
Speech and natural language processing (NLP) have become the foundation for most of the AI development in the enterprise today, as textual data represents a significant portion of unstructured content. As consumer internet companies continue to improve the accuracy of conversational AI, search, and recommendation systems, there is an increasing need for processing rich text data efficiently and effectively.
However, one of the key challenges for achieving the desired accuracy lies in understanding complex semantics and underlying user intent, and effectively extracting relevant information from a variety of sources such as user queries and documents. In recent years, the rapid development of deep learning models has bolstered improvements for a variety of NLP tasks, indicating the vast potential for further improving the accuracy of search and recommender systems.
In this post, we introduce DeText, a state-of-the-art, open-source NLP framework developed at LinkedIn for text understanding, followed by a summary of the GPU-accelerated BERT assets available for you to jumpstart your NLP development.
Introducing DeText

As the world’s largest professional network, LinkedIn leverages NLP to help connect its 722+ million members. DeText is a framework for intelligent text understanding that was built to provide flexible support across multiple NLP applications and practical designs for ease in deployment.
DeText is applied across a variety of applications at LinkedIn. Most notably, it’s brought significant improvements across people search, job search, and help center search. We’ve also seen significant online improvement in classification tasks such as query intent classification, and sequence completion tasks such as query autocomplete.
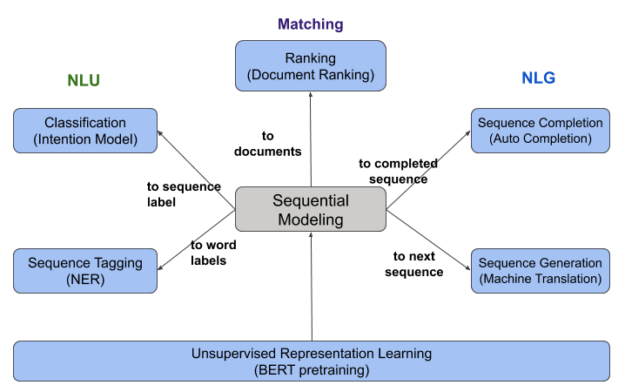
As Figure 1 shows, we define the fundamental NLP tasks in search and recommender systems across six different categories:
- Classification (intent model)
- Sequence tagging (NER)
- Ranking (document ranking)
- Sequence completion (auto-completion)
- Sequence generation (machine translation)
- Unsupervised representation learning (BERT pretraining)
These deep NLP tasks play important roles in the search and recommendation ecosystem and are crucial in improving various enterprise applications. DeText was developed to provide a unified technical solution for supporting these NLP tasks in search and recommendation. Currently, DeText can support ranking, classification, and sequence completion—three of the six fundamental tasks.
In July 2020, DeText was open-sourced on GitHub to benefit the broader NLP community. We also presented DeText at a hands-on tutorial at KDD 2020 sharing how to best apply DeText. The work has resulted in three papers:
- DeText: A Deep Text Ranking Framework with BERT (recognized as the best paper in the applied research track at CIKM 2020)
- Efficient Neural Query Auto Completion (CIKM 2020)
- Deep Search Query Intent Understanding (Arxiv preprint)
Combining ranking and semantic meaning
Ranking is one of the most fundamental components of search and recommender systems, whether it’s ranking feed content and ads (Facebook), web pages (Google), movies (Netflix), jobs (LinkedIn), or products (Amazon), to name a few examples. A common theme across these product offerings is the role of text data. For example, given a particular query/attribute, user profile, and a list of assets, the product ranks the most relevant documents in descending order. Therefore, a successful ranking model must understand the semantics of text data and identify similar words or disambiguate word-sense.
Recent developments in deep learning-based NLP technologies have greatly deepened the understanding of text semantics using neural networks like convolutional neural networks (CNN) and long short-term memory (LSTM). To further enhance contextual modeling, Google’s BERT (Bidirectional Encoder Representations from Transformers) has been used to show significant improvements in various NLP tasks over existing techniques.
However, applying BERT in ranking is a nontrivial task. First, there is no standard on how to leverage BERT efficiently and effectively. Second, existing approaches generally compute query and document embeddings together. This does not support document embedding precomputing and isn’t feasible for integration with commercial search engines and recommender systems due to concerns around online latency. With DeText, we can successfully exploit pretrained BERT models for ranking in a production environment. DeText is also extensible, meaning that multiple text encoder methods are available such as CNN, LSTM, or BERT.
DeText provides a design to support neural ranking with the following advantages:
- Support for state-of-the-art semantic understanding models (CNN/LSTM/BERT).
- Balance between efficiency and effectiveness.
- High flexibility on module configurations.
DeText framework architecture
One important design principle that we wanted to incorporate in DeText is to help you achieve an optimal balance between efficiency and efficacy to meet the industry standard of training and serving large-scale AI models to products. For efficiency, we use a representation-based modeling structure that enables document embedding precomputing, which saves on the volume of online computations to be processed. For efficacy, clients can choose the state-of-the-art text encoders and leverage them in end-to-end training for specific applications. In addition, the existing handcrafted features are carefully handled and combined with deep features to maximize relevance performance.
