
Companies providing synthetic data generation tools and services, as well as developers, can now build custom physically accurate synthetic data generation pipelines with the Omniverse Replicator SDK. Built on the NVIDIA Omniverse platform, the Omniverse Replicator SDK is available in beta within Omniverse Code.
Omniverse Replicator is a highly extensible SDK built on a scalable Omniverse platform for physically accurate 3D synthetic data generation to accelerate training and performance of AI perception networks. Developers, researchers, and engineers can now use Omniverse Replicator to bootstrap and improve performance of existing deep learning perception models with large-scale photorealistic synthetic data.
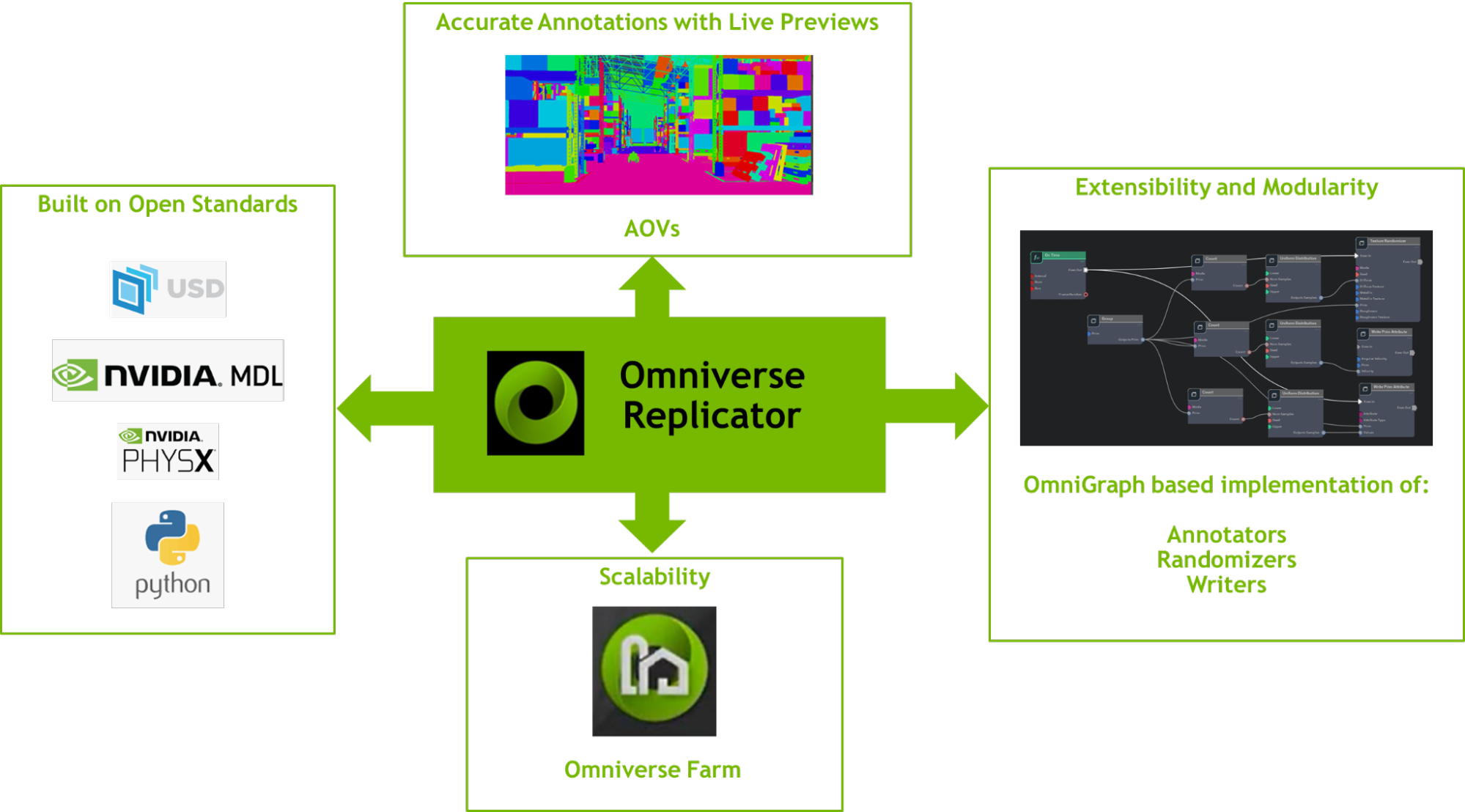
Omniverse Replicator provides an extraordinary platform for developers to build synthetic data generation applications specific to their neural network’s requirements. Built on open standards like Universal Scene Description (USD), PhysX, and Material Definition Language (MDL), with easy to use python APIs, it’s also made for expandability, supporting custom randomizers, annotators, and writers. Supporting lightning fast data generation with a CUDA-based OmniGraph implementation of core annotator features means that output can be instantly previewed. When combined with Omniverse Farm and SwiftStack output, Replicator provides massive scalability in the cloud.
