
 Artificial intelligence is already more ubiquitous than many people realize. Applications of AI abound, many of them powered by complex deep neural networks trained on massive data using GPUs. These applications understand when you talk to them; they can answer questions; and they can help you find information in ways you couldn’t before. Pinterest image search technology allows users to find products by highlighting them in images. Streaming media services like Netflix automatically recommend movies and shows for you to watch. And voice assistants like Apple Siri use deep learning networks trained on GPUs to understand spoken language and respond to requests with high accuracy. Deep learning is fueling all industries, from health, to security, to agriculture, and it is touching our lives by translating languages, helping doctors plan appropriate treatments in the ICU, and helping the visually impaired to better navigate and understand their surroundings.
Artificial intelligence is already more ubiquitous than many people realize. Applications of AI abound, many of them powered by complex deep neural networks trained on massive data using GPUs. These applications understand when you talk to them; they can answer questions; and they can help you find information in ways you couldn’t before. Pinterest image search technology allows users to find products by highlighting them in images. Streaming media services like Netflix automatically recommend movies and shows for you to watch. And voice assistants like Apple Siri use deep learning networks trained on GPUs to understand spoken language and respond to requests with high accuracy. Deep learning is fueling all industries, from health, to security, to agriculture, and it is touching our lives by translating languages, helping doctors plan appropriate treatments in the ICU, and helping the visually impaired to better navigate and understand their surroundings.
The challenge to enabling more uses of AI in everyday life is that the production of data is growing exponentially (especially video data), and the AI and machine learning models that interpret, transform, and interact with that data continue to get more complex and computationally expensive. These trends place increasing pressure on the data center.
Deep Learning Demands a New Class of HPC
You can think of machine learning data center processing as two separate computing centers—one for training and one for inference—connected by a circular loop. Large user datasets are fed into the training servers to produce trained deep neural network (DNNs) models. On-line applications take data from users, and use inference servers to apply the trained DNN to classify, detect, predict or translate (or otherwise transform) results from the input data and send the results back to the user (often in real time).
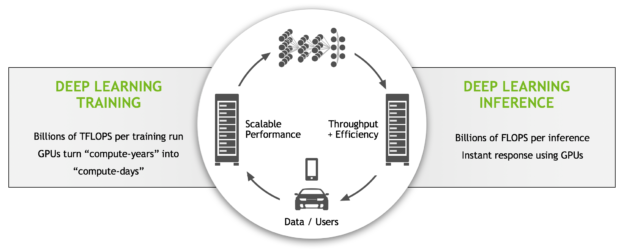
To create the most accurate models possible, the cost of training increasingly complex DNNs from massive data sets is growing exponentially, from millions of TFLOPs a couple of years ago to billions of TFLOPs today. Inference in the data center runs a copy of the trained model on many servers which must respond to user requests as quickly as possible, as users tolerate only very low latency of response, depending on the application. As the trained models become more complex, the computational demands on inference increase as well: what used to take millions of FLOPs now requires billions.
Meeting the growing computational needs of machine learning in the data center requires a new class of accelerators designed for the scaling requirements of deep learning training, and the low-latency requirements of inference. The NVIDIA Pascal architecture was designed to meet these challenges, and today NVIDIA is announcing the new Tesla P4 and P40 accelerators.
NVIDIA Tesla P4
Engineered to deliver maximum efficiency in scale-out servers, Tesla P4 is designed to meet the density and power efficiency requirements of modern data centers. Tesla P4 provides high performance on a tight power budget, and it is small enough to fit in any server (PCIe half-height, half-length).
 Tesla P4’s Pascal GP104 GPU provides not only high floating point throughput and efficiency, but it features optimized instructions aimed at deep learning inference computations. Specifically, the new IDP2A and IDP4A instructions provide 8-bit integer (INT8) 2- and 4-element vector dot product computations with 32-bit integer accumulation. Deep learning research has found that trained deep neural networks can be applied to inference using reduced precision arithmetic, with minimal impact on accuracy. These instructions allow rapid computation on packed low-precision vectors. Tesla P4 is capable of a peak 21.8 INT8 TOP/s (Tera-Operations per second).
