
The MLPerf consortium mission is to “build fair and useful benchmarks” to provide an unbiased training and inference performance reference for ML hardware, software, and services. MLPerf Training v0.7 is the third instantiation for training and continues to evolve to stay on the cutting edge.
This round consists of eight different workloads that cover a broad diversity of use cases, including vision, language, recommendation, and reinforcement learning, as detailed in the following table.
| Area | Benchmark | Dataset | Quality Target | Reference Implementation Model |
| Vision | Image Classification | ImageNet | 75.90% classification | ResNet-50 v1.5 |
| Vision | Object Detection (light weight) | COCO | 23.0% mAP | SSD |
| Vision | Object Detection (heavy weight) | COCO | 0.377 Box min AP and 0.339 Mask min AP | Mark R-CNN |
| Language | Translation (recurrent) | WMT English-German | 24.0 Sacre BLEU | NMT |
| Language | Translation (non-recurrent) | WMT English-German | 25.00 BLEU | Transformer |
| Commerce | Recommendation | 1TB Click Logs | 0.8025 AUC | DLRM |
| Research | Reinforcement learning | Go | 50%-win rate vs. checkpoint | Ming Go (based on Alpha Go paper) |
In MLPerf Training v0.7, the new NVIDIA A100 Tensor Core GPU and the DGX SuperPOD-based Selene supercomputer set all 16 performance records across per-chip and maxscale workloads for commercially available systems. These breakthroughs were a result of a tight integration of hardware, software, and system-level technologies.
A key part of the NVIDIA platform, NGC delivers the latest AI stack that encapsulates the latest technological advancement and best practices. Many NVIDIA ecosystem partners used the containers and models from NGC for their own MLPerf submissions.
In this post, we show how you can use the containers and models available in NGC to replicate the NVIDIA groundbreaking performance in MLPerf and apply it to your own AI applications.
What is NVIDIA NGC?
A GPU-optimized hub for AI, HPC, and data analytics software, NGC was built to simplify and accelerate end-to-end workflows. With over 150 enterprise-grade containers, 100+ models, and industry-specific SDKs that can be deployed on-premises, cloud, or at the edge, NGC enables data scientists and developers to build best-in-class solutions, gather insights, and deliver business value faster than ever before. It is fast becoming the place for data scientists and developers to acquire secure, scalable, and supported AI software.
Continuously updated containers
Containers allow you to package your software application, libraries, dependencies, and run time compilers in a self-contained environment. This way, the application environment is both portable and consistent, and agnostic to the underlying host system software configuration. Containers eliminate the need to install applications directly on the host and allow you to pull and run applications on the system without any assistance from the host system administrators.
NGC carries more than 150 containers across HPC, deep learning, and visualization applications. The deep learning containers in NGC are updated and fine-tuned for performance monthly. The performance improvements are made regularly to DL libraries and runtimes to extract maximum performance from NVIDIA GPUs when deploying the latest version of the containers from NGC.
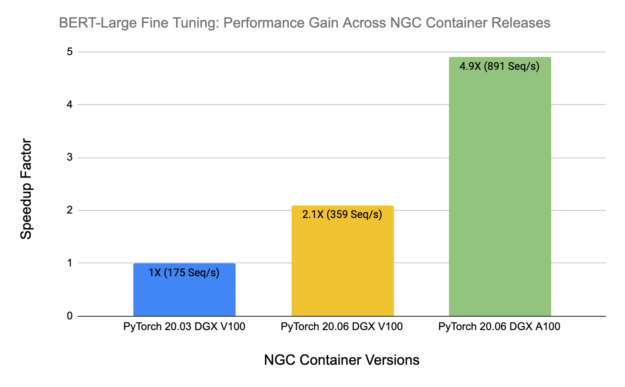
To showcase this continual improvement to the NGC containers, Figure 2 shows monthly performance benchmarking results for the BERT-Large fine-tuning task. From NGC PyTorch container version 20.03 to 20.06, on the same DGX-1V server with 8xV100 16 GB, performance improves by a factor of 2.1x.
When coupled with a new server, the DGX A100 server with 8xA100 40 GB, the performance gain improves further to 4.9X. All these improvements, including model code base, base libraries, and support for the new hardware features are taken care of by NVIDIA engineers, ensuring that you always get the best and continuously improving performance on all NVIDIA platforms.
In addition to performance, security is a vital requirement when deploying containers in production environments. The containers published in NGC undergo a comprehensive QA process for common vulnerabilities and exposures (CVEs) to ensure that they are highly secure and devoid of any flaws and vulnerabilities, giving you the confidence to deploy them in your infrastructure.
Models and resources
Pretrained models from NGC help you speed up your application building process. NGC carries more than 100 pretrained models across a wide array of applications, such as natural language processing, image analysis, speech processing, and recommendation systems.
The models are curated and tuned to perform optimally on NVIDIA GPUs for maximum performance. Applying transfer learning, you can retrain it against your own data and create your own custom model. Figure 2 shows an example of a pretrained BERT-Large model on NGC.
To build models from scratch, use the resources in NGC. You get all the steps needed to build a highly accurate and performant model based on the best practices used by NVIDIA engineers. This includes system setup, configuration steps, and code samples. Figure 3 shows the BERT TensorFlow model.

Technological breakthroughs
In this section, we highlight the breakthroughs in key technologies implemented across the NGC containers and models.
Automatic mixed precision
Deep neural networks can often be trained with a mixed precision strategy, employing mostly FP16 and FP32 precision, when necessary. This results in a significant reduction in computation, memory and memory bandwidth requirements while most often converging to the similar final accuracy. For more information, see the Mixed Precision Training paper from NVIDIA Research.
All NGC containers built for popular DL frameworks, such as TensorFlow, PyTorch, and MXNet, come with automatic mixed precision (AMP) support. With AMP, you can enable mixed precision with either no code changes or only minimal changes. Typically, it’s just a few lines of code.
AMP is a standard feature across all NGC models. AMP automatically uses the Tensor Cores on NVIDIA Volta, Turing, and Ampere GPU architectures. Researchers can get results up to 3x faster than training without Tensor Cores.
Multi-GPU training
Multi-GPU training is now the standard feature implemented on all NGC models. Under the hood, the Horovod and NCCL libraries are employed for distributed training and efficient communication. For most of the models, multi-GPU training on a set of homogeneous GPUs can be enabled simply with setting a flag, for example, --gpus 8, which uses eight GPUs.
Multi-node training
Many AI training tasks nowadays take many days to train on a single multi-GPU system. For example, BERT-Large pretraining takes ~3 days on a single DGX-2 server with 16xV100 GPUs. To shorten this time, training should be distributed beyond a single system. As shown in the results for MLPerf 0.7, you can achieve substantial speed ups by training the models on a multi-node system.
With NGC, we provide multi-node training support for BERT on TensorFlow and PyTorch. For more information about the technology stack and best multi-node practices at NVIDIA, see the Multi-Node BERT User Guide.
Custom fused CUDA kernels for faster computations
With every model being implemented, NVIDIA engineers routinely carry out profiling and performance benchmarking to identify the bottlenecks and potential opportunities for improvements. Customizing CUDA kernels, which fuses operations and calls vectorized instructions often results in significantly improved performance. All these improvements happen automatically and are continuously monitored and improved regularly with the NGC monthly releases of containers and models.
Recipes for reproducing state-of-the-art results
Every NGC model comes with a set of recipes for reproducing state-of-the-art results on a variety of GPU platforms, from a single GPU workstation, DGX-1, or DGX-2 all the way to a DGX SuperPOD cluster for BERT multi-node. These recipes encapsulate all the hyper-parameters and environmental settings, and together with NGC containers they ensure reproducible experiments and results.
You can obtain the source code and pretrained models for all these models from the NGC resources page and NGC models page, respectively. With clear instructions, you can build and deploy your AI applications across a variety of use cases.
BERT
BERT (Bidirectional Encoder Representations from Transformers) is a new method of pretraining language representations that obtains state-of-the-art results on a wide array of natural language processing (NLP) tasks. New to the MLPerf v0.7 edition, BERT forms the NLP task.
NGC provides implementations for BERT in TensorFlow and PyTorch. This model is based on the BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding paper. The NVIDIA implementation of BERT is an optimized version of Google’s official implementation and Hugging Face implementation respectively, using mixed precision arithmetic and Tensor Cores on Volta V100 and Ampere A100 GPUs for faster training times while maintaining target accuracy.
DLRM
New to MLPerf v0.7, the Deep Learning Recommendation Model (DLRM) forms the recommendation task. DLRM on the Criteo 1 TB click logs dataset replaces the previous recommendation model, the neural collaborative filtering (NCF) model in MLPerf v0.5.
The DLRM is a recommendation model designed to make use of both categorical and numerical inputs. It was first described in the Deep Learning Recommendation Model for Personalization and Recommendation Systems paper. NGC provides an implementation of DLRM in PyTorch. This code base enables you to train DLRM on the Criteo Terabyte dataset. Using DLRM, you can train a high-quality general model for providing recommendations.
