
Apache Spark has emerged as the standard framework for large-scale, distributed, data analytics processing. NVIDIA worked with the Apache Spark community to accelerate the world’s most popular data analytics framework and to offer revolutionary GPU acceleration on several leading platforms, including Google Cloud, Databricks, and Cloudera. Now, Amazon EMR joins the list of leading platforms, making it easy and cost-effective for you to launch scalable, cloud-managed Apache Spark clusters with NVIDIA GPU acceleration.
This post shares how to combine the powers of Apache Spark 3, EMR, and NVIDIA GPUs, to improve performance and reduce costs to process and analyze vast amounts of data. In this post, you learn about the following:
- Speeding up data processing and machine learning with Apache Spark, EMR, the RAPIDS Accelerator for Apache Spark, and NVIDIA GPU instances
- Performance comparisons for using EMR, Spark, the RAPIDS Accelerator for Apache Spark, and NVIDIA GPUs compared to CPUs
- Creating an EMR cluster with Spark, the RAPIDS Accelerator, and NVIDIA GPUs in a few clicks
- Setting up Jupyter or Zeppelin notebooks and importing GPU-accelerated Spark examples
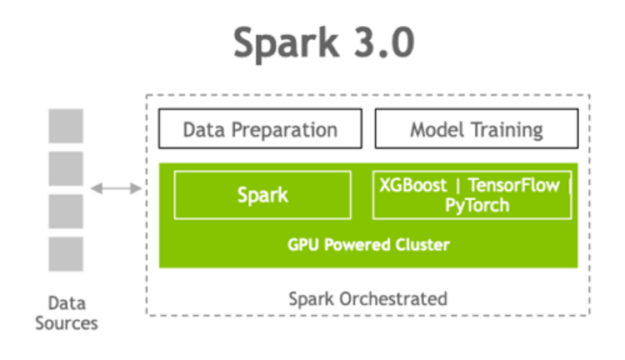
Speeding up data processing and machine learning with Apache Spark and NVIDIA GPUs
GPUs, with their massively parallel architecture, are driving the advancement of deep learning (DL) and machine learning (ML) model training in the past several years. With GPUs, you can exploit data parallelism through columnar data processing instead of traditional row-based reading designed initially for CPUs. This provides higher performance and cost savings.
Apache Spark 3.0 represents a key milestone in this advancement, combining GPU acceleration with large-scale distributed data processing and analytics. Spark 3.0 can now schedule GPU-accelerated ML and DL applications on Spark clusters with GPUs. Also, when combined with the RAPIDS Accelerator for Apache Spark, Spark can now accelerate SQL and DataFrame data processing with GPUs without code changes.
The RAPIDS Accelerator for Apache Spark combines the power of the RAPIDS library and the scale of the Spark distributed computing framework. In addition, RAPIDS integration with XGBoost, and other ML/DL frameworks enables the acceleration of model training and tuning. This allows data scientists and ML engineers to have a unified, GPU-accelerated pipeline for ETL and analytics, while ML and DL applications leverage the same GPU infrastructure, removing bottlenecks, increasing performance, and simplifying clusters.
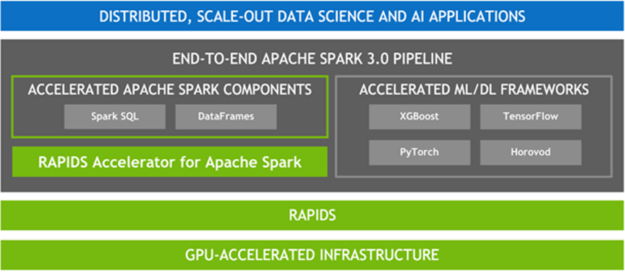
EMR and NVIDIA GPU instances
AWS and NVIDIA are collaborating to deliver powerful, cost-effective, and flexible GPU-based solutions for customers. With EMR release version 6.2.0 and later, you can quickly and easily create scalable and secure clusters with Apache Spark 3.x, the RAPIDS Accelerator, and NVIDIA GPU-powered Amazon EC2 instances with a few clicks on the EMR console. With EMR’s per-second billing and Spot Instances, you can easily run data science pipelines at a massive scale but low cost. Additionally, you can use AWS data stores, Amazon SageMaker, open-source DL and ML tools such as TensorFlow and Apache MXNet, Apache Zeppelin, or Jupyter notebooks, and Apache Livy to enable data scientists to easily and quickly build ETL and ML pipelines and move ML models into production.