The Omniverse Replicator SDK is composed of six primary components for custom synthetic data workflows:
- Semantic Schema Editor: With Semantic labeling of 3D assets and its prims, Replicator can annotate objects of interest during the rendering and data generation process. The Semantic Schema Editor provides a way to apply these labels to prims on the stage through a user interface.
- Visualizer: This provides visualization capabilities for the semantic labels assigned to 3D assets along with annotations like 2D/3D bounding boxes, normals, depth, and more.
- Randomizers: Domain randomization is one of the most important capabilities of Replicator. Using randomizers you can create randomized scenes, sampling from assets, materials, lighting, and camera positions among other randomization capabilities.
- Omni.syntheticdata: This provides low-level integration with Omniverse RTX Renderer and OmniGraph computation graph system. It also powers Replicator’s ground truth extraction Annotators, passing Arbitrary Output Variables (AOVs) from the renderer through to the Annotators.
- Annotators: These ingest AOVs and other output from the Omni.syntheticdata extension to produce precisely labeled annotations for deep neural network (DNN) training.
- Writers: Process images and other annotations from the annotators, and produce DNN-specific data formats for training.
Synthetic data in AI training
Training a DNN for perception tasks often involves manual collection of data from millions of images followed by manually annotating these images and optional augmentations.
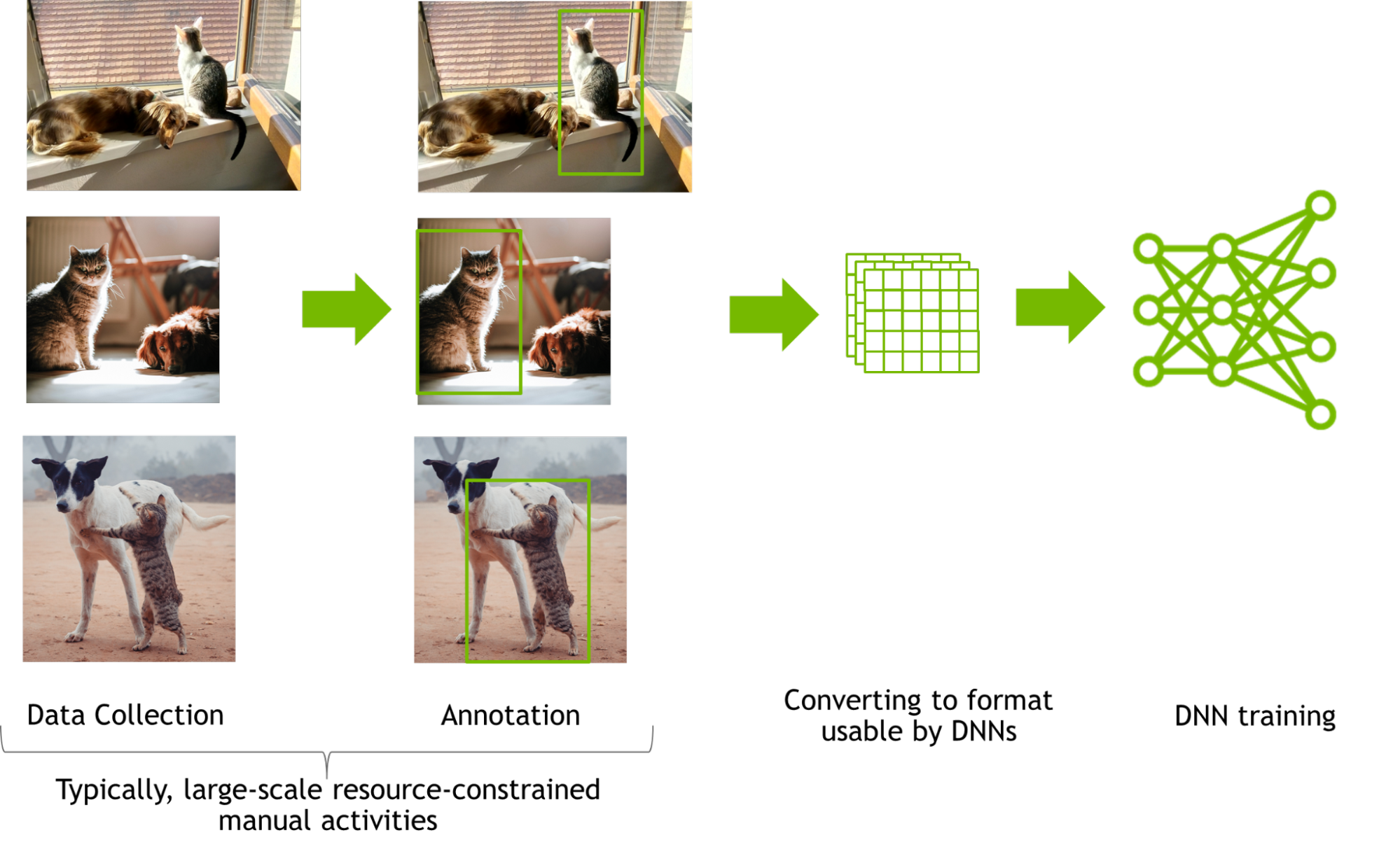
Manual data collection and annotations are laborious and subjective. Collecting and annotating real images with even simple annotations like 2D bounding boxes at a large scale pose many logistical challenges. Involved annotations such as segmentation are resource constrained and are far less accurate when performed manually.

Once collected and annotated, the data is converted into the format usable by the DNN, and the DNN is then trained for the perception tasks. Hyperparameter tuning or changes in network architecture are typical next steps to optimize network performance. Analysis of the model performance may lead to potential changes in the dataset, but in most cases, this requires another cycle of manual data collection and annotation. This iterative cycle of manual data collection and annotation is expensive, tedious, and slow.
With synthetically generated data, teams can bootstrap and enhance large-scale training data generation with accurate annotations in a cost-effective manner. Plus, synthetic data generation also helps solve challenges related to long tail anomalies, lack of available training data, and online reinforcement learning. Unlike manually collected and annotated data, synthetically generated data has lower amortization cost, which is beneficial for typical iterative nature of the data collection/annotations and model training cycle.
