视觉语言模型最近有了显著的发展。然而,现有技术通常仅支持一个图像。他们无法在多个图像之间进行推理、支持上下文学习或理解视频。此外,它们不会优化推理速度。
我们开发了 VILA,一个具有整体预训练、指令调整和部署管道的可视化语言模型,以帮助我们的 NVIDIA 客户在其多模式产品中取得成功。VILA 在图像 QA 基准和视频 QA 基准上都实现了 state-of-the-art(SOTA)性能,具有强大的多图像推理能力和上下文学习能力。此外,它还针对速度进行了优化。
与其他 VLM 相比,它使用了 1/4 的令牌,并在不损失精度的情况下使用 4 位 AWQ 进行量化。VILA 有多种尺寸,从支持最高性能的 40B 到可部署在 NVIDIA Jetson Orin 等边缘设备上的 3.5B 不等。
我们设计了一个高效的训练管道,仅用两天时间就在 128 NVIDIA A100 GPU 上训练了 VILA-13B。除了这个研究原型,我们还证明了 VILA 可以通过更多的数据和 GPU 小时进行扩展。
为了提高推理效率,VILA 与 TRT-LLM 兼容。我们使用 4 位 AWQ 量化了 VILA,该 AWQ 在单个 NVIDIA RTX 4090 GPU 上以 10ms/令牌的速度运行 VILA-14B。
VILA 训练配方
像 Llava 这样的现有方法使用视觉指令调整来扩展具有视觉输入的 LLM,但缺乏对视觉语言预训练过程的深入研究,在该过程中,模型学习在两种模态上进行联合建模。

模型架构
多模式 LLM 可以分为基于交叉注意力和基于自回归的设置。
后一个标记器将图像转换为视觉标记,与文本标记连接,并作为 LLM 的输入(即,将视觉输入视为外语)。它是纯文本 LLM 的自然扩展,通过与 RAG 类似的视觉嵌入来增强输入,并且可以处理任意数量的交错图像文本输入。
因此,由于其灵活性和易于量化/部署,我们将重点放在了自回归架构上。
图 1 显示自回归 VLM 模型由三个主要组件组成:a视觉编码器、LLM 和 投影仪,它们桥接来自两种模态的嵌入。该模型可以接受视觉和文本输入,并生成文本输出。
解冻 LLM 至关重要
有两种流行的方法可以用视觉输入来增强预训练的纯文本 LLM:在视觉输入标记上微调 LLM,或者冻结 LLM 并仅训练视觉输入投影仪作为提示调整。
后者很有吸引力,因为冻结 LLM 可以防止预训练的纯文本 LLM 的退化。尽管如此,更新基本 LLM 对于继承一些有吸引力的 LLM 属性(如上下文学习)至关重要。
我们观察到以下情况:
- 尽管使用了高容量设计,但在 SFT 期间仅训练投影仪会导致性能不佳。在 SFT 期间对 LLM 进行微调会更有收获。
- 有趣的是,在预训练过程中冻结 LLM 不会影响零样本性能,但会降低上下文学习能力。
- 当使用小容量投影仪(线性层而不是变压器块)时,精度略高(比较 c 和 d)。我们假设,一个更简单的投影仪迫使 LLM 在处理视觉输入时学习更多,从而获得更好的泛化能力。
鉴于这些观察结果,我们在后续研究的预训练和教学调整过程中使用了一个简单的线性投影层来微调 LLM。
交错的图像文本数据至关重要
我们的目标是增强 LLM 以支持视觉输入,而不是训练一个只对视觉语言输入有效的模型。保留 LLM 的纯文本功能是至关重要的。
数据管理和混合是预训练和教学调整的关键因素。有两种数据格式:
- 图像文本对(即图像及其标题):<im1><txt1>、<im2><txt2>
- 交错的图像文本数据:<txt1><im1><txt2><txt3><im2><txt4>
图像文本对
像在 COYO 数据集中那样使用图像-文本对进行预训练可能会导致灾难性的遗忘。纯文本准确性(MMLU)降低了 17.2%。
值得注意的是,4 次拍摄的准确度甚至比零样本更差,这表明该模型无法正确地对视觉语言输入进行上下文学习(可能是因为它在预训练过程中从未看到过一张以上的图像)。
我们认为,灾难性的遗忘是由于基于文本的字幕的分布,这些字幕通常简短明了。
交错的图像文本
另一方面,与纯文本语料库相比,使用像 MMC4 这样的交错图像-文本数据集具有更接近的分布。当使用交织数据进行预训练时,MMLU 的退化仅为~5%。