Performance comparisons: EMR, Spark plus NVIDIA RAPIDS Accelerator GPU vs. CPU
For experiments to compare CPU and GPU performance for Spark 3.0.1 on EMR, the NVIDIA RAPIDS Accelerator team uses 10 TB of simulated data and queries designed to mimic large-scale ETL from a retail or company, similar to TPC-DS. This comparison was run both on a CPU cluster and a GPU cluster with 3-TB TPC-DS data stored on Amazon S3.
- The CPU cluster consisted of eight instances of m5d.2xlarge as workers and one instance of m5d.xlarge as a master. The CPU cluster costs $3.91 per hour.
- The GPU cluster consisted of eight instances of g4dn.2xlarge as workers, which has one NVIDIA T4 GPU in each instance (the most cost-effective GPU instances in the cloud for ML) and one instance of m5d.xlarge as a master. The GPU cluster costs $6.24 per hour.
In this experiment, the RAPIDS Accelerator team used a query similar to TPC-DS query 97. Query 97 calculates counts of promotional sales and total sales, and their ratio from the web channel for a particular item category and month to customers in a specific time zone. You can see from the Spark Physical plan and DAG for query 97 (Figure 3) that every line of the Physical plan has a GPU prefix attached to it, meaning that every operation of that query runs entirely on the GPU.
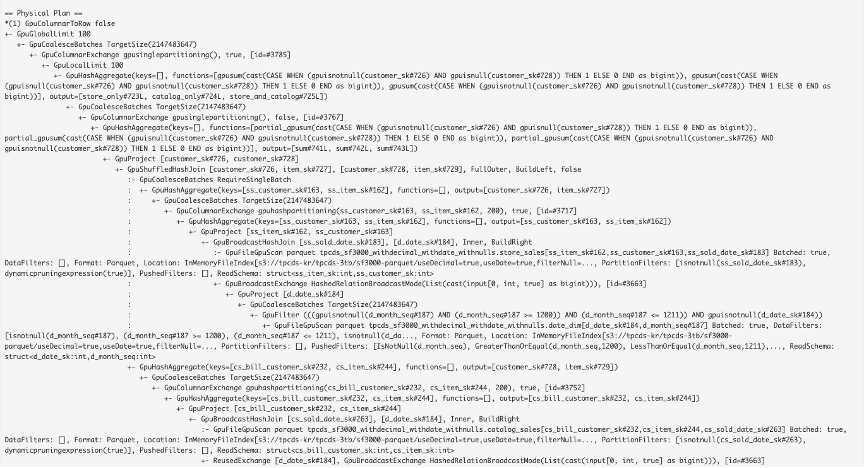
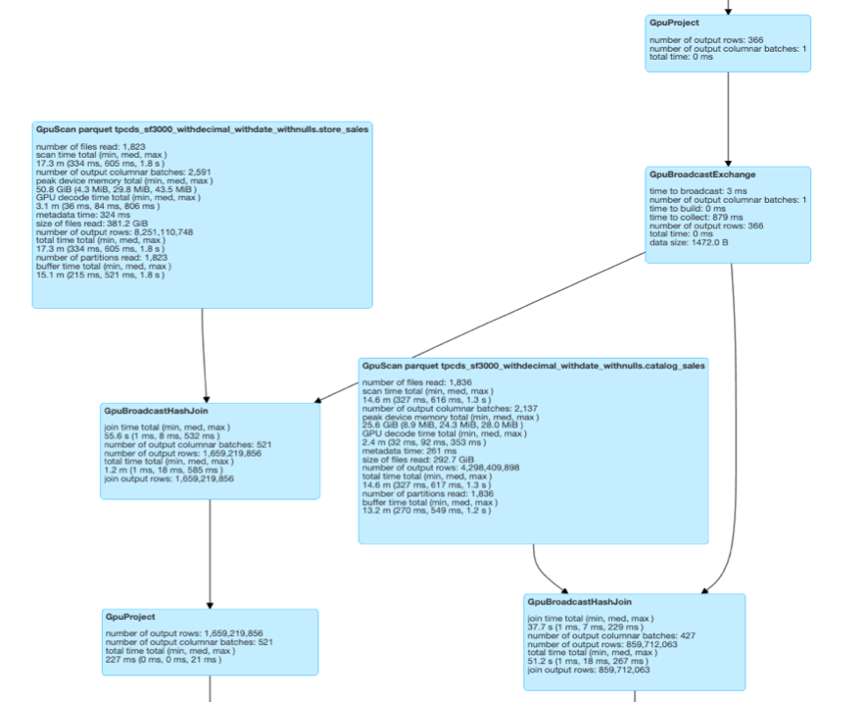
With this query running almost completely on the GPU, processing time was sped up by a factor of up to 2.6x with 39% cost savings compared to running the job on the Spark CPU cluster. There were no tuning nor code changes for this query.
