Machine Learning (ML) has its origins in the field of Artificial Intelligence, which started out decades ago with the lofty goals of creating a computer that could do any work a human can do. While attaining that goal still appears to be in the distant future, many useful tools have been developed and successfully applied to a wide variety of problems. In fact, ML has now become a pervasive technology, underlying many modern applications. Today the world’s largest financial companies, internet firms and foremost research institutions are using ML in applications including internet search, fraud detection, gaming, face detection, image tagging, brain mapping, check processing and computer server health-monitoring, to name a few. The US Postal Service uses machine learning techniques for hand-writing recognition, and leading applied-research government agencies such as IARPA and DARPA are funding work to develop the next generation of ML systems.
Because of the increasing importance of DNNs in both industry and academia and the key role of GPUs, NVIDIA is introducing a library of primitives for deep neural networks called cuDNN. The cuDNN library makes it easy to obtain state-of-the-art performance with DNNs, and provides other important benefits.
Machine Learning with DNNs
A ML system may be thought of as a system that learns to recognize things of interest to us, without being told explicitly what the things are ahead of time. Classic examples of such a system are the spam classifier, which scans your incoming messages and quarantines spam emails, and product recommender systems which suggest new products (books, movies, etc.) that you might like based on your prior purchases and ratings.
A common method of implementing a ML system is to first train the system by exposing it to a large group of labelled examples. For example, we may show the system thousands of images of animals (cats, dogs, birds and so on) where each image is labelled (eg. “retriever”, “robin”). After training, we deploy the system and stream in unlabeled images, and it will rapidly and correctly identify the animal (if any) in the image, in much the same way a person would if they were reviewing the images.
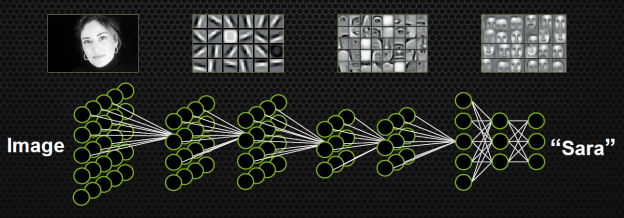
Though there are a wide variety of specific ML techniques, such as regression, support vector machines and clustering algorithms of various types—neural networks have become one of the most powerful tools in the ML practitioner’s toolbox. Neural networks are built from many idealized neurons. The output of an idealized neuron is a function—often the logistic function—of the weighted sum of its inputs. Past neural networks were typically both shallow (only one or two layers beyond the input layer) and fully connected, meaning each neuron receives input from every neuron in the layer below it. Today, the most highly performing neural networks are deep, often having on the order of 10 layers (and the trend is toward even more layers). A neural network with more than one layer can learn to recognize highly complex, non-linear features in its input. Furthermore, modern DNNs typically have some layers which are not fully connected. Figure 1 shows a schematic of a hypothetical DNN for face recognition.
An alternative to a fully connected layer is a convolutional layer. A neuron in a convolutional layer is connected to neurons only in a small region in the layer below it. Typically this region might be a 5×5 grid of neurons (or perhaps 7×7 or 11×11). The size of this grid is called the filter size. Thus a convolutional layer can be thought of as performing a convolution on its input. This type of connection pattern mimics the pattern seen in perceptual areas of the brain, such as retinal ganglion cells or cells in the primary visual cortex.
In a DNN convolutional layer, the filter weights are the same for each neuron in that layer. Typically, a convolutional layer is implemented as many “sub layers” each with a different filter. Hundreds of different filters may be used in one convolutional layer. One can think of a DNN convolutional layer as performing hundreds of different convolutions on its input at the same time, with the results of these convolutions available to the next layer up. DNNs that incorporate convolutional layers are called Convolutional Neural Networks (CNNs).
CNNs have recently been dominating ML algorithm competitions on perceptual tasks, such as recognizing handwriting, detecting pedestrians in images and speech recognition. In addition to having excellent performance, CNNs scale well to large input data sets, such as all the pixels in an image. Neural networks are also relatively simple to implement. This combination of desirable attributes has contributed to their popularity.
