
Given the parallel nature of many data processing tasks, it’s only natural that the massively parallel architecture of a GPU should be able to parallelize and accelerate Apache Spark data processing queries, in the same way that a GPU accelerates deep learning (DL) in artificial intelligence (AI).
NVIDIA has worked with the Apache Spark community to implement GPU acceleration through the release of Spark 3.0 and the open source RAPIDS Accelerator for Spark. In this post, we dive into how the RAPIDS Accelerator for Apache Spark uses GPUs to:
- Accelerate end-to-end data preparation and model training on the same Spark cluster.
- Accelerate Spark SQL and DataFrame operations without requiring any code changes.
- Accelerate data transfer performance across nodes (Spark shuffles).

Data preparation and model training on Spark 2.x
GPUs have been responsible for the advancement of DL and machine learning (ML) model training in the past several years. However, 80% of a data scientist’s time is spent on data preprocessing.
Preparing a data set for ML requires understanding the data set, cleaning and manipulating data types and formats, and extracting features for the learning algorithm. These tasks are grouped under the term ETL (extract, transform, load). ETL is often an iterative, exploratory process.
As ML and DL are increasingly applied to larger datasets, Spark has become a commonly used vehicle for the data preprocessing and feature engineering needed to prepare raw input data for the learning phase. Because Spark 2.x has no knowledge about GPUs, data scientists and engineers perform the ETL on CPUs, then send the data over to GPUs for model training. That’s where the performance really is. As data sets grow, the interactivity of this process suffers.
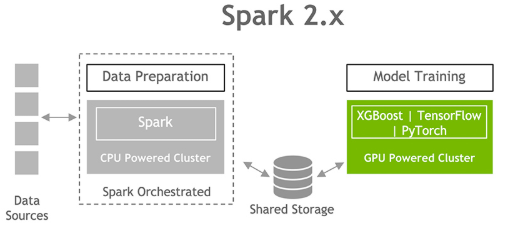
Accelerated end-to-end data analytics and ML pipelines
The Apache Spark community has been focused on bringing both phases of this end-to-end pipeline together, so that data scientists can work with a single Spark cluster and avoid the penalty of moving data between phases.
Apache Spark 3.0 represents a key milestone, as Spark can now schedule GPU-accelerated ML and DL applications on Spark clusters with GPUs, removing bottlenecks, increasing performance, and simplifying clusters.
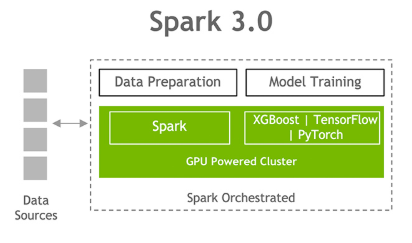
Figure 3 shows the complete stack for this accelerated data science.

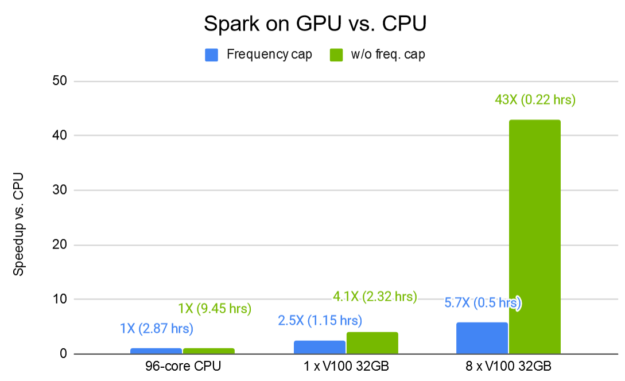
Figure 4 shows a measure of data preprocessing time improvement for Spark on GPUs. The Criteo Terabyte click logs public dataset, one of the largest public datasets for recommendation tasks, was used to demonstrate the efficiency of a GPU-optimized DLRM training pipeline. With eight V100 32-GB GPUs, processing time was sped up by a factor of up to 43X compared to an equivalent Spark-CPU pipeline.