ResNet-50 v1.5
Residual neural network, or ResNet, is a landmark architecture in deep learning. ResNet allows deep neural networks to be trained thanks to the residual, or skip, connections, which let the gradient to flow through many network layers without vanishing. This idea has been universally adopted in almost all modern neural network architectures. ResNet-50 is a popular, and now classical, network architecture for image classification applications. It has been a part of the MLPerf suite from the first v0.5 edition.
The ResNet50 v1.5 model is a modified version of the original ResNet50 v1 model. The difference between v1 and v1.5 is in the bottleneck blocks that require downsampling. ResNet v1 has stride = 2 in the first 1×1 convolution, whereas v1.5 has stride = 2 in the 3×3 convolution. This difference makes ResNet50 v1.5 slightly more accurate (~0.5% top1) than v1 but comes with a small performance drawback (~5% images/sec).
On NGC, we provide ResNet-50 pretrained models for TensorFlow, PyTorch, and the NVDL toolkit powered by Apache MXNet. Source code for training these models either from scratch or fine-tuning with custom data is provided accordingly. This model is trained with mixed precision using Tensor Cores on NVIDIA Volta, Turing, and Ampere GPUs.
SSD
The SSD network architecture is a well-established neural network model for object detection. SSD with ResNet-34 backbone has formed the lightweight object detection task of MLPerf from the first v0.5 edition.
NGC provides two implementations for SSD in TensorFlow and PyTorch. The SSD300 v1.1 model is based on the SSD: Single Shot MultiBox Detector paper, which describes SSD as “a method for detecting objects in images using a single deep neural network.” The input size is fixed to 300×300. Training of SSD requires computational costly augmentations, where images are cropped, stretched, and so on to improve data diversity. To fully use GPUs during training, use the NVIDIA DALI library to accelerate data preparation pipelines.
Mask R-CNN
Similar to SSD, Mask R-CNN is a convolution-based neural network for the task of object detection and instance segmentation. Mask R-CNN has formed a part of MLPerf object detection heavyweight task from the first v0.5 edition.
NGC provides Mask R-CNN implementations for TensorFlow and PyTorch. The NVIDIA Mask R-CNN is an optimized version of Google’s TPU implementation and Facebook’s implementation, respectively. The major differences between the official implementation of the paper and our version of Mask R-CNN are as follows:
- Mixed precision support
- Gradient accumulation to simulate larger batches
- Custom fused CUDA kernels for faster computations
NMT
NMT, as described in Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation, is one of the first, large-scale, commercial deployments of a DL-based translation system with great success. NMT has formed the recurrent translation task of MLPerf from the first v0.5 edition.
NGC provides implementations for NMT in TensorFlow and PyTorch. The GNMT v2 model is like the one discussed in Google’s paper. The most important difference between the two models is in the attention mechanism. In our model, the output from the first LSTM layer of the decoder goes into the attention module, then the re-weighted context is concatenated with inputs to all subsequent LSTM layers in the decoder at the current time step. The same attention mechanism is also implemented in the default GNMT-like models from TensorFlow Neural Machine Translation Tutorial, and NVIDIA OpenSeq2Seq Toolkit.
Transformer
Transformer is a neural machine translation (NMT) model that uses an attention mechanism to boost training speed and overall accuracy. The Transformer model was introduced in Attention Is All You Need and improved in Scaling Neural Machine Translation.
Transformer is a landmark network architecture for NLP. It archives high quality while at the same time making better use of high-throughput accelerators such as GPUs for training by using a non-recurrent mechanism, the attention. Transformer has formed the non-recurrent translation task of MLPerf from the first v0.5 edition.
NGC provides a Transformer implementation in PyTorch and an improved version of Transformer, called Transformer-XL, in TensorFlow.
Get started
NGC provides a standardized workflow to make use of the many models available.
- NVIDIA Docker
- Access to NVIDIA NGC
- Supported GPUs:
- NVIDIA Volta architecture
- NVIDIA Turing architecture
- NVIDIA Ampere architecture
Follow a few simple instructions on the NGC resources or models page to run any of the NGC models:
- Pull the model code. Use the NGC resources page for the selected model, or from the NVIDIA Deep Learning Examples GitHub repository.
- Build a Docker container. This automatically pulls the relevant TensorFlow, PyTorch, or MXNet container from NGC, and installs any extra dependencies on top.
- Download the data. We provide the scripts for downloading and preparing any example dataset required.
- Execute training and evaluation. We provide scripts for training models end-to-end and to validate the trained models.
- Deploy the trained models in production. For many models, we also provide guidance to deploy models into production with the NVIDIA Triton Inference Server.
Summary
The NVIDIA NGC containers and AI models provide proven vehicles for quickly developing and deploying AI applications. NGC models and containers are continually optimized for performance and security through regular releases, so that you can focus on building solutions, gathering valuable insights, and delivering business value.
