
High-performance computing (HPC) and AI have driven supercomputers into wide commercial use as the primary data processing engines enabling research, scientific discoveries, and product development. These systems can carry complex simulations and unlock the new era of AI, where software writes software.
Supercomputing leadership means scientific and innovation leadership, which explains the investments made by many governments, research institutes, and enterprises to build faster and more powerful supercomputing platforms. Extracting the highest possible performance from supercomputing systems while achieving efficient utilization has traditionally been incompatible with the secured, multitenant architecture of modern cloud computing.
A cloud-native supercomputing platform provides the best of both worlds for the first time, combining peak performance and cluster efficiency with a modern zero-trust model for security isolation and multitenancy. The key element enabling this architecture transition is the NVIDIA BlueField data processing unit (DPU). The DPU is a fully integrated data-center-on-a-chip platform that imbues each supercomputing node with two new capabilities:
- Infrastructure control plane processor—Secures user access, storage access, networking, and lifecycle orchestration for the computing node, offloading the main compute processor and enabling bare-metal multitenancy.
- Isolated line-rate datapath with hardware acceleration—Enables bare-metal performance.
HPC and AI communication frameworks and libraries are latency– and bandwidth-sensitive, and they play a critical role in determining application performance. Offloading the libraries from the host CPU or GPU to the BlueField DPU creates the highest degree of overlap for parallel progression of communication and computation. It also reduces the negative effects of OS jitter and dramatically increases application performance.
The development of the cloud-native supercomputer architecture is based on open community development, including commercial companies, academic organizations, and government agencies. This growing community is essential to developing the next generation of supercomputing.
One example that we share in this post is the MVAPICH2-DPU library, designed and developed by X-ScaleSolutions. The MVAPICH2-DPU library has incorporated offloading for nonblocking collectives of the Message Passing Interface (MPI) standard.
This post outlines the basic concepts behind such offloading and how an end user can use the MVAPICH2-DPU MPI library to accelerate the execution of scientific applications, especially with dense nonblocking all-to-all operations. For more information, watch the live demo on NVIDIA on demand now: NVIDIA DPU Acceleration for Scientific Applications.
BlueField DPU
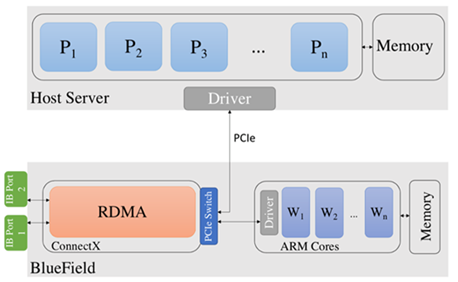
Figure 1 shows an overview of the BlueField DPU architecture and its connectivity with a host computing platform. The DPU has InfiniBand network connectivity through the ConnectX-6 adapter. In addition, it has a set of Arm cores. The Bluefield-2 DPU has a set of eight Arm cores operating at 2.0 GHz each. The Arm cores also have 16 GBytes of shared memory.
MVAPICH2-DPU MPI library
The MVAPICH2-DPU MPI library is a derivative of the MVAPICH2 MPI library. This library is optimized to harness the full potential of BlueField DPUs with InfiniBand networking.
The latest MVAPICH2-DPU 2021.06 release has the following features:
- Based on MVAPICH2 2.3.6, conforming to the MPI 3.1 standard
- Support for all features available with the MVAPICH2 2.3.6 release
- Novel framework to offload nonblocking collectives to DPU
- Offload of nonblocking Alltoall (MPI_Ialltoall) to DPU
- 100% overlap of computation with MPI_Ialltoall nonblocking collective
- Acceleration of scientific applications using MPI_Ialltoall nonblocking collective
Getting started with the MVAPICH2-DPU MPI library
The MVAPICH2-DPU library is available from X-ScaleSolutions:
- Send email to contactus@x-scalesolutions.com
- Fill out the contact form
For more information, see the MVAPICH2-DPU product page.
Sample execution with the OSU Micro-Benchmarks
A copy of the OSU MPI Micro-Benchmarks comes integrated with the MVAPICH2-DPU MPI package. The OMB benchmark suite consists of benchmarks for nonblocking collective operations. These benchmarks are designed to evaluate overlap capabilities between computation and communication used with nonblocking MPI collectives.
The nonblocking collective benchmarks in the OMB package can be executed to evaluate the following metrics:
- Overlap capabilities
- Overall execution time when computation steps are incorporated immediately after initiating nonblocking collectives
A set of OMB experiments were run on the HPC-AI Advisory Council cluster with 32 nodes connected with 32 BlueField DPUs supporting HDR 200-Gb/s InfiniBand connectivity. Each host node has dual-socket Intel Xeon 16-core CPUs E5-2697A V4 @2.60 GHz. Each Bluefield-2 DPU has eight Arm cores @2.0 Ghz and 16 GB of memory.