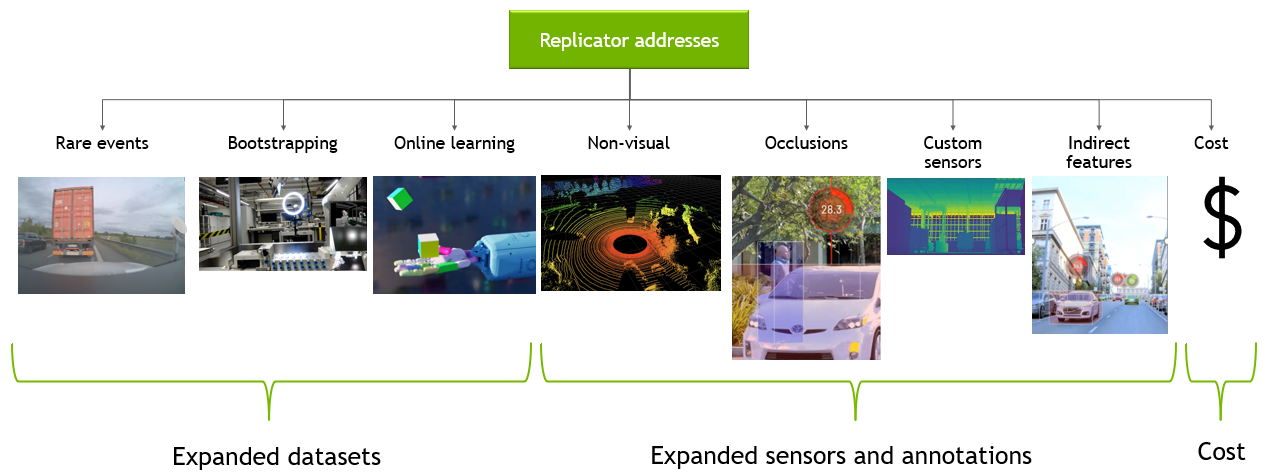
Omniverse Replicator addresses these challenges by leveraging many of the core functionalities of the Omniverse platform and best practices including but not limited to physically accurate, photoreal datasets and access to very large datasets.
Physically accurate, photoreal datasets require accurate ray tracing and path tracing with RTX technologies, physically based materials, and physics engine—all core technologies of the Omniverse platform.

Based on Universal Scene Description (USD), Omniverse seamlessly connects to other 3D applications so developers can bring in custom-made content, or write their own tools to generate diverse domain scenes. Generating these assets is often a bottleneck, as it requires scaling across multiple GPUs and nodes.
Omniverse Replicator leverages Omniverse Farm, which lets teams use multiple workstations or servers together to power jobs like rendering or synthetic data generation. A synthetic data generation workflow is not “one and done.” To train a network with synthetic data successfully, the network has to be tested iteratively on a real dataset. Replicator provides this kind of data-centric AI training by converting simulated worlds into a set of learnable parameters.
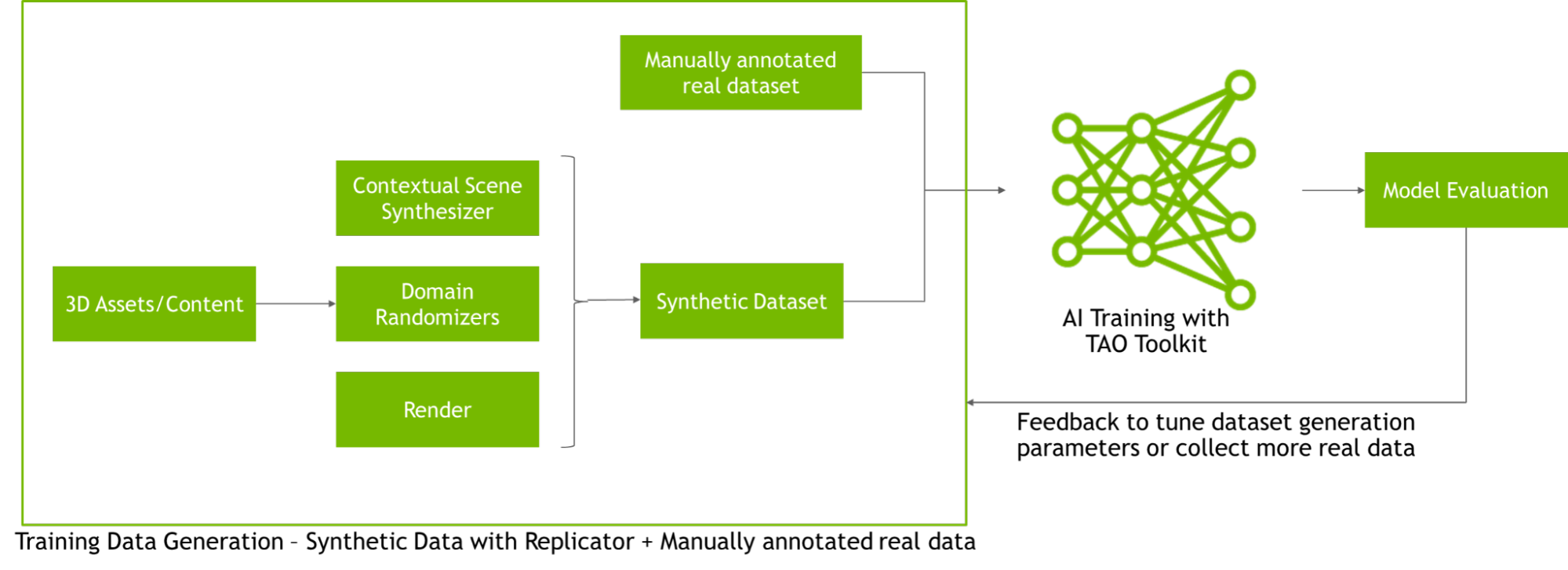