GPUs for DNNs
However DNNs and CNNs require large amounts of computation, especially during the training phase. Neural networks are trained by presenting the input to the network and letting the resulting activations of the neurons flow up through the net to the output layer, where the result is compared to the correct answer. An error is calculated for each unit in the output layer and this error is “back propagated” down through the network to adjust each connection weight by a small amount. Thus there is a “forward pass” of the input to generate an output, and a “backward pass” to propagate error information through the network when training. When deployed, only the forward pass is used.
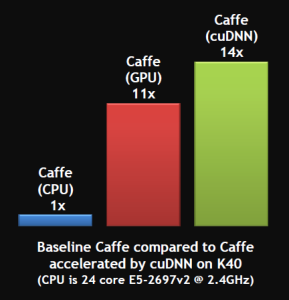
State-of-the-art DNNs and CNNs can have from millions to well over one billion parameters to adjust via back-propagation. Furthermore, DNNs require a large amount of training data to achieve high accuracy, meaning hundreds of thousands to millions of input samples will have to be run through both a forward and backward pass. Because neural networks are created from large numbers of identical neurons they are highly parallel by nature. This parallelism maps naturally to GPUs, which provide a significant speed-up over CPU-only training, as shown in Figure 2. In our own benchmarking using cuDNN with a leading neural network package called CAFFE, we obtain more than a 10X speed-up when training the “reference Imagenet” DNN model on an NVIDIA Tesla K40 GPU, compared to an Intel IvyBridge CPU.
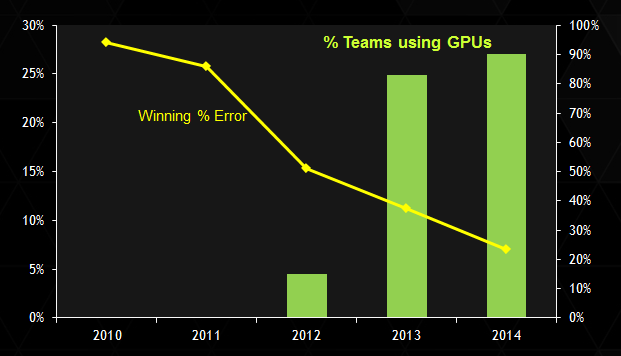
This connection between GPUs and DNNs is revealed clearly when we look at the results of the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), as shown in Figure 3. Prior to 2012, no teams were using GPU-accelerated DNNs, and winning error rates were typically improving by 10% per year or less (yellow line in Figure 3). In 2012, a team led by Geoff Hinton and Alex Krizhevsky from the University of Toronto was the first to use a GPU-accelerated DNN, and they won the competition by a large margin. Since then, the proportion of teams using GPU-accelerated DNNs has grown significantly (green bars in Figure 3) and these DNNs continue to demonstrate winning performance. Data from this year is still being compiled, but at the time of writing it appears at least 90% of teams in ILSVRC14 used GPUs.
Introducing cuDNN
NVIDIA cuDNN is a GPU-accelerated library of primitives for DNNs. It provides tuned implementations of routines that arise frequently in DNN applications, such as:
- convolution
- pooling
- softmax
- neuron activations, including:
- Sigmoid
- Rectified linear (ReLU)
- Hyperbolic tangent (TANH)
Of course these functions all support the usual forward and backward passes. cuDNN’s convolution routines aim for performance competitive with the fastest GEMM-based (matrix multiply) implementations of such routines while using significantly less memory.
cuDNN features customizable data layouts, supporting flexible dimension ordering, striding and subregions for the 4D tensors used as inputs and outputs to all of its routines. This flexibility allows easy integration into any neural net implementation and avoids the input/output transposition steps sometimes necessary with GEMM-based convolutions.
cuDNN is thread safe, and offers a context-based API that allows for easy multithreading and (optional) interoperability with CUDA streams. This allows the developer to explicitly control the library setup when using multiple host threads and multiple GPUs, and ensure that a particular GPU device is always used in a particular host thread (for example).
cuDNN allows DNN developers to easily harness state-of-the-art performance and focus on their application and the machine learning questions, without having to write custom code. cuDNN works on Windows or Linux OSes, and across the full range of NVIDIA GPUs, from low-power embedded GPUs like Tegra K1 to high-end server GPUs like Tesla K40. When a developer leverages cuDNN, they can rest assured of reliable high performance on current and future NVIDIA GPUs, and benefit from new GPU features and capabilities in the future.
Going forward, we plan to focus on continually improving performance and expanding the scope of supported functionality. The next version will have significant performance improvements for convolution routines and implement a wider variety of neuron types, focusing on those which typically appear in convolutional neural nets. We are also very eager to add support for splitting computation across multiple GPUs on the same node, and we’re aiming to have something for this in a subsequent release.
Ease of Use
The cuDNN library is targeted at developers of DNN frameworks (eg. CAFFE, Torch). However it is easy to use directly and you do not need to know CUDA in order to use it. The example code below shows how to allocate storage for an input batch of images and a convolutional filter in cuDNN, and how to run the batch in the forward direction through a convolutional layer.
The calls to cudnnSetTensor4dDescriptor() and cudnnSetFilterDescriptor() define the input to this convolutional layer and filter parameters, respectively. The call to cudnnSetConvolutionDescriptor initializes the convolution descriptor for this layer using the descriptors from the previous two calls and some layer-specific information such as padding and striding parameters. The following call, cudnnGetOutputTensor4dDim(), calculates the dimensions of the convolution’s output for you. The next calls simply configure and allocate storage for the output of this layer, and then cudnnConvolutionForward() performs the NVIDIA-tuned convolution.
/* Allocate memory for Filter and ImageBatch, fill with data */
cudaMalloc( &ImageInBatch , ... );
cudaMalloc( &Filter , ... );
...
/* Set decriptors */
cudnnSetTensor4dDescriptor(InputDesc, CUDNN_TENSOR_NCHW, 128, 96, 221,221);
cudnnSetFilterDescriptor(FilterDesc, 256, 96, 7, 7 );
cudnnSetConvolutionDescriptor(convDesc, InputDesc, FilterDesc,
pad_x, pad_y, 2, 2, 1, 1, CUDNN_CONVOLUTION);
/* query output layout */
cudnnGetOutputTensor4dDim(convDesc, CUDNN_CONVOLUTION_FWD, &n_out, &c_out,
&h_out, &w_out);
/* Set and allocate output tensor descriptor */
cudnnSetTensor4dDescriptor(&OutputDesc, CUDNN_TENSOR_NCHW, n_out, c_out,
h_out, w_out);
cudaMalloc(&ImageBatchOut, n_out*c_out*h_out*w_out * sizeof(float));
/* launch convolution on GPU */
cudnnConvolutionForward(handle, InputDesc, ImageInBatch, FilterDesc,
Filter, convDesc, OutputDesc, ImageBatchOut,
CUDNN_RESULT_NO_ACCUMULATE);
While cuDNN is clearly very straightforward to use, we expect that most people will choose to leverage cuDNN through a neural network toolkit of their choice. In some cases, this can mean no coding is necessary at all.
No Programming Required
cuDNN is integrated into the development branch of the CAFFE neural network toolkit today! It is expected to be part of the official CAFFE 1.0 release. In CAFFE, a DNN is completely defined and implemented via text-based configuration files. With CAFFE you define each of the “layers” of your neural network, specifying the type of the layer (eg. data, convolutional, or fully connected) and the layers that provide its input. There is a very similar configuration file to define how to initialize the parameters of your network and how many iterations to train it for and so on. The following is a slightly simplified example of a CAFFE neural network definition configuration with one data layer and two convolutional layers.
layers {
name: “MyData”
type: DATA
top: “data”
top: “label”
}
layers {
name: “Conv1”
type: CONVOLUTION
bottom: “MyData”
top: “Conv1”
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
}
}
layers {
name: “Conv2”
type: CONVOLUTION
bottom: “Conv1”
top: “Conv2”
convolution_param {
num_output: 256
kernel_size: 5
}
}
Try cuDNN yourself!
![]()
![]()
If you are a user of machine learning frameworks, check out the new post Deep Learning for Computer Vision with Caffe and cuDNN.
cuDNN is free for anyone to use for any purpose: academic, research or commercial. Just sign up for a registered CUDA developer account. Once your account is activated, log in and visit the cuDNN page at developer.nvidia.com/cuDNN. The included User Guide will help you use the library. Note that the cuDNN license allows you to install and use as many copies of the software as you need, for both individual and corporate use. This intentionally permissive license is designed to allow cuDNN to be useful in conjunction with open-source frameworks.
Get started with cuDNN today!
References
[1] H. Lee, R. Grosse, R. Ranganath, and A. Y. Ng. “Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations.” In ICML 2009.