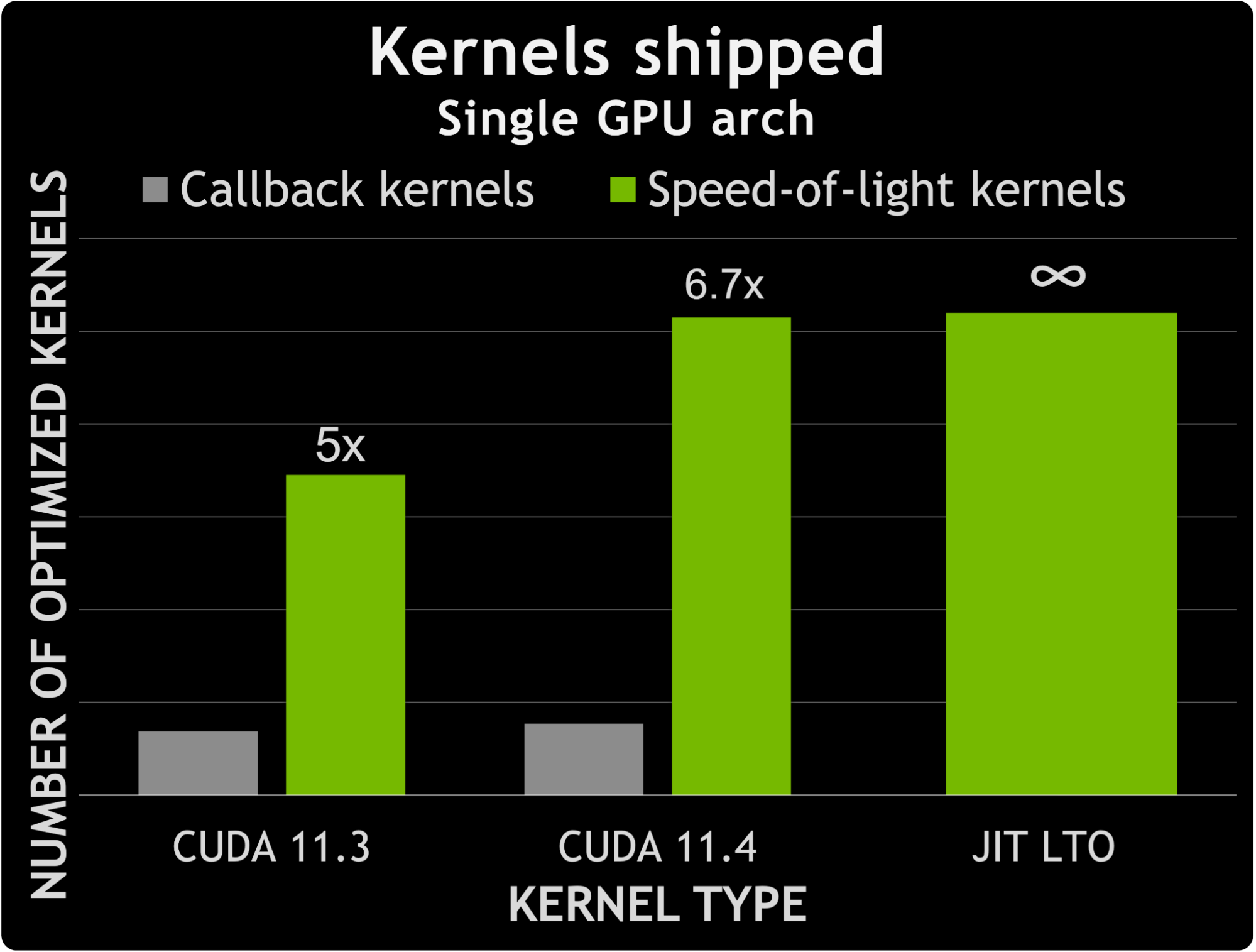
Between CUDA 11.3 and CUDA 11.4, cuFFT saw an increase in the number of non-callback SOL kernels of about 50%. In contrast, the number of kernels able to handle user callbacks increased by about 12%. This means that the difference between the number of specialized non-callback kernels and the number of specialized callback kernels grew by 1.6x.
Figure 7 shows a comparison between the number of callback kernels compared to the number of specialized kernels shipped with CUDA 11.3 and 11.4. It also hints at the possibilities provided by leveraging JIT LTO to handle user callbacks. Effectively the number of specialized callback kernels increases by almost 7x, without the increase in binary size that would come from adding that number of kernels.
