
Deep learning has come to mean the most common implementation of a neural network for performing many AI tasks. Data scientists use software frameworks such as TensorFlow and PyTorch to develop and run DL algorithms.
By this point, there has been a lot written about deep learning, and you can find more detailed information from many sources. For a good high-level summary, see What’s the Difference Between Artificial Intelligence, Machine Learning and Deep Learning?
A popular way to get started with deep learning is to run these frameworks in the cloud. However, as enterprises start to grow and mature their AI expertise, they look for ways to run these frameworks in their own data centers, to avoid the costs and other challenges of cloud-based AI.
In this post, I discuss how to choose an enterprise server for deep learning training. I review specific computational requirements of this unique workload, and then discuss how to address these needs with the best choice for component configuration.
System requirements for DL training
Deep learning training is often designed as a data processing pipeline. Raw input data must first be prepared in terms of data format, size, and other factors.
Data is also often preprocessed so that the same input can be presented in different ways to the model, depending on what the data scientist has determined will provide a more robust training set. For example, images can be rotated by a random amount, so that the model learns to recognize objects regardless of orientation. The prepared data is then fed into the DL algorithm.
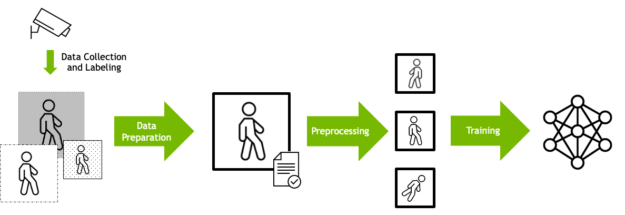
With this understanding of how DL training works, here are the specific computational needs for performing this task in the quickest and most efficient way.
GPU
At the heart of deep learning is the GPU. The process of calculating the values for each layer of a network is ultimately a huge set of matrix multiplications. The data for each layer can usually be worked on in parallel, with coordination steps between layers.
GPUs are designed to perform matrix multiplication in a massively parallel manner, and have proven to be ideal for achieving tremendous speed-ups for deep learning.
For training, size of model is the driving factor, and so GPUs with larger and faster memory, such as the NVIDIA A100 Tensor Core GPU, are able to crunch through batches of training data more quickly.
CPU
The data preparation and preprocessing computations required for DL training are usually performed on the CPU, although recent innovations have enabled more and more of this to be performed on GPUs.
It is critical to use a high-performance CPU to sustain these operations at a fast enough rate so that the GPU is not starved by waiting for data. The CPU should be enterprise-class, such as from the Intel Xeon Scalable processor family or AMD EPYC line, and the ratio of CPU cores to GPUs should be large enough to keep the pipeline running.
System memory
Especially for today’s biggest models, DL training works only when there is an extremely large amount of input data to train on. This data is retrieved from storage in batches and then worked on by the CPU while in system memory before being fed to the GPU.
To keep this process flowing at a sustained rate, the system memory should be large enough so the rate of CPU processing can match the rate at which the data is processed by the GPU. This can be expressed in terms of the ratio of system memory to GPU memory (across all GPUs in the server).
Different models and algorithms require a different ratio, but it is better to have a higher ratio, so that the GPU is never waiting for data.
Network adapter
As DL models have gotten larger, techniques have been developed to perform training with multiple GPUs working together. When more than one GPU is installed in a server, they can communicate with each other through the PCIe bus, although more specialized technologies such as NVLink and NVSwitch can be used for the highest performance.
Multi-GPU training can also be extended to work across multiple servers too. In this case, the network adapter becomes a critical component of a server’s design. High-bandwidth Ethernet or InfiniBand adapters are necessary to minimize bottlenecks due to data transfer when executing multi-node DL training.
DL frameworks make use of libraries such as NCCL to perform the coordination between GPUs in an optimum and performant manner. Technologies such as GPUDirect RDMA enable data to be transferred from the network directly to the GPU without having to go through the CPU, thus eliminating this as a source of latency.
Ideally, there should be one network adapter for every one or two GPUs in the system, to minimize contention when data must be transferred.
Storage
DL training data typically resides on external storage arrays. NVMe drives on the server can greatly accelerate the training process by providing a means to cache data.
DL I/O patterns typically consist of multiple iterations of reading the training data. The first pass, or epoch, of training reads the data that is used to start training the model. If adequate local caching is provided on the node, subsequent passes through the data can avoid rereading the data from remote storage.
To avoid contention when pulling data from remote storage, there should be one NVMe drive per CPU.
PCIe topology
With the complex interplay between CPU, GPU, and networking, it should be clear that having a connectivity design that reduces any potential bottlenecks in the DL training pipeline is crucial to achieving the best performance.
Most enterprise servers today use PCIe as the means of communication between components. The primary traffic on the PCIe bus occurs on the following pathways:
- From system memory to GPU
- Between GPUs on the same servers during multi-GPU training
- Between GPUs and the network adapter during multi-node training
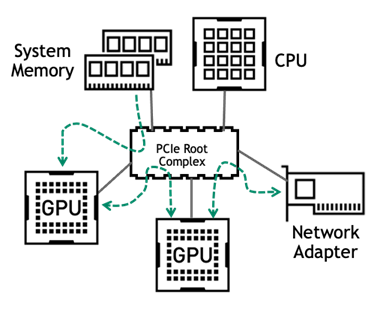
Servers to be used for deep learning should have a balanced PCIe topology, with GPUs spread evenly across CPU sockets and PCIe root ports. In all cases, the number of PCIe lanes to each GPU should be the maximum number supported.
If there are multiple GPUs and the number of PCIe lanes from the CPU are not enough to accommodate them all, then a PCIe switch might be required. In this case, the number of PCIe switch layers should be limited to one or two, to minimize PCIe latency.
Similarly, network adapters and NVMe drives should be under the same PCIe switch or PCIe root complex as the GPUs. In server configurations that use PCIe switches, these devices should be located under the same PCIe switch as the GPUs for best performance.
Choosing a validated system that supports DL training
It’s complex to design a server optimized for DL training. NVIDIA has published guidelines on configuring servers for various types of accelerated workloads, based on many years of experience with these workloads and working with developers to optimize code.
To make it easier for you to get started, NVIDIA developed the NVIDIA-Certified Systems program. System vendor partners have configured and tested numerous server models in various form factors with specific NVIDIA GPUs and network adapters to validate the optimal design for the best performance.
The validation also covers other important features for production deployment, such as manageability, security, and scalability. Systems are certified in a range of categories targeted to different workload types. The Qualified System Catalog has a list of NVIDIA-Certified Systems from NVIDIA partners. Servers in the Data Center category have been validated to provide the best performance for DL training.
NVIDIA AI Enterprise
Along with the right hardware, enterprise customers want to choose a supported software solution for AI workloads. NVIDIA AI Enterprise is an end-to-end, cloud-native suite of AI and data analytics software. It’s optimized so every organization can be good at AI, certified to deploy anywhere from the enterprise data center to the public cloud. AI Enterprise includes global enterprise support so that AI projects stay on track.
When you run NVIDIA AI Enterprise on optimally configured servers, you can be assured that you are getting the best out of your hardware and software investments.
Summary
In this post, I showed you how to choose an enterprise server for deep learning training, with specific computational requirements. Hopefully, you’ve learned how to address these needs with the best choices for component configuration.
For more information, see the following resources:
