
Data processing is increasingly making use of NVIDIA computing for massive parallelism. Advancements in accelerated compute mean that access to storage must also be quicker, whether in analytics, artificial intelligence (AI), or machine learning (ML) pipelines.

The benefits from GPU acceleration are limited if data access dominates the execution time. GPU-based processing drives a higher data access throughput than a CPU-based cluster. With the separation of processing clusters for analytics and AI from data storage systems, accelerating data access is even more critical.
NVIDIA has worked with the Alluxio community to test a high-performance data orchestration system for caching large datasets and data availability for GPU processing. Apache Spark 3.0, the RAPIDS Accelerator for Apache Spark, and Alluxio can be used both for (1) data analytics and business intelligence, or (2) data preprocessing and feature engineering for data science. For model training or inference, Spark and distributed TensorFlow or PyTorch on GPU clusters all benefit from I/O acceleration using a distributed platform-agnostic orchestration layer.
In this post, we look at:
- Architecture using Alluxio Data Orchestration across multiple stages of a data processing pipeline, from Extract Transform Load (ETL) to analytics and AI/ML.
- How to accelerate Spark SQL / Dataframe using the RAPIDS Accelerator for Apache Spark and Alluxio without any code changes.
- Best practices for using Alluxio and RAPIDS Accelerator for Apache Spark.
- Deployment options for GPU accelerated Apache Spark, TensorFlow, or PyTorch with Alluxio.
Unified I/O acceleration for ingest, ETL, analytics, and model training
A typical analytics, ML, or AI pipeline is a sequence of steps from ingestion to data preparation to analytics or AI. Preparing data for model training involves data preprocessing and feature engineering, which we refer to as ETL (extract, transform, load). A similar step is required for data cleansing in analytics pipelines.
Spark SQL and Dataframe APIs are popular choices for data analytics and ETL, both often iterative processes. With the increased adoption of GPUs and larger datasets, processing directly on data sources benefits from a distributed cache to accelerate I/O.
Alluxio’s data orchestration layer can be used as a distributed cache for multiple data sources shared across multiple steps of the data pipeline. Alluxio is agnostic to the platform, whether it’s managed Hadoop or Kubernetes on-premises or in the cloud. The architecture, as shown in Figure 1, is generally applicable to multiple environments with a flexible choice of the data processing technology most suitable for the stage and kind of workload.

I/O Acceleration for Spark SQL and DataFrame with RAPIDS
Apache Spark 3.0 with RAPIDS Accelerator for Apache Spark is able to parallelize computation of a Spark SQL or DataFrame job on a GPU-accelerated cluster. However, a significant portion of such a job is reading the data from a remote data source. If data access is slow, I/O can dominate the end-to-end application runtime.
Processing jobs using Spark SQL and DataFrames can be run on NVIDIA GPUs without any code changes, and benefit from the optimizations included in the RAPIDS Accelerator for Apache Spark. Similarly, using Alluxio as a data source for Spark applications requires no code changes to benefit from I/O acceleration using the data orchestration layer. Figure 2 shows the recommended software stack on GPU enabled instances, with Alluxio utilizing CPUs and local storage media such as NVMe for managing cached data while Spark utilizes GPU resources for computation.