Tesla P4’s Pascal GP104 GPU provides not only high floating point throughput and efficiency, but it features optimized instructions aimed at deep learning inference computations. Specifically, the new IDP2A and IDP4A instructions provide 8-bit integer (INT8) 2- and 4-element vector dot product computations with 32-bit integer accumulation. Deep learning research has found that trained deep neural networks can be applied to inference using reduced precision arithmetic, with minimal impact on accuracy. These instructions allow rapid computation on packed low-precision vectors. Tesla P4 is capable of a peak 21.8 INT8 TOP/s (Tera-Operations per second).
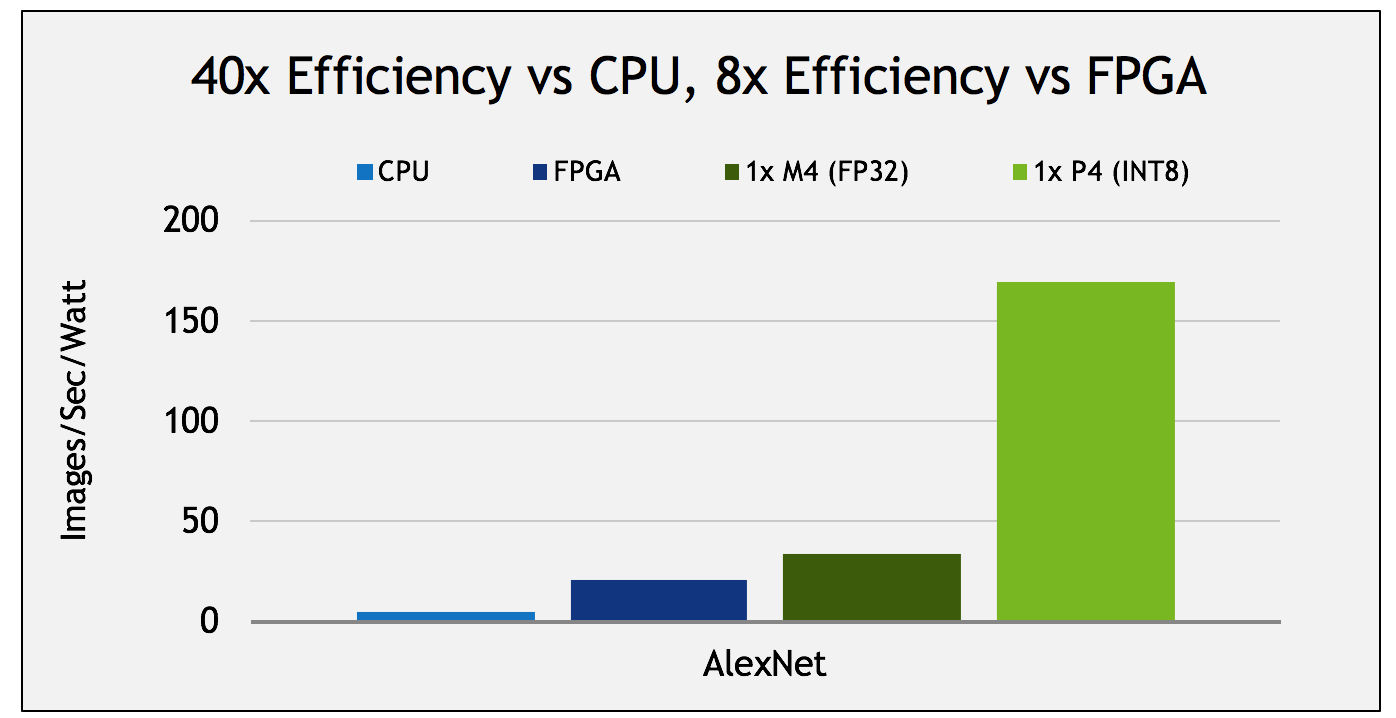
This capability results in massive efficiency gains for deep learning inference. Tesla P4 is 40x more efficient in terms of AlexNet images per second per watt than an Intel Xeon E5 CPU, and 8x more efficient than an Arria 10-115 FPGA, as Figure 1 shows.
