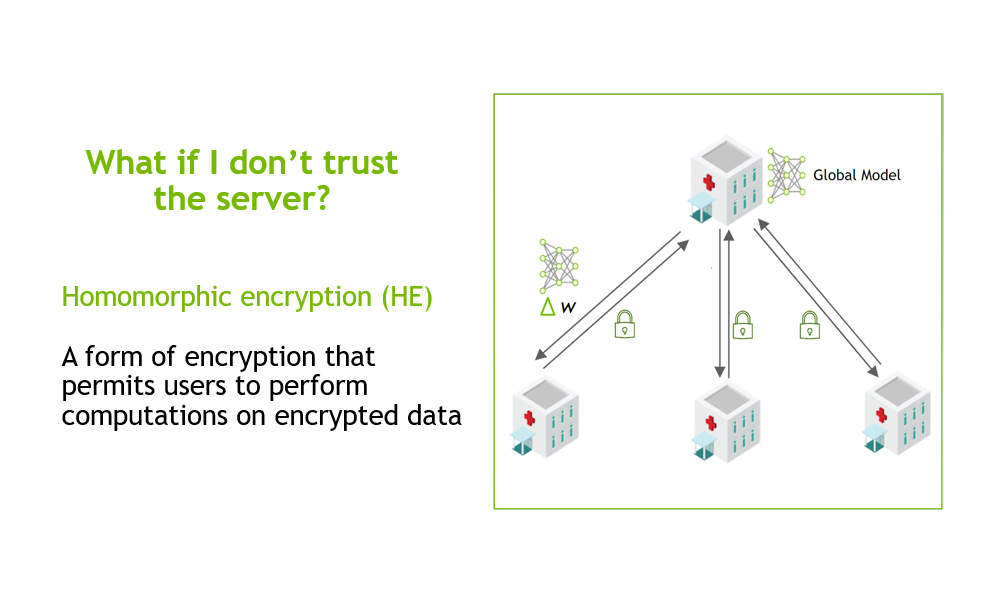
In NVIDIA Clara Train 4.0, we added homomorphic encryption (HE) tools for federated learning (FL). HE enables you to compute data while the data is still encrypted.
In Clara Train 3.1, all clients used certified SSL channels to communicate their local model updates with the server. The SSL certificates are needed to establish trusted communication channels and are provided through a third party that runs the provisioning tool and securely distributes them to the hospitals. This secures the communication to the server, but the server can still see the raw model (unencrypted) updates to do aggregation.
With Clara Train 4.0, the communication channels are still established using SSL certificates and the provisioning tool. However, each client optionally also receives additional keys to homomorphically encrypt their model updates before sending them to the server. The server doesn’t own a key and only sees the encrypted model updates.
With HE, the server can aggregate these encrypted weights and then send the updated model back to the client. The clients can decrypt the model weights because they have the keys and can then continue with the next round of training (Figure 1).
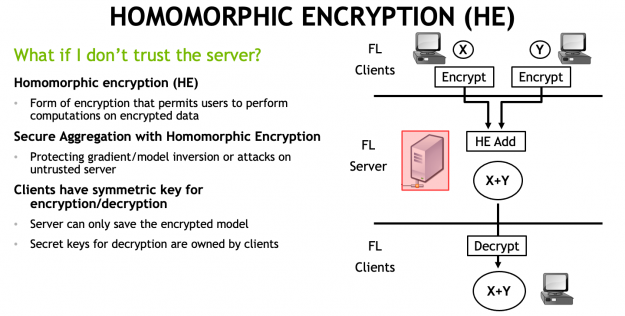
HE ensures that each client’s changes to the global model stays hidden by preventing the server from reverse-engineering the submitted weights and discovering any training data. This added security comes at a computational cost on the server. However, it can play an important role in healthcare in making sure that patient data stays secure at each hospital while still benefiting from using federated learning with other institutions.
HE implementation in Clara Train 4.0
We implemented secure aggregation during FL with HE using the TenSEAL library by OpenMined, a convenient Python wrapper around Microsoft SEAL. Both libraries are available as open-source and provide an implementation of Homomorphic encryption for arithmetic of approximate numbers, also known as the CKKS scheme, which was proposed as a solution for encrypted machine learning.
Our default uses the following HE setting, specified in Clara Train’s provisioning tool for FL:
# homomorphic encryption he: lib: tenseal config: poly_modulus_degree: 8192 coeff_mod_bit_sizes: [60, 40, 40] scale_bits: 40 scheme: CKKS
These settings are recommended and should work for most tasks but could be further optimized depending on your specific model architecture and machine learning problem. For more information about different settings, see this tutorial on the CKKS scheme and benchmarking.
