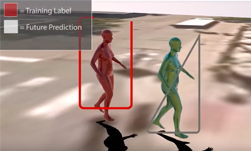
University of Michigan researchers recently published a paper describing a new deep learning based-algorithm that can predict the future location of a pedestrian, along with their pose and gait.
“The proposed network is able to predict poses and global locations for multiple pedestrians simultaneously for pedestrians up to 45 meters from the cameras,” the researchers stated in their paper.
The work focuses on two aspects that are key to accelerating research in this field; predicting a full-body 3D mesh and doing so for multiple people simultaneously within an urban-intersection environment, and predicting or forecasting 3D pedestrian pose and location in future frames of a sequence.
A person’s body language can deliver valuable insights about what they might do. Are they looking over their shoulder, or are they looking back to turn around? Are they signaling to someone in the car, or looking at someone on the other side of the road?
The researchers hope that by designing a computer vision system that understands subtle cues in human behavior, they can develop a more robust computer vision system for robotics and autonomous vehicles.
For training, the team used two NVIDIA TITAN X GPUs, with the cuDNN-accelerated Keras deep learning framework, to train a bio-LSTM neural network on the PedX dataset which includes real intersections in Ann Arbor, Michigan, and a separate evaluation dataset captured in a controlled outdoor environment a with motion capture system.
For inference, the team also uses the GPUs. “Our proposed network was implemented in Python 3.6. With the current unoptimized code, the prediction takes approximately 1ms for each person in each frame.
The researchers say they will expand their work to include real-time motion capture in autonomous vehicle applications.
A paper describing the technique was recently published on IEEE Robotics and Automation Letters and on Arxiv (PDF).