Figure 2 shows the performance results of the MPI_Ialltoall nonblocking collective benchmark running with 512 (32 nodes with 16 processes per node (PPN) each) and 1,024 (32 nodes with 32 PPN each) MPI processes, respectively. As message size increases, the MVAPICH2-DPU library can demonstrate the peak (100%) overlap between computation and the MPI_Ialltoall nonblocking collective. In contrast, the MVAPICH2 default library without such DPU offloading capability can provide little overlap between computation and MPI_Ialltoall non_blocking collective.
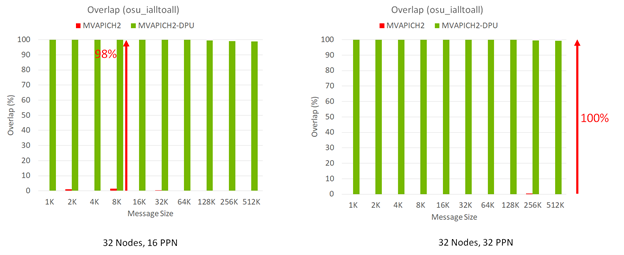
When computation steps in an MPI application are used with the MPI_Ialltoall nonblocking collective operation in an overlapped manner, the MVAPICH2-DPU MPI library provides significant performance benefits in the overall program execution time. This is possible because the Arm cores in the DPUs can implement the nonblocking all-to-all operations while the Xeon cores on the host are performing computation with peak overlap (Figure 2).
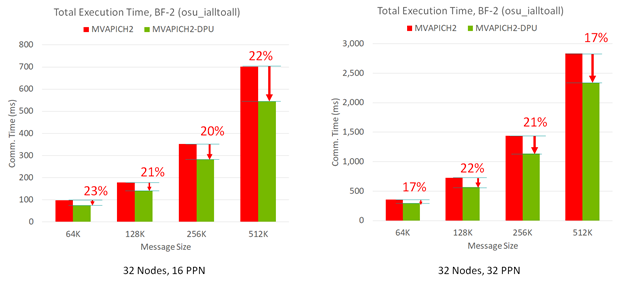
Figure 3 shows that the MVAPICH2-DPU MPI library can deliver up to 23% performance benefits compared to the basic MVAPICH2 MPI library. This was across message sizes and PPNs on a 32-node experiment with the OMB MPI_Iall benchmark.
Accelerating the P3DFFT application kernel
The P3DFFT is a common MPI kernel used in many end-applications using a fast Fourier transform (FFT). A version of this MPI kernel has been designed by the P3DFFT developer to use nonblocking all-to-all collective operations with computational steps to harness maximum overlap.
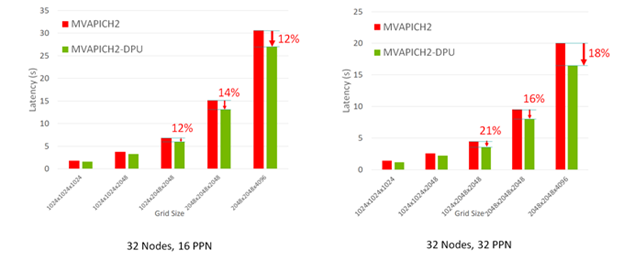
The enhanced version of the P3DFFT MPI kernel was evaluated on the 32-node HPC-AI cluster with the MVAPICH2-DPU MPI library. Figure 4 shows that the MVAPICH2-DPU MPI library reduces the overall execution time of the P3DFFT application kernel up to 21% for various grid sizes and PPNs.
Summary
The NVIDIA DPU architecture provides novel capabilities to offload functionalities of any middleware to the programmable Arm cores on the DPU. MPI libraries must be redesigned to take advantage of such capabilities to accelerate scientific applications.
The MVAPICH2-DPU MPI library is a leading library to harness such DPU capability. The initial release of the MVAPICH2-DPU library with offloading support for MPI_Ialltoall nonblocking collectives demonstrates 100% overlap between computation and nonblocking alltoall collective. It can accelerate the P3DFFT application kernel execution time by 21% on a 1,024 MPI process run.
This study demonstrates a strong ROI for the DPU architecture with the MVAPICH2-DPU MPI library. Additional offloading capabilities in the upcoming releases for other MPI functions, with advances in the DPU architectures, will accelerate scientific applications on cloud-native supercomputing systems in a significant manner.
For more information about the MVAPICH2-DPU MPI library and its roadmap, send email to contactus@x-scalesolutions.com or fill out the contact form.