通过适当的指令调整,可以完全恢复这种降级。它还实现了视觉上下文学习,与零样本相比,具有更高的 4 拍摄精度,这是 VILA 的一大亮点。
数据混合
数据混合改进了预训练,将两者的优点结合起来。混合交错语料库和图像文本对可以在语料库中引入更多的多样性,同时防止严重退化。
MMC4+COYO 的训练进一步提高了视觉语言基准测试的准确性。
通过联合 SFT 恢复 LLM 退化
尽管交错数据有助于保持纯文本功能,但仍有 5%的准确性下降。
保持纯文本能力的一种潜在方法是添加纯文本语料库(LLM 预训练中使用的语料库)。然而,这样的文本语料库通常是专有的,即使对于开源模型也是如此。目前还不清楚如何对数据进行子采样,以匹配视觉语言语料库的规模。
幸运的是,我们发现纯文本功能只是暂时隐藏的,不会被遗忘。尽管使用的规模比文本预训练语料库(通常为万亿规模)小得多,但在 SFT 期间添加纯文本数据可以帮助弥补退化。
我们观察到,在纯文本的 SFT 数据中混合可以弥补纯文本能力的退化,并提高视觉语言能力。我们推测,纯文本指令数据提高了模型的指令跟随能力,这对视觉语言任务也很重要。
有趣的是,在联合 SFT 中,混合 COYO 数据的好处更为显著。我们相信,通过联合 SFT,当使用短字幕进行预训练时,模型不再遭受纯文本的退化,从而释放出更好的视觉多样性的全部好处。
图像分辨率很重要,而不是代币的数量
将分辨率从 224 提高到 336 可以将 TextVQA 的准确率从 41.6%提高到 49.8%。
然而,更高的分辨率导致每幅图像有更多的令牌(336×336 对应于 576 个令牌/幅图像)和更高的计算成本,在有限的上下文长度下,这对视频理解来说甚至更糟。我们有一种 LongLoRA 技术来扩展上下文长度,我们计划将其结合起来。它还限制了上下文学习的演示次数。
幸运的是,原始分辨率比视觉标记/图像的数量更重要。我们可以使用不同的投影仪设计来压缩视觉标记。我们尝试了一种下采样投影仪,它只需将每 2×2 个标记连接成一个标记,并使用线性层来融合信息。在 336 分辨率下,它将#令牌减少到 144 个,甚至小于 224+线性设置。
尽管如此,TextVQA 的准确性更高(46%对 41.6%),尽管与 336+线性设置相比仍差 3%,显示出图像标记中的巨大冗余。其他数据集(如 OKVQA 和 COCO)上的差距较小,因为它们通常需要更高级别的语义。
在我们最初的出版物中,我们没有在主要结果中应用任何令牌压缩。然而,在本版本中,我们为各种尺寸的模型提供了这种令牌压缩技术。
数据质量比数据量更重要
我们的实验表明,将预训练数据从 25M 扩展到 50M 并没有带来多大好处。然而,添加约 1M 的高质量数据可以提高基准测试结果。因此,数据质量比数据量重要得多。
为了用高性能但有限的计算资源训练 VILA,我们更多地关注数据质量而不是数据量。例如,根据 CLIP 评分,我们只选择了 COYO-700M 数据集的前 5%作为文本图像对。我们还为视频字幕数据集过滤了高质量的数据,并将其添加到我们的数据集混合物中。
VILA 部署
VILA 易于量化并部署在 GPU 上。它用可视化标记增强了 LLM,但没有改变 LLM 体系结构,后者保持了代码库的模块化。
我们使用 4 位 AWQ 量化了 VILA,并将其部署在 NVIDIA RTX 4090 和 Jetson Orin 上。欲了解更多信息,请参阅 视觉语言智能与 Edge AI 2.0 博客。
AWQ 量化算法适用于多模式应用,因为 AWQ 不需要反向传播或重建,而 GPTQ 需要。因此,它对新的模态具有更好的泛化能力,并且不会过度拟合到特定的校准集。我们只量化了模型的语言部分,因为它决定了模型的大小和推理延迟。视觉部分占用的延迟不到 4%。
AWQ 在零样本和各种少热点设置下优于现有方法(RTN、GPTQ),证明了不同模式和上下文学习工作负载的通用性。
性能
| 模型 | VQA-V2 | GQA | VQA–T | 科学 QA–I | MME | 种子-I | MMMU 值 | MMMU 测试 |
| LLaVA-NeXT-34B | 83.7 | 67.1 | 69.5 | 81.8 | 1631 | 75.9 | 51.1 | 44.7 |