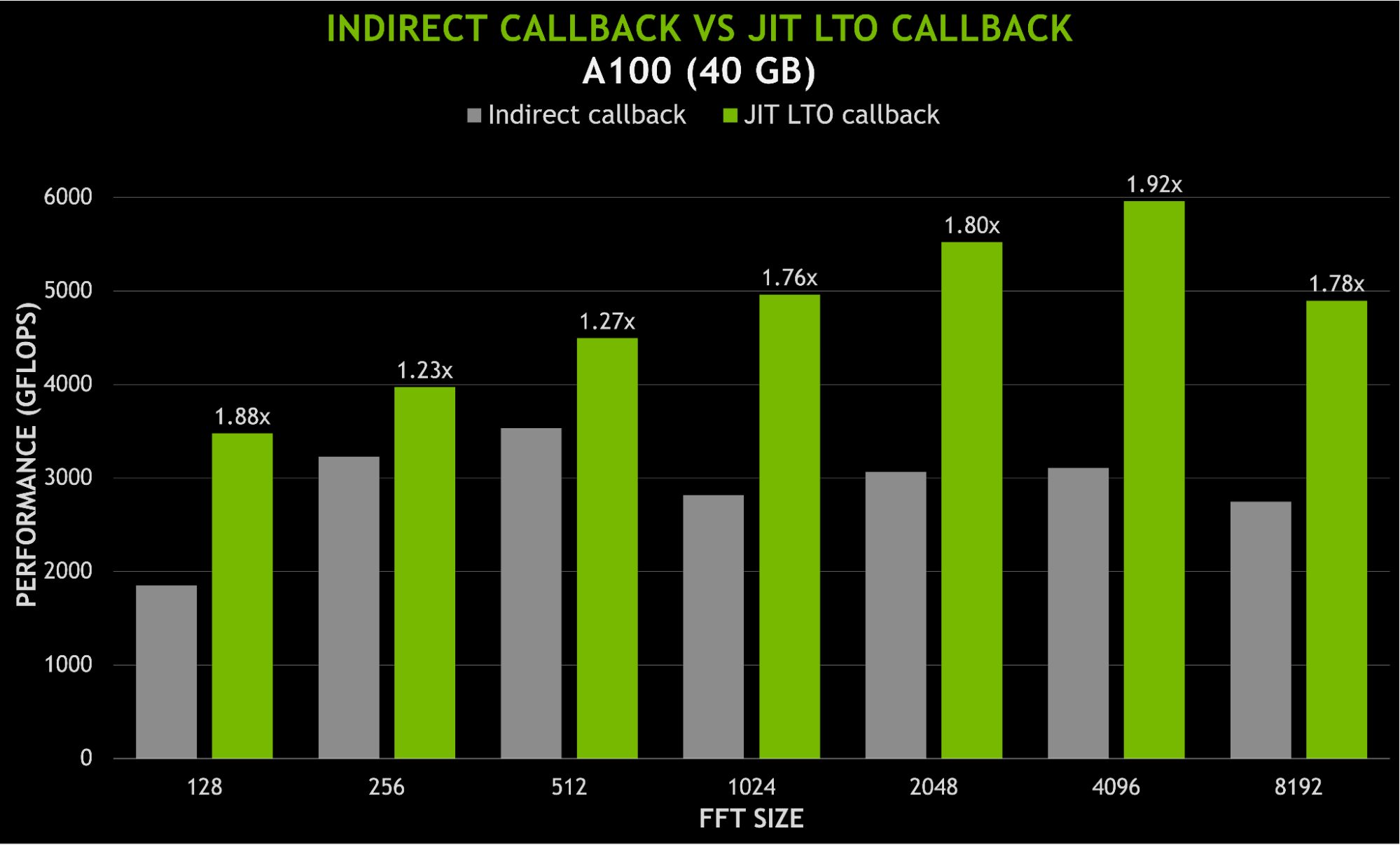
An additional benefit of using JIT LTO is being able to link user code together with the library kernel, without requiring separate offline device linking against a static library. Any overhead due to indirect calling to user functions should be minimized thanks to the link-time optimizations, particularly inlining. Figure 8 shows speedups of nearly 2x when using JIT LTO callbacks instead of indirect function calls.
Conclusion
In its newer form, JIT LTO should provide more benefits for application developers, library developers, and system admins. Table 1 highlights the different scenarios supported and the constraints to keep in mind when using LTO in general and JIT LTO in particular.
| Within a minor release | Across major release | |
| LTO-IR | Link compatible | Not link compatible. Link at PTX or SASS Level. |
| nvJitLink library | Use the highest version of the linking objects | Not compatible for linking. Runtime JIT to link compatible object PTX or SASS. |
CUDA compatibility and ease of deployment with non-negotiable performance benefits will define JIT LTO in its new form. In a future CUDA release, to enhance performance of JIT LTO even further, we are considering improvements to reduce runtime linking overhead through caching and other schemes.