Accelerate existing workflows with Omniverse Replicator and TAO Toolkit
Developers, engineers, and researchers can integrate Omniverse Replicator with existing tools to speed up AI model training. For example, once synthetic data is generated, developers can train their AI models quickly using the NVIDIA TAO Toolkit. The TAO Toolkit leverages the power of transfer learning, for developers to train, adapt, and optimize models for their use-case, without prior AI expertise.
Building applications with Omniverse Replicator
Kinetic Vision is a systems integrator for large industrial customers in retail, intralogistics, consumer manufacturing, and consumer packaged goods. They are developing a new enterprise application based on the Omniverse Replicator SDK to provide high-quality synthetic data for customers as a service.
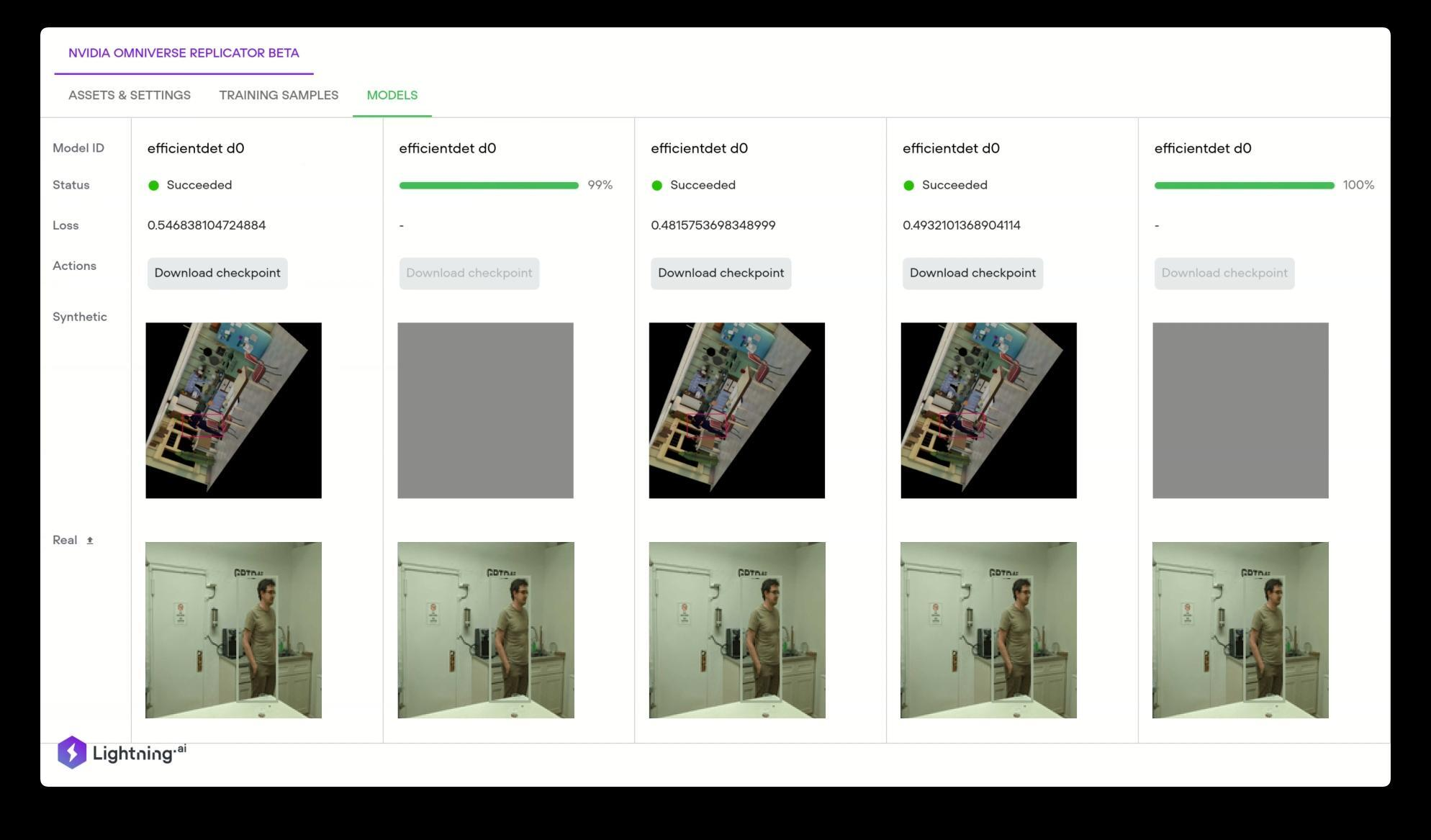
When data required to train deep learning models is unavailable, Omniverse Replicator generates synthetic data, which can be used to augment limited datasets. Lightning AI (formerly Grid.AI) uses the NVIDIA Omniverse Replicator to generate physically accurate 3D datasets based on Universal Scene Description (USD) that can be used to train these models. A user can simply drag and drop your 3D assets and after the dataset is generated a user can choose from the latest state-of-the-art computer vision models to train automatically on the synthetic data.
At NVIDIA, the Isaac Sim and DRIVE Sim teams leveraged the Omniverse Replicator SDK to build domain-specific synthetic generation tools, the Isaac Replicator for robotics, and DRIVE Replicator for autonomous vehicle training. The Omniverse Replicator SDK provides a core set of functionalities for developers to build any domain specific synthetic data generation pipeline using all the benefits offered by the Omniverse platform. With Omniverse as a development platform for 3D simulation, rendering, and AI development capabilities, Replicator provides a custom synthetic data generation pipeline.

Availability
The Omniverse Replicator SDK is now available in Omniverse Code, downloadable from the Omniverse Launcher.
For more information about Replicator, visit the Replicator documentation and watch the Replicator tutorials. Join our Discord Server to chat with the community and check out our Discord channel on synthetic data generation.
Learn more by diving into the Omniverse Resource Center, which details how developers can build custom applications and extensions for the platform.
Follow Omniverse on Instagram, Twitter, YouTube, and Medium for additional resources and inspiration. Check out the Omniverse forums for expert guidance.