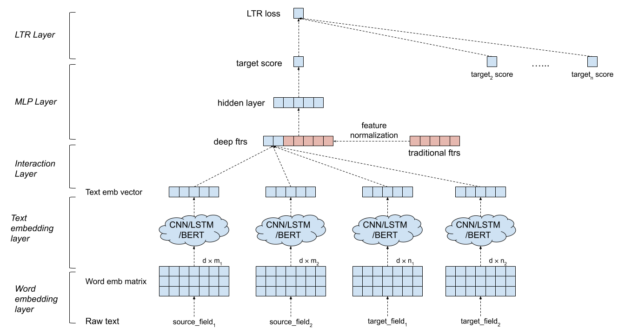
Figure 2 shows that a DeText ranking model first computes the semantic relatedness between the sources and the targets. These semantic features are then combined with the hand-crafted traditional features to generate a final score for the source-target relevance. There are multiple components in a DeText ranking model providing high flexibility in configuration:
- Input text data: The input text data are generalized as source and target texts. The source can be queries in search systems or user profiles in recommender systems. The target can be the documents to be indexed. Both source and target can have multiple fields.
- Word embedding layer: The sequence of words is transformed into an embedding matrix.
- Text embedding layer: DeText provides the options of CNN, LSTM, or BERT to extract text embedding. CNN and LSTM are provided as a lightweight solution with small latency. In other cases where complicated semantic meaning extraction is needed, BERT can be used.
- Interaction layer: Multiple interaction methods are available to compute deep features from the source and the target embeddings (cosine similarity, Hadamard product, concatenation, and so on).
- Existing hand-crafted feature processing: Feature normalization and element-wise rescaling are applied to the handcrafted traditional features.
- MLP layer: The deep features from the interaction layer are concatenated with the traditional features. These features are fed into a multilayer perceptron (MLP) layer to compute the final target score. The hidden layer in MLP can extract the non-linear combination of deep features and traditional features.
- LTR layer: The last layer is the learning-to-rank layer that takes multiple target scores as input. DeText provides the flexibility of choosing pointwise, pairwise, or listwise LTR, as well as with Lambda rank. In applications focusing on relative ranking, either pairwise or listwise LTR can be used. When modeling the click probability is important, pointwise LTR can be used.
Pretraining BERT models on LinkedIn data
BERT is an important component of DeText. One way that we’ve optimized BERT for usage at LinkedIn is by pretraining the models on LinkedIn-specific data to create LiBERT, a pretrained variant of BERT. There are two key benefits of this approach:
- Pretraining on relevant data improves the relevance performance.
- Choosing a more compact model structure that leads to reduced online inference latency.
Table 1 shows that, with the LiBERT model, you can significantly improve the fine-tuning performance of three LinkedIn tasks. This improvement is attributable to the genre of pretraining data: in-domain data compared with general domain data.
| Tasks | Query Intent (Accuracy) | People Search (NDCG@10) | Job Search (NDCG@10) |
| Improvement | +0.43% | +1.3% | +1.4% |
BERT pretraining is costly and can take several days, or even weeks, to finish. We collaborated with NVIDIA on using the latest optimizer, LAMB, and exploited the limit of GPUs during BERT pretraining. To further accelerate the process, we also adopted several other training techniques, such as gradient accumulation. On LinkedIn datasets, we reduced the LiBERT (6 layers, 34M parameters) pretraining time from 40 hours to 2 hours with more GPUs and a larger batch size in LAMB.
NVIDIA BERT
Transformer models have achieved higher accuracy than ever before on NLP tasks and outperformed on benchmarks such as GLUE. BERT has grabbed the interest of the entire NLP community and sparked a wave of new submissions, each taking the BERT transformer approach and modifying it.
At NVIDIA, we have an optimized version of BERT based on the Hugging Face implementation—including automatic mixed-precision training (AMP) with Tensor Cores on V100 and A100 for higher throughput, and layer-wise adaptive optimizers such as LAMB. These allow you to pretrain BERT models with a large batch size across multi-GPU and multi-node systems without losing accuracy. The implementation includes multi-GPU training with Horovod for TF and DDP for PyTorch, and integration of libraries such as NCCL for distributed training. The fine-tuning and inference examples use Standard Question and Answering (SQuAD v1.1) dataset. The inference process includes optimizing and running the BERT models using TensorRT library and includes deploying these models using Triton Inference Server. Triton, along with TensorRT, enables you to deliver low-latency and high-throughput BERT inference, while optimizing efficiency of underlying GPU and CPU infrastructures.
The BERT GitHub repos, TensorFlow and PyTorch, contain training and inference recipes for you to get started quickly on pretraining, fine-tuning, and deploying models for inference.
If you are wondering about the BERT performance on GPUs, Figures 3-5 show some results from recent testing.