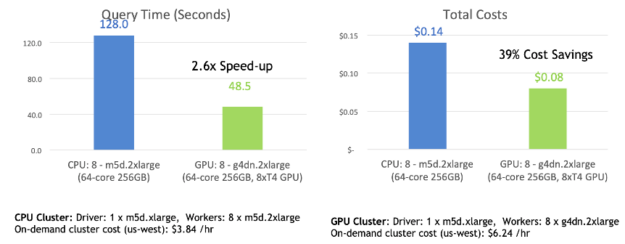
In addition, the NVIDIA RAPIDS Accelerator team has run queries with Spark windowing operators on EMR and seen speeds up to 30x faster on GPU than CPU on large datasets.
Creating an EMR cluster with Spark, the RAPIDS Accelerator for Spark, and NVIDIA GPUs
You can quickly create an EMR cluster with one to thousands of nodes with Spark, the RAPIDS Accelerator, TensorFlow, MXNet, Ganglia monitoring, Jupyter notebooks or other tools with just a few clicks in the EMR console. Before you begin setting up an EMR cluster, make sure that you complete the prerequisites.
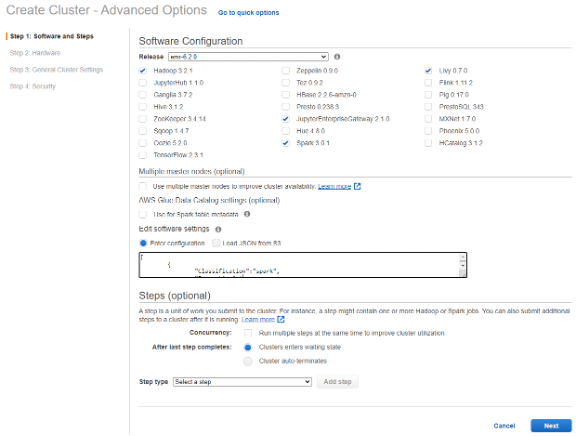
On the EMR console, choose Cluster creation, Go to advanced options, and select EMR 6.2, Spark 3.0.1, and the other frameworks or notebooks to use with Spark. To use EMR notebooks, select Jupyter Enterprise gateway and Livy. Next, for Edit software setting, add the required configurations to enable Spark to use RAPIDS plugin. Optionally, you can have the settings loaded from a file in an S3 bucket. For more information about fine-tuning the plugin configuration settings based on the GPU instance type that you select in the next step, see RAPIDS Accelerator for Apache Spark Configuration.
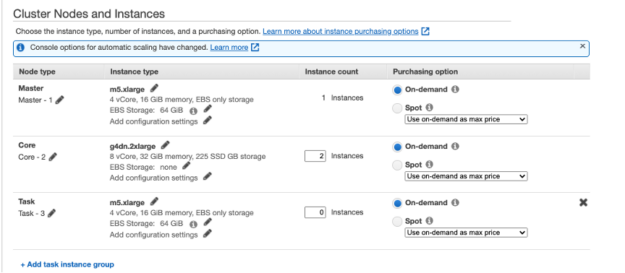
In step 2, you are presented with the page to select the appropriate GPU instance that you need for your Spark cluster. You do not need a GPU on the driver node for the RAPIDS Accelerator plugin.
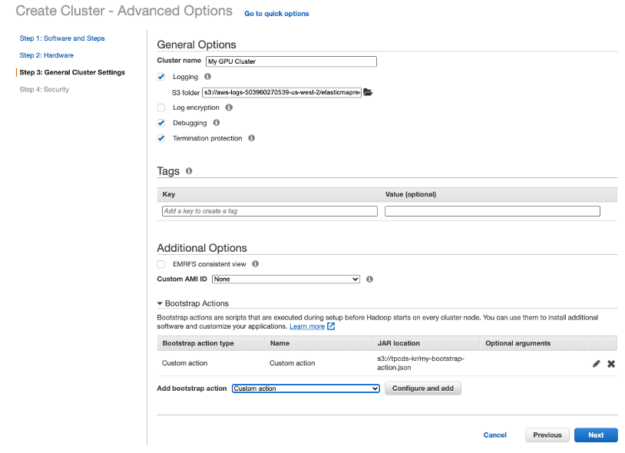
In step 3 on the next page, in order to use YARN on GPU, you must add a bootstrap action script to open cgroups permissions to YARN, this script can also be loaded from a file in an S3 bucket.
In step 4, select the appropriate security settings and choose Create cluster.
After you have created your cluster, you are taken to your cluster management details page and you can see the GPU instances that you selected for your Spark cluster in the Network and Hardware section shown.