NVIDIA Tesla P40

The new NVIDIA Tesla P40 accelerator is engineered to deliver the highest throughput for scale-up servers, where performance matters most. Tesla P40 has 3840 CUDA cores with a peak FP32 throughput of 12 TeraFLOP/s, and like it’s little brother P4, P40 also accelerates INT8 vector dot products (IDP2A/IDP4A instructions), with a peak throughput of 47.0 INT8 TOP/s.
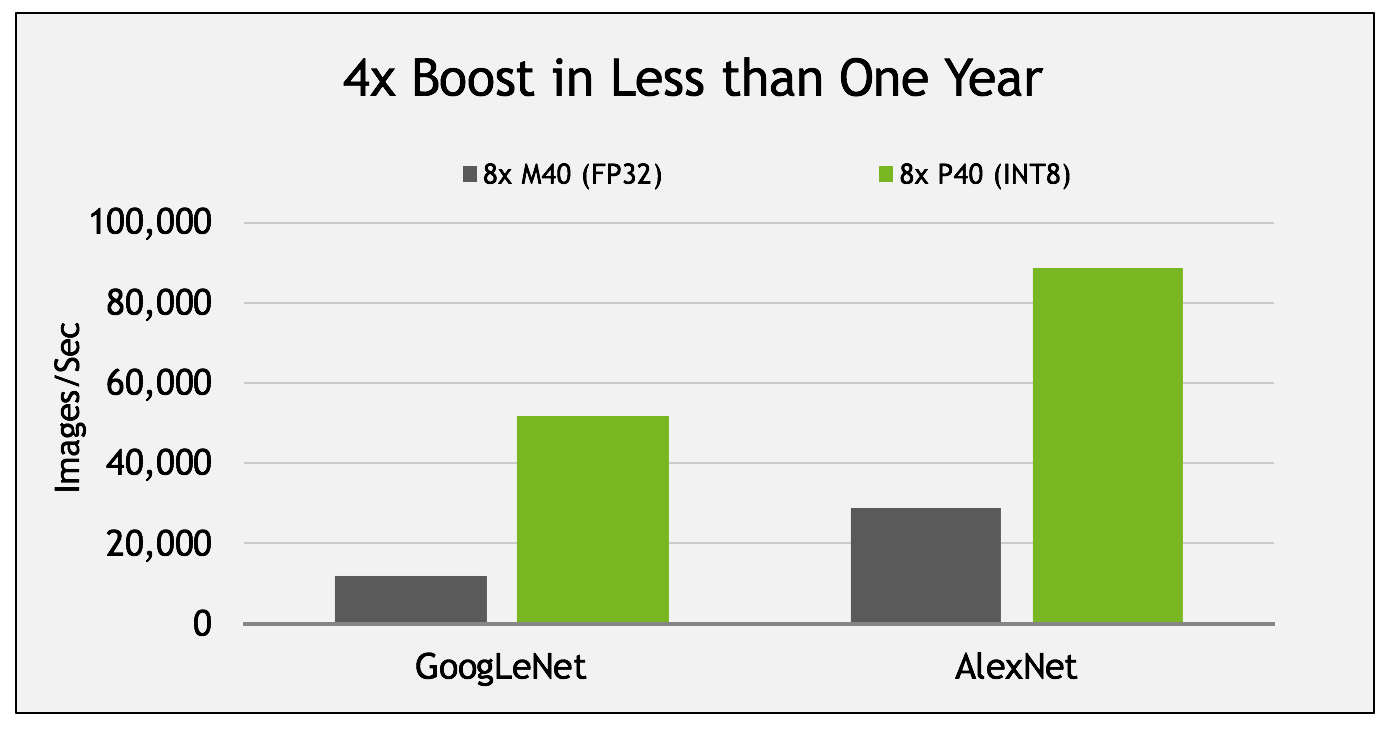
Tesla P40 provides speedups on deep learning inference performance of up to 4x compared to the previous generation M40 (announced in November 2015), as Figure 2 shows. That’s more than 4x in less than one year, thanks to the improvements in the Pascal architecture (see the post Inside Pascal).