| 维拉 1.5-40B | 84.3 | 64.6 | 73.5 | 87.4 | 1727 | 75.7 | 51.9 | 46.9 |
| 模型 | 精确 | VQA-V2 | GQA | VQA–T | 科学 QA–I | MME | 种子-I | MMMU 值 | MMMU 测试 |
| 维拉 1.5-13B | fp16 | 82.8 | 64.3 | 65 | 80.1 | 1570 | 72.6 | 37.9 | 33.6 |
| 维拉 1.5-13B | int4 | 82.7 | 64.5 | 64.7 | 79.7 | 1531 | 72.6 | 37.8 | 34 |
| Llama-3-别墅 15-8B | fp16 | 80.9 | 61.9 | 66.3 | 79.9 | 1577 | 71.4 | 36.9 | 36 |
| Llama-3-别墅 15-8B | int4 | 80.3 | 61.7 | 65.4 | 79 | 1594 | 71.1 | 36 | 36.1 |
| 模型 | 精确 | NVIDIA A100 GPU | NVIDIA RTX 4090 | NVIDIA Jetson Orin |
| 维拉 1.5-13B | fp16 | 51 | OOM | 6 |
| 维拉 1.5-13B | int4 | 116 | 106 | 21 |
| Llama-3-别墅 15-8B | fp16 | 75 | 57 | 10 |
| Llama-3-别墅 15-8B | int4 | 169 | 150 | 29 |
视频字幕性能
VILA 具有上下文学习能力:在没有明确描述任务(描述公司、分类和计数以及世界知识)的情况下,使用少量镜头示例进行提示,VILA 可以自动识别任务并做出正确的预测。

VILA 具有良好的泛化和推理能力。它可以理解模因,通过多个图像或视频帧推理,并处理驾驶场景中的角落案例。

VILA 在 NVIDIA GTC 2024
在 NVIDIA GTC 2024 上,我们宣布了 VILA,以实现从边缘到云的高效多模式 NVIDIA AI 解决方案。
在边缘,使用 AWQ 将 VILA 有效地量化为四个比特,这对于 下载,能够在 NVIDIA Jetson Orin Nano 和 Jetson AGX Orin 平台上进行实时推理。这大大解决了边缘机器人和自动驾驶汽车应用所面临的能源和延迟预算有限的挑战。有关全面的教程,请参见 视觉语言智能与 Edge AI 2.0 博客。
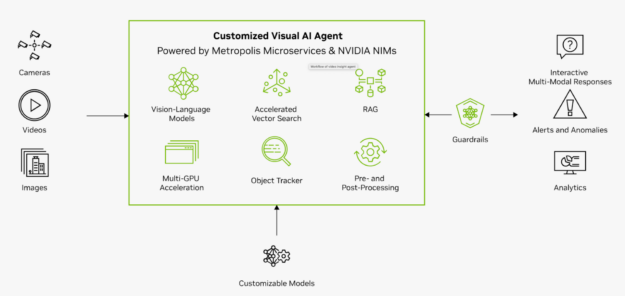
VILA 和 NVIDIA Visual Insight Agent
VILA 在云中增强了 NVIDIA Visual Insight Agent(VIA)框架,使您能够创建 AI 代理。这些代理人通过回答诸如“工厂第三通道发生了什么?”之类的询问来协助运营团队例如,生成型人工智能代理可以立即提供见解,解释道:“下午 3:30,盒子从货架上掉下来,挡住了过道。”
使用 VIA 框架,您可以制作人工智能代理,通过视觉语言模型处理大量实时或存档的视频和图像数据。无论是在边缘还是在云中实现,这一先进一代的视觉人工智能代理都将改变几乎每个行业。它们使您能够使用自然语言从视频内容中总结、搜索和获得可操作的见解。
欲了解更多信息,请参阅 保持同步:NVIDIA 将数字孪生与实时人工智能相结合,实现工业自动化。
结论
VILA 提供了一种有效的设计方法,可以将 LLM 扩展到视觉任务,从训练到推理。充分利用 LLM 的解冻、交错的图像-文本数据管理和仔细的文本数据重新混合,VILA 在保持纯文本功能的同时,已经超越了最先进的视觉任务方法。
VILA 在多图像分析、上下文学习和零/少镜头任务方面表现出强大的推理能力。我们希望 VILA 能够帮助 NVIDIA 在 NVIDIA Metropolis、视听、机器人、生成人工智能等领域建立更好的多模态基础模型。
有关更多信息,请参阅 VILA:关于视觉语言模型的预训练 论文和在 GitHub 上的 /Efficient-Large-Model/VILA 库。