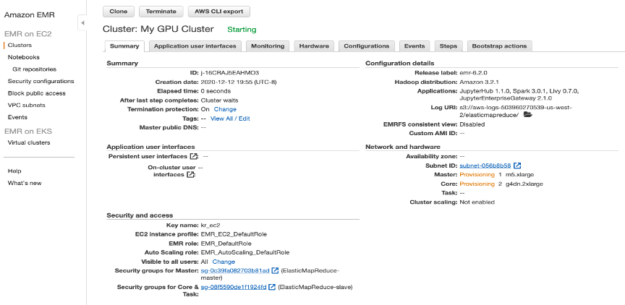
On the Configuration tab, see the RAPIDS Accelerator Spark settings for the GPU cluster (Figure 10).

Accessing the Spark shell
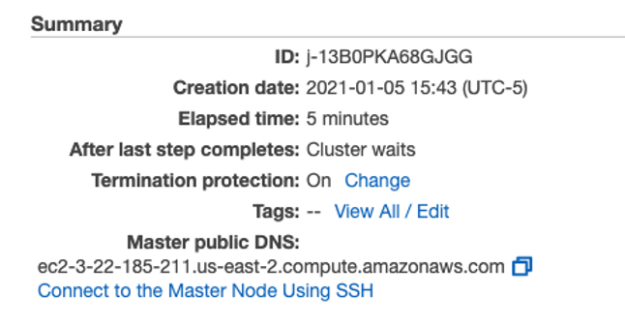
After your cluster has started, you can connect to the Master Node Using SSH as explained in the link under “Master public DNS” in your cluster summary page. After connecting to the master node with SSH, you can access the Spark shell by invoking spark-shell.
Accessing the Zeppelin notebooks web interface
If you selected Zeppelin in your step 1 cluster configuration, you can access the Zeppelin web interface by setting up an SSH tunnel to the master node and a proxy connection. For more information, see the Application user interfaces link on your cluster summary page. After setting up an SSH tunnel and proxy, you can also view web interfaces hosted on EMR Clusters such as YARN and Ganglia.
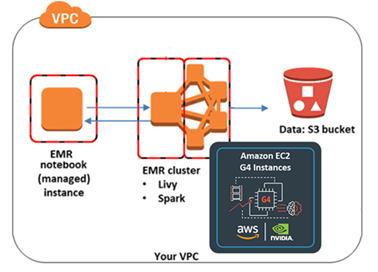
Creating an EMR notebook
An EMR notebook is a serverless Jupyter notebook. Unlike a traditional notebook, the contents of an EMR notebook—visualizations, queries, models, code, and narrative text—are saved in S3 separately from the cluster that runs the code. This provides an EMR notebook with durable storage, efficient access, and flexibility.
To create an EMR notebook, complete the following steps:
- On the EMR console, choose Notebooks, Create notebook.
- For Cluster, choose the existing cluster that you just created, fill out the remaining fields, and choose Create notebook.
- After your workspace notebook is ready, choose either Open in Jupyter or Jupiter Lab.
Running RAPIDS Accelerator for Spark example notebooks
After you have set up either Zeppelin or EMR notebooks, you can download and import some example RAPIDS Accelerator for Apache Spark notebooks:
- The RAPIDS Accelerator for Apache Spark demo mortgage ETL notebook performs data preparation for feature engineering on a 200-GB Fannie Mae loan dataset.
- The post Accelerating Spark 3.0 and XGBoost End-to-End Training and Hyperparameter Tuning and associated notebook walk you through using Apache Spark with GPUs to accelerate and optimize an end-to-end data exploration, ML, and hyperparameter tuning example to predict NYC taxi fares.
- The Spark XGBoost example notebooks and associated post, Improving RAPIDS XGBoost performance and reducing costs with Amazon EMR running EC2 G4 instances demonstrate using Spark with XGBoost GPUs to accelerate ETL and ML on a Fannie Mae loan dataset.
Conclusion
This post shared how you can speed up data-processing pipelines up to 2.6x with 39% cost savings with GPU-accelerated Spark on EMR. With GPUs having a significantly faster training speed over CPUs, your data science teams can tackle larger data sets, iterate faster, and tune models more frequently to maximize prediction accuracy and business value.
For more information, see the following resources:
- Get Started with RAPIDS on Amazon EMR
- Spark XGBoost examples
- Using the NVIDIA Spark-RAPIDS Accelerator for Spark With Amazon EMR release version 6.2.0 and later
- Innovations to Accelerate Spark 3.0 Performance with GPUs and Accelerating Apache Spark 3.0 with GPUs
- Free Apache Spark 3.0 ebook
- Spark 3 Demo: Comparing Performance of GPUs vs. CPUs demo
- Amazon EMR