Next, we cover the key advancements in Apache Spark 3.0 that contribute to transparent GPU acceleration:
- The new RAPIDS Accelerator for Apache Spark 3.0
- RAPIDS-accelerated Spark SQL/DataFrame and shuffle operations
- GPU-aware scheduling in Spark
RAPIDS Accelerator for Apache Spark
RAPIDS is a suite of open-source software libraries and APIs for executing end-to-end data science and analytics pipelines entirely on GPUs, allowing for a substantial speed up, particularly on large data sets. Built on top of NVIDIA CUDA and UCX, the RAPIDS Accelerator for Apache Spark enables applications to take advantage of GPU parallelism and high-bandwidth memory speed with no code changes, through the Spark SQL and DataFrame APIs and a new Spark shuffle implementation.
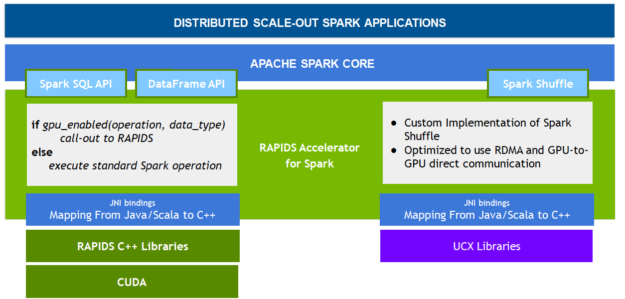
RAPIDS-Accelerated Spark SQL and DataFrame
RAPIDS offers a powerful GPU DataFrame based on Apache Arrow data structures. Arrow specifies a standardized, language-independent, columnar memory format, optimized for data locality, to accelerate analytical processing performance on modern CPUs or GPUs. With the GPU DataFrame, batches of column values from multiple records take advantage of modern GPU designs and accelerate reading, queries, and writing.

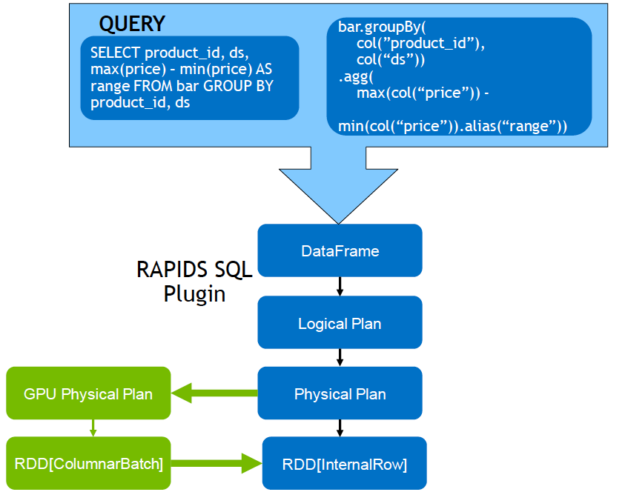
For Apache Spark 3.0, new RAPIDS APIs are used by Spark SQL and DataFrames for GPU-accelerated memory-efficient columnar data processing and query plans. When a Spark query executes, it goes through the following steps:
- Creating a logical plan
- Transforming the logical plan to a physical plan by the Catalyst query optimizer
- Generating code
- Executing the tasks on a cluster
With the RAPIDS accelerator, the Catalyst query optimizer has been modified to identify operators within a query plan that can be accelerated with the RAPIDS API, mostly a one-to-one mapping. It also schedules those operators on GPUs within the Spark cluster when executing the query plan.
With a physical plan for CPUs, the DataFrame data is transformed into RDD row format and usually processed one row at a time. Spark supports columnar batch, but in Spark 2.x only the Vectorized Parquet and ORC readers use it. The RAPIDS plugin extends columnar batch processing on GPUs to most Spark operations.
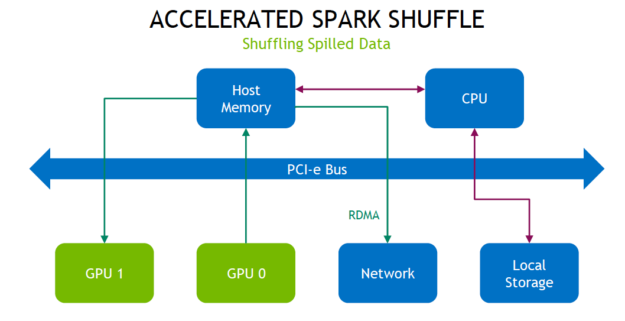
RAPIDS-accelerated Spark shuffles
Spark operations that sort, group, or join data by value must move data between partitions, when creating a new DataFrame from an existing one between stages, in a process called a shuffle.