The following table provides a side-by-side comparison of Tesla P4 and P40 data center accelerators to the previous-generation Tesla M4 and M40.
| Tesla Accelerator | Tesla M4 | Tesla P4 | Tesla M40 | Tesla P40 |
| GPU | Maxwell GM206 | Pascal GP104 | Maxwell GM200 | Pascal GP102 |
| SMs | 8 | 20 | 24 | 30 |
| FP32 CUDA Cores / SM | 128 | 128 | 128 | 128 |
| FP32 CUDA Cores / GPU | 1024 | 2560 | 3072 | 3840 |
| Base Clock | 872 MHz | 810 MHz | 948 MHz | 1303 MHz |
| GPU Boost Clock | 1072 MHz | 1063 MHz | 1114 MHz | 1531 MHz |
| INT8 TOP/s[1] | NA | 21.8 | NA | 47.0 |
| FP32 GFLOP/s[1] | 2195 | 5442 | 6844 | 11758 |
| FP64 GFLOP/s[1] | 69 | 170 | 213 | 367 |
| Texture Units | 64 | 160 | 192 | 240 |
| Memory Interface | 128-bit GDDR5 | 256-bit GDDR5 | 384-bit GDDR5 | 384-bit GDDR5 |
| Memory Bandwidth | 88 GB/s | 192 GB/s | 288 GB/s | 346 GB/s |
| Memory Size | 4 GB | 8 GB | 12/24 GB | 24 GB |
| L2 Cache Size | 2048 KB | 2048 KB | 3072 KB | 3072 KB |
| Register File Size / SM | 256 KB | 256 KB | 256 KB | 256 KB |
| Register File Size / GPU | 2048 KB | 5120 KB | 6144 KB | 7680 KB |
| Shared Memory Size / SM | 96KB | 96KB | 96KB | 96KB |
| Compute Capability | 5.2 | 6.1 | 5.2 | 6.1 |
| TDP | 50/75 W | 75 W (50W option) | 250 W | 250 W |
| Transistors | 2.9 billion | 7.2 billion | 8 billion | 12 billion |
| GPU Die Size | 227 mm² | 314 mm² | 601 mm² | 471 mm² |
| Manufacturing Process | 28-nm | 16-nm | 28-nm | 16-nm |
Introducing NVIDIA TensorRT
 To complement the Tesla Pascal GPUs for inference, NVIDIA is releasing TensorRT, a deep learning inference engine. TensorRT, previously called GIE (GPU Inference Engine), is a high-performance inference engine designed to deliver maximum inference throughput and efficiency for common deep learning applications such as image classification, segmentation, and object detection. TensorRT optimizes your trained neural networks for run-time performance and delivers GPU-accelerated inference for web/mobile, embedded and automotive applications.
To complement the Tesla Pascal GPUs for inference, NVIDIA is releasing TensorRT, a deep learning inference engine. TensorRT, previously called GIE (GPU Inference Engine), is a high-performance inference engine designed to deliver maximum inference throughput and efficiency for common deep learning applications such as image classification, segmentation, and object detection. TensorRT optimizes your trained neural networks for run-time performance and delivers GPU-accelerated inference for web/mobile, embedded and automotive applications.