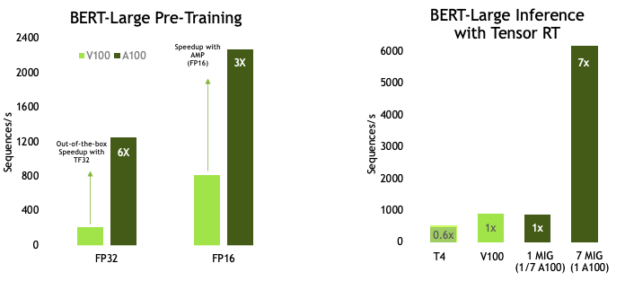
BERT Pretraining Throughput using Pytorch including (2/3)Phase 1 and (1/3)Phase 2 | Phase 1 Seq Len = 128, Phase 2 Seq Len = 512 V100: DGX-1 Server with 8xV100 using FP32 and FP16 precision A100: DGX A100 Server with 8xA100 using TF32 precision and FP16 |
BERT-Large Inference | T4: TRT 7.1, Precision = INT8, Batch Size =256, V100: TRT 7.1, Precision = FP16, Batch Size =256 | A100 with 7 MIG instances of 1g.5gb : Pre-production TRT, Batch Size =94, Precision = INT8 with Sparsity
Pretraining of BERT-large on the latest Ampere-based GPU (A100), shows a 6x out-of-box speedup on FP32, compared to V100. TensorFloat-32 (TF32) is a new math mode in A100 GPUs for handling the matrix math, also called tensor operations, used at the heart of AI workloads. TF32 running on Tensor Cores in A100 GPUs can deliver up to 10x speedups over FP32 on Volta GPUs, without code changes. Using automatic mixed precision for FP16 training On mixed-precision training, we see 3x speedup in performance when comparing A100 compared to V100. On the inference side, A100 can deliver up to 7x speedup on BERT over T4.
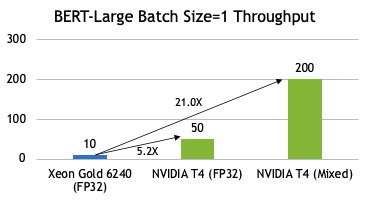
Intel Xeon Gold 6240: OpenVINO, Precision = FP32 (OpenVINO does not support INT8), Seq Length = 384, Batch Size =1, 12 NVIDIA T4: TRT 7.0.0.11, Precision = FP32, INT8, Seq Length = 128, Batch Size =1, 32
If you are curious about GPU inferencing performance as compared to CPU, especially for real-time, low-batch use cases, see Figure 4. On average, there is more than 5x gap on inferencing with FP32 precision, and about 21x when you use lower precision such as INT8.
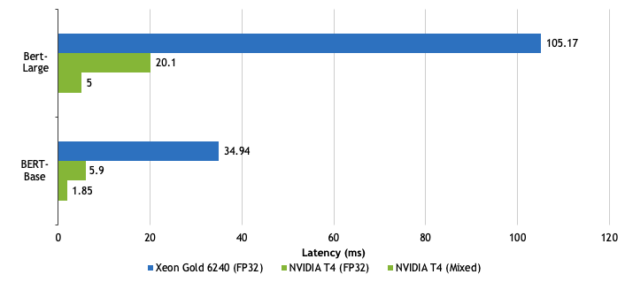
Intel Xeon Gold 6240: OpenVINO, Precision = FP32 (OpenVINO does not support INT8), Seq Length = 384, Batch Size =1 NVIDIA T4: TRT 7.0.0.11, Precision = FP32, INT8, Seq Length = 128, Batch Size =1
For many online inference use cases, the latencies must be under 10ms so that the responses appear in real time. Figure 5 shows the BERT inference comparisons. On a T4 with mixed-precision, you can achieve latency in the order of 5ms for BERT-large.
We have also recently added Jupyter notebook demos to walk you step-by-step on best practices for BERT fine-tuning and inference optimizations. These workshop notebooks can be downloaded from NGC. The training demos show fine-tuning on TensorFlow and quickly improving performance using automatic mixed precision and the TensorFlow XLA compiler.
We also show you how to profile the model using DLProf. DLProf is an important tool that can be used to debug any performance-related bugs with a model. The inference notebook explains importing a trained model and then building and running optimized inference for batch and streaming use cases using TensorRT.
First, pull the container:
docker pull nvcr.io/nvidia/bert_workshop:20.03
Next, run the container:
docker run --gpus all --rm -it \ -p 8888:8888 \ -p 6006:6006 \ nvcr.io/nvidia/bert_workshop:20.03
Then, access JupyterLab by opening http://localhost:8888 in a browser in your local machine. You can see multiple folders such as introduction, training, and inference.
Summary
In this post, we discussed how deep learning-based NLP technologies are driving better understanding of text semantics, which is key to any ranking model. We introduced DeText, an open-source NLP framework and showed how it has improved accuracy and performance of a variety of search and recommendation workloads at LinkedIn. And finally, we walked through BERT enhancements done at NVIDIA and some of the key assets available for you to get started.
Check out DeText on Github and get started on GPU-accelerated BERT training and inference recipes (Tensorflow and PyTorch). Learn the best practices on fine-tuning and inference deployment by downloading ready-to-use Jupyter notebook demos from NGC.