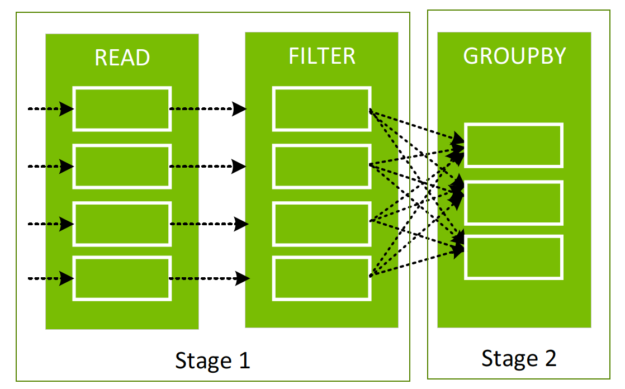
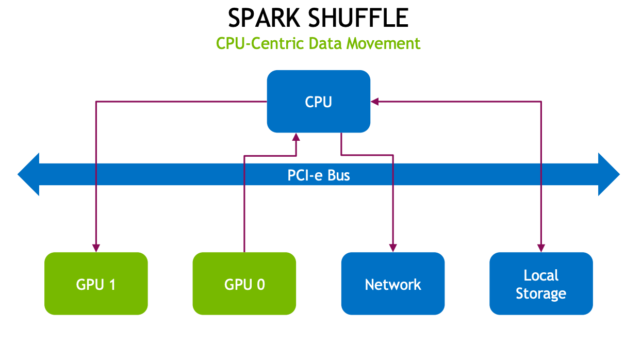
Shuffles first write data to local disk and then transfer data across the network to partitions on other CPUs or GPUs. Shuffles are expensive in terms of CPU, RAM, disk, network, and PCI-e bus traffic as they involve disk I/O, data serialization, and network I/O.
The new Spark shuffle implementation is built upon the GPU-accelerated Unified Communication X (UCX) library to dramatically optimize the data transfer between Spark processes. UCX exposes a set of abstract communication primitives which utilize the best of available hardware resources and offloads, including RDMA, TCP, GPUs, shared memory, and network atomic operations.
In the new shuffle process, as much data as possible is first cached on the GPU. This means no shuffling of data for the next task on that GPU. Next, if GPUs are on the same node and connected with NVIDIA NVLink high-speed interconnect, data is transferred at 300 GB/s. If GPUs are on different nodes, RDMA allows GPUs to communicate directly with each other, across nodes, at up to 100 Gb/s. Each of these cases avoids traffic on the PCI-e bus and CPU.
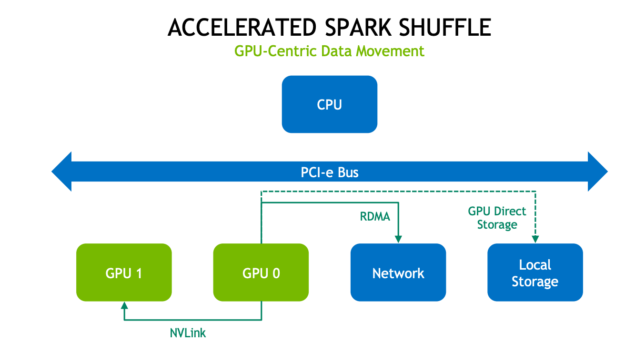
If the shuffle data cannot all be cached locally, it is first pushed to host memory and then spilled to disk when that is exhausted. Fetching data from host memory avoids PCI bus traffic by using RDMA transfer.
Accelerated shuffle results
Figure 12 shows a measure of how much faster the new Spark shuffle implementation runs, with an inventory pricing query running at 10 terabyte scale with 192 CPU cores and 32 GPUs. The standard Spark-CPU shuffle took 228 seconds compared to 8.4 seconds for the new shuffle using GPUs with UCX.