Loading data
Using RAPIDS Accelerator for Apache Spark and Alluxio requires no application changes. The following section discusses two scenarios a user might begin with.
Case A. For an existing user reading data using the Alluxio scheme, no changes are required to use RAPIDS Accelerator for Apache Spark. Data can be loaded into a Spark DataFrame the same way as before with no code changes.
val df = spark.read.parquet("alluxio://ALLUXIO_MASTER_IP:PORT/foo")
Case B. For customers with existing Spark applications but looking to deploy Alluxio and RAPIDS Accelerator for the first time, a Spark configuration parameter is used to map existing storage paths to an Alluxio path.
A user should configure this mapping using a RAPIDS Spark configuration parameter as shown below.
--conf spark.rapids.alluxio.pathsToReplace="gs://foo->alluxio://ALLUXIO_MASTER_IP:PORT/foo"
With the configuration parameter set, no application changes are required for the replaced paths. For example, a Spark DataFrame loaded as below will read data from Alluxio at the path alluxio://ALLUXIO_MASTER_IP:PORT/foo.
val df = spark.read.parquet("gs://foo")
This example assumes that the bucket foo is mounted at location /foo in the Alluxio FileSystem namespace.
Benchmarking results
This section provides insights from an evaluation of the impact of a high performance data orchestration system for caching of large datasets and data availability for GPU processing with RAPIDS Accelerator for Apache Spark and Alluxio. We used nearly 90 NVIDIA Decision Support (NDS) queries and the corresponding dataset derived from a popular data analytics benchmark suite. These benchmark queries operated on a 3 Terabyte (TB) dataset in Parquet format stored in a Google Cloud Storage bucket.
The charts below show that an NVIDIA GPU cluster with Alluxio has a nearly 2x improvement in performance when comparing the total elapsed time across the 90 NDS queries, and 70% better return on investment (ROI) compared to a CPU cluster. Google Cloud Dataproc was used to deploy services on compute instances for both CPU and GPU clusters. The instance configurations used can be found below Figure
Most of these improvements can be attributed to Alluxio’s ability to cache the large datasets, and thereby eliminate the need for repeated access to cloud storage. Data scientists who perform multiple tasks across the data science life cycle such as data ingestion, data preparation and data exploration can benefit from increased data processing capabilities to improve performance and reduce costs.
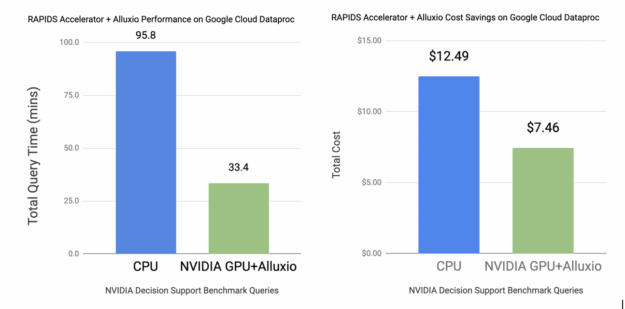
Figure 3: CPU Hardware Config: Master: n1-standard-4, Slave:4 x n1-standard-32 (128 cores, 480GB RAM), GPU Hardware Config: Master: n1-standard-4, Slave:4 x n1-standard-32 (128 cores, 480GB RAM + 16 x T4), CPU Cloud Costs: $7.82/hr (Based on standard pricing on 4 x n1-standard-32 + Dataproc Pricing), GPU Cloud Costs: $13.41/hr (Based on standard pricing on 4 x n1-standard-32 + 16 xT4 + DataProc Pricing)
Best practices with Alluxio and RAPIDS for Spark
Alluxio and RAPIDS Accelerator for Apache Spark provide significant performance improvement with the default configuration, and additional tuning can further boost the return on investment (ROI). This section provides a list of such recommendations.
A. Co-locate the Alluxio worker nodes with Spark worker nodes.
This co-location enables the application to perform short-circuit reads and writes with its local Alluxio worker, which is more efficient than fetching data from remote Alluxio workers.
B. Size cache according to the working set.
It is important to allocate enough space to Alluxio to cache the working set. In fact, it is recommended to have enough cache space for multiple copies of the data that is frequently accessed to reduce overloading a single worker. The replication factors can be controlled through various configuration parameters.
C. Choose the right cache medium choice.
Users can choose between memory (ramdisk) and/or SSD as the cache medium for their Alluxio workers. Unless the data is small enough to fit in memory and the data needed for each query is small, it is often beneficial to deploy with the more economical SSD as the caching layer. This can significantly reduce the cost of the cluster and improve the total cost of ownership (TCO) as a result.
D. Configure concurrency in RAPIDS Spark.
The concurrency for task execution in Spark is controlled by the number of tasks per executor. With RAPIDS for Spark, there is an additional parameter called spark.rapids.sql.concurrentGpuTasks to further control the GPU task concurrency in order to avoid out of memory (OOM) exceptions.
Some queries benefit significantly from setting this to a value between 2 and 4, with 2 typically providing the most benefit, and higher numbers giving diminishing returns. It is often beneficial to have a higher number of tasks in the executor, for example, four, with two concurrentGpuTasks for the benefits to offset I/O and compute. For example, one task may be communicating with a Distributed FileSystem to fetch an input buffer while another task is decoding an input buffer on the GPU. Configuring too many tasks on an executor can lead to excessive I/O and overload the host memory. We typically find that two times the number of concurrentGpuTasks is a good starting point.
E. Pin CPU memory to GPU memory.
Setting spark.rapids.memory.pinnedPool.size significantly improves the performance of data transfers between the GPU and host memory as the transfer can be performed asynchronously from the CPU. Ideally, the amount of pinned memory allocated would be sufficient to hold input partitions for the number of concurrent tasks that Spark can schedule for the executor.
F. Limit the number of shuffle partitions.
Partitions have a higher incremental cost for GPU processing than CPU processing, so it is recommended to keep the number of partitions as low as possible without running out of memory in a task.
For Alluxio, please consult the Alluxio tuning tips document for more information. For RAPIDS Spark, refer to the RAPIDS Spark tuning guide for more information.
Deployment options for NVIDIA GPU accelerated clusters with Alluxio
Users can deploy an Apache Spark cluster with NVIDIA GPUs and Alluxio on any cloud Infrastructure as a Service (IaaS) offering such as Amazon EC2, Azure VM or Google Compute Engine. Additional options include any Cloud Container as a Service (CaaS) offering such as Amazon EKS, Azure Kubernetes Service, or Google Kubernetes Engine.
Both RAPIDS Accelerator for Apache Spark and Alluxio provide integrations with all major managed cloud data services. The following guides are available for Amazon EMR, Google Dataproc with instructions for using Alluxio.
Next steps
- To learn more about accelerating I/O for Apache Spark with RAPIDS, register for the GTC 2021 talk “Enabling data orchestration with RAPIDS Accelerator”.
- To get started with Alluxio and RAPIDS accelerator for Apache Spark 3.0, visit this documentation.
- To access the RAPIDS Accelerator for Apache Spark 3.0 and the getting started guide, visit the GitHub repo.
- For more information about I/O acceleration for GPU-based deep learning using Alluxio in Kubernetes, read this developer blog.