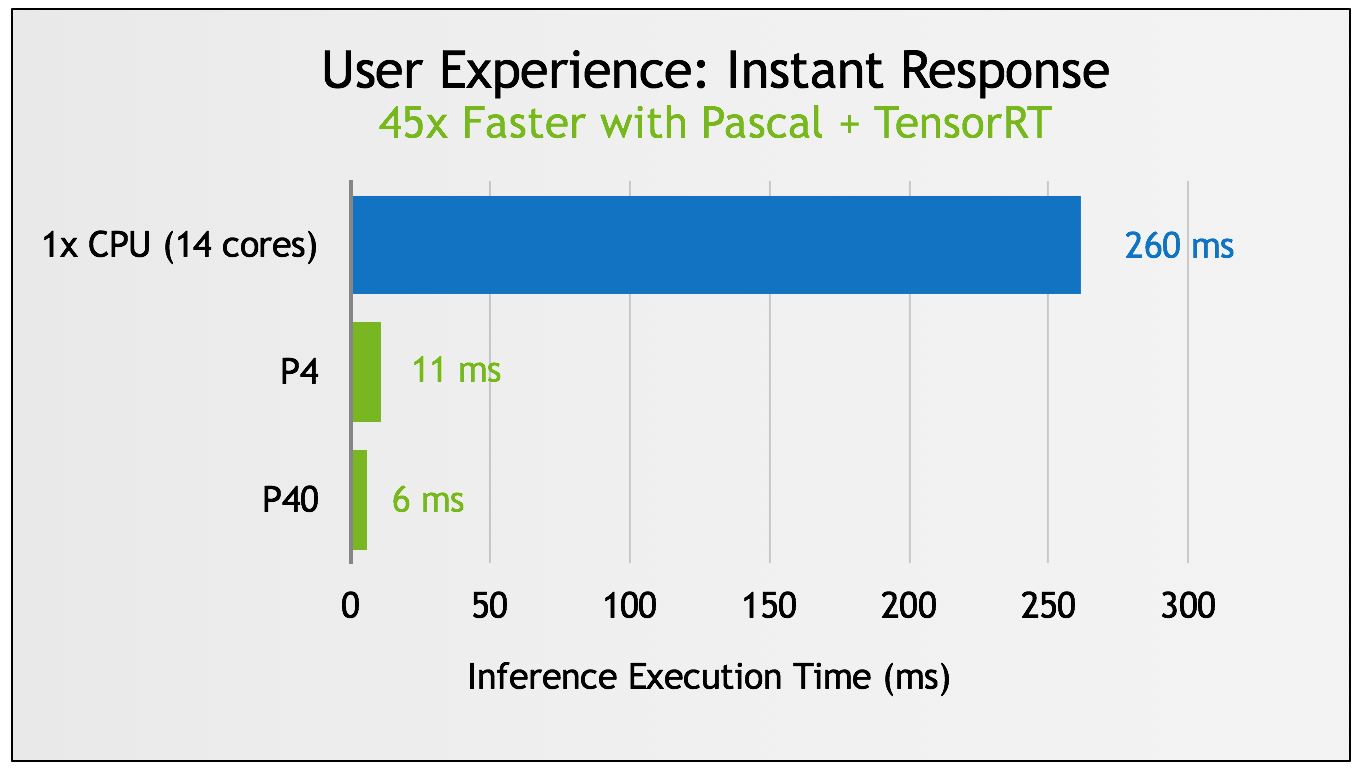
TensorRT applies graph optimizations to neural networks including horizontal and vertical layer fusion, and tunes the network for the specific GPU to be used for deployment—including optimizing for INT8 computation in the upcoming TensorRT 2 release—resulting in significant speedups and much higher efficiency, as Figure 3 shows. See this past blog post for details on TensorRT’s optimizations.
Tesla P4 and P40: Available for Every Server
Tesla P40 will be available in October, and Tesla P4 will available to customers in November. The new accelerators will be available for every server, and supported by all major OEMs and ODMs. Click here for more information on Tesla P4 and P40.
More information on TensorRT is available here, and for details on its design and functionality, see the past post Production Deep Learning with GPU Inference Engine.