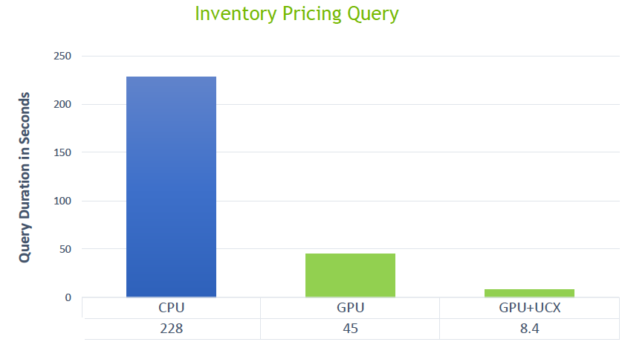
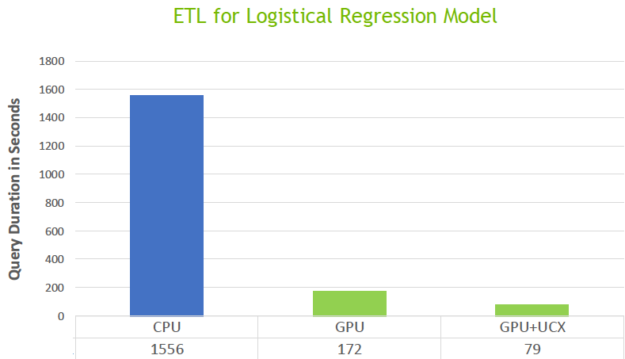
Figure 13 shows the results of an ETL query shuffling 800 GB of data that spills to disk. Using GPUs with UCX took 79 seconds compared to 1,555 for CPUs.
GPU-aware scheduling in Spark
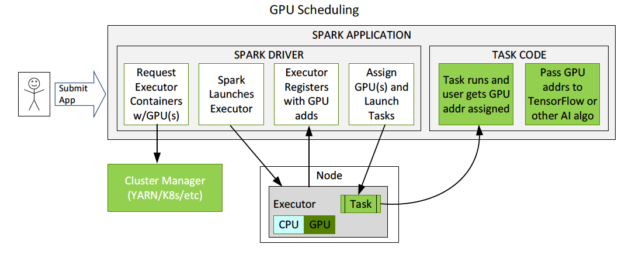
GPUs are now a schedulable resource in Apache Spark 3.0. This allows Spark to schedule executors with a specified number of GPUs, and you can specify how many GPUs each task requires. Spark conveys these resource requests to the underlying cluster manager, Kubernetes, YARN, or standalone. You can also configure a discovery script to detect which GPUs were assigned by the cluster manager. This greatly simplifies running ML applications that need GPUs, as you previously had to work around the lack of GPU scheduling in Spark applications.
Figure 14 shows an example of a flow for GPU scheduling. The user submits an application with a GPU resource configuration discovery script. Spark starts the driver, which uses the configuration to pass on to the cluster manager, to request a container with a specified amount of resources and GPUs. The cluster manager returns the container. Spark launches the container. When the executor starts, it runs the discovery script. Spark sends that information back to the driver and the driver can then use that information to schedule tasks to GPUs.
Next steps
In this post, we discussed how the new RAPIDS Accelerator for Apache Spark enables GPU acceleration of end-to-end data analytic pipelines, Spark SQL operations, and Spark shuffle operations.
- For more information about accelerating Apache Spark 3.0 with RAPIDS and GPUs, watch the GTC 2020 GTC 2020 and Deep Dive into GPU Support in Apache Spark 3x Spark AI Summit sessions.
- To dive even deeper into Apache Spark 3.0, download the free Apache Spark 3.0 ebook.
- To learn more about the Apache Spark 3.0 release, visit the Apache Software Foundation.
- To access the RAPIDS Accelerator for Apache Spark and the getting started guide, visit the nvidia/spark-rapids GitHub repo.
- To see a side-by-side comparison of the performance of a CPU cluster with that of a GPU cluster on the Databricks Platform, watch the Spark 3 Demo: Comparing Performance of GPUs vs. CPUs demo.
