Machine learning at scale can deliver powerful, predictive capabilities to millions of users, but it hinges on overcoming two key challenges across on-prem or cloud infrastructure – speeding up pre-processing of massive volumes of data and accelerating compute intensive model training.
To tackle these challenges, we started with the popular gradient boosting library XGBoost as it provides a fast and accurate way to solve a broad range of data science problems. Our first release in June of XGBoost4J-Spark enabled training and inferencing of XGBoost models across Apache Spark nodes, making it a leading mechanism for distributed Machine Learning for enterprises. While ease of building and deployment were key objectives of the first release, our latest second release is all about performance, efficient GPU memory utilization and PySpark APIs.
Higher Performance at Lower Cost
We benchmarked the latest RAPIDS-Spark XGBoost4j release on both on-prem Spark cluster (yarn) and on AWS cloud, and the results are remarkable:
On-Prem: Performance vs TCO

The details of our on-prem setup with cost calculation are listed in the table below.

AWS Cloud: Performance vs TCO

The details of AWS setup are listed below, with cost calculations.

Key features
- New PySpark XGBoost API for Python loving Data Scientists
- Sample Notebooks on our documents webpage
- Support for ORC input data format, in addition to CSV and parquet file formats. Read a single input file and partition across multi GPUs for training. This essentially allows any number/size of supported input file formats to be divided up evenly among the different training nodes.
- GPU-accelerated training: We have improved XGBoost training time with a dynamic in-memory representation of the training data that optimally stores features based on the sparsity of a dataset rather than a fixed in-memory representation based on the largest number of features amongst different training instances. In addition, we have built decision trees using gradient pairs that can be reused to save memory and prevent copies to increase performance.
- Efficient GPU memory utilization: XGBoost requires that data fit into memory which creates a restriction on data size using either a single GPU or distributed multi-GPU multi-node training. The latest release has improved GPU memory utilization by 5X, i.e., users now can now train with data that is five times the size as compared to the first version. This is one of the critical factors to improve total cost of training without impacting performance.
- Finally, we have enhanced logging features for ease of debugging.
How to get the latest version?
The latest GPU-accelerated XGBoost artifacts are available at a public maven repo. You simply need to add the following dependency in your pom.xml. Classifier enables you to select the JAR based NVIDIA CUDA version.
<dependency>
<groupId>ai.rapids</groupId>
<artifactId>xgboost4j-spark</artifactId>
<version>${xgboost.version}</version>
<classifier>${xgbClassifier}</classifier>
</dependency>You can find the updated RAPIDS Spark XGBoost API documentation and new Pyspark examples in our GitHub repository. For users to get started quickly, we have “Getting Started Guides” for
What’s next?
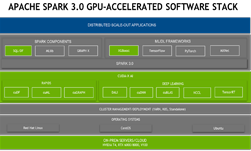
The next important milestone on our journey is the release of Apache Spark 3.0, which will empower both big-data and AI workload in CPU/GPU clusters. The GPU-Accelerated stack below illustrates how NVIDIA technology will accelerate Spark 3.0 applications without application code change.

Working with Apache Spark community, we have made great strides towards realizing Spark 3.0 vision by designing and implementing three key enhancements: columnar processing proposal (SPARK-27396), GPU-aware scheduling (SPARK-24615), and stage-level resource scheduling (SPARK-27495). All these SPIPs (Spark Performance Improvement Proposals) have been approved, and we are on schedule to have all of them implemented by Spark 3.0 release. As a part of Project Hydrogen, these enhancements will unite the world of Big Data and AI.
AI framework users will be able to leverage Spark for reading data from multiple data sources such as SQL, streaming, etc. and use the standardized data format to exchange data between Spark and AI frameworks on GPUs. The impressive acceleration and cost-saving demonstrated by Spark XGBoost for GPU serve as precursor to the great potential of AI workload on Spark clusters. With stage-level resource scheduling, users will be able to specify task and executor resource requirements at the stage level for Spark applications. For example, if a user has two stages in the pipeline – ETL and ML – each stage can acquire the necessary resources/executors (CPU or GPU) and schedule tasks based on the per stage requirements.
We are excited to announce that our first release of GPU-accelerated Spark SQL and DataFrame library will be available in concert with the official release of Apache Spark 3.0. It will enable multi-fold acceleration of select SQL queries and bring substantial cost benefits to enterprises. To learn more about our preliminary results and catch a glimpse of a first-ever Spark ETL-on-GPU demo, join us at our Spark Summit session in Amsterdam on Oct 17.
Authors
Karthikeyan Rajendran is the Product Manager for NVIDIA’s Spark team. Previously, he was the lead Product Manager for GE’s Industrial IOT Platform, Predix. Prior to GE, he worked in both various technical and strategy roles at companies such as Qualcomm, EMC and ZS Associates. Karthikeyan has an MBA from UCLA’s Anderson School of Management. He also earned his Master of Science degree in Electrical Engineering from Arizona State University.

Bobby Wang is a software engineer working on GPU acceleration for Spark applications. Bobby holds an MS in Communication Engineering from the University of Electronic Science and Technology of China.

Chuanli Hao is a software engineer working on accelerating Apache Spark applications on GPUs. Chuanli holds a BS in computer science from Fudan University.

Liangcai Li is a software engineer in NVIDIA’s Spark team. He joined NVIDIA in 2013 and now is working on GPU acceleration for Spark applications. Liangcai Li holds an MS in Communication Engineering from Huazhong University of Science & Technology.