HE benchmarking in FL
To compare the impact of HE to the overall training time and performance, we ran the following experiments. We chose SegResNet (a U-Net like architecture used to win the BraTS 2018 challenge) trained on the CT spleen segmentation task from the Medical Segmentation Decathlon.
Each federated learning run was trained for 100 rounds with each client training for 10 local epochs on their local data on an NVIDIA V100 (server and clients are running on localhost). In each run, half of the clients each used half of the training data (16/16) and half of the validation data (5/4), respectively. We recorded the total training time and best average validation dice score of the global model. We show the relative increase added by HE in Table 1.
There is a moderate increase in total training time of about 20% when encrypting the full model. This increase in training time is due to the added encryption and decryption steps and aggregation in homomorphically encrypted space. Our implementation enables you to reduce that extra time by only encrypting a subset of the model parameters, for example, all convolutional layers (“conv”). You could also encrypt just three of the key layers, such as the input, middle, and output layers.
The added training time is also due to increased message sizes needed to send the encrypted model gradient updates, requiring longer upload times. For SegResNet, we observe an increase from 19 MB to 283 MB using the HE setting mentioned earlier (~15x increase).
| Setting | Message size (MB) | Nr. clients | Training time | Best global Dice | Best epoch | Re. Increase in training time |
| Raw | 19 | 2 | 4:57:26 | 0.951 | 931 | – |
| Raw | 19 | 4 | 5:11:20 | 0.956 | 931 | – |
| Raw | 19 | 8 | 5:18:00 | 0.943 | 901 | – |
| HE full | 283 | 2 | 5:57:05 | 0.949 | 931 | 20.1% |
| HE full | 283 | 4 | 6:00:05 | 0.946 | 811 | 15.7% |
| HE full | 283 | 8 | 6:21:56 | 0.963 | 971 | 20.1% |
| HE conv layers | 272 | 2 | 5:54:39 | 0.952 | 891 | 19.2% |
| HE conv layers | 272 | 4 | 6:06:13 | 0.954 | 951 | 17.6% |
| HE conv layers | 272 | 8 | 6:28:16 | 0.948 | 891 | 22.1% |
| HE three layers | 43 | 2 | 5:12:10 | 0.957 | 811 | 5.0% |
| HE three layers | 43 | 4 | 5:15:01 | 0.939 | 841 | 1.2% |
| HE three layers | 43 | 8 | 5:19:02 | 0.949 | 971 | 0.3% |
Next, we compare the performance of FL using up to 30 clients with the server running on AWS. For reference, we used an m5a.2xlarge with eight vCPUs, 32-GB memory, and up to 2,880 Gbps network bandwidth. We show the average encryption, decryption, and upload time, comparing raw compared to encrypted model gradients being uploaded in Figure 2 and Table 2. You can see the longer upload times due to the larger message sizes needed by HE.
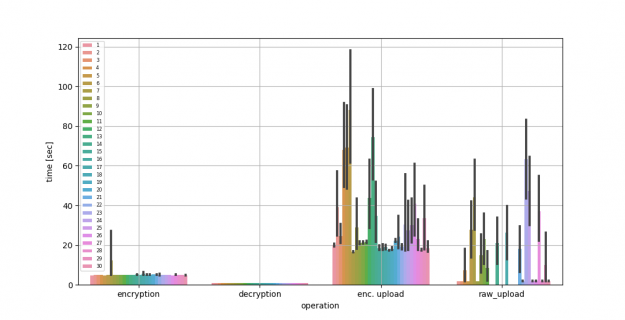
| Time in seconds | Mean | Std. Dev. | |||||
| Encryption time | 5.01 | 1.18 | |||||
| Decryption time | 0.95 | 0.04 | |||||
| Enc. upload time | 38 | 71.170 | |||||
| Raw upload time | 21.57 | 74.23 |
Try it out
If you’re interested in learning more about how to set up FL with homomorphic encryption using Clara Train, we have a great Jupyter notebook on GitHub that walks you through the setup.
HE can reduce model inversion or data leakage risks if there is a malicious or compromised server. However, your final models might still contain or memorize privacy-relevant information. That’s where differential privacy methods can be a useful addition to HE. Clara Train SDK implements the sparse vector technique (SVT) and partial model sharing that can help preserve privacy. For more information, see Privacy-preserving Federated Brain Tumour Segmentation. Keep in mind that there is a tradeoff between model performance and privacy protection.
