
生成式人工智能开启了一个新的计算时代,这个时代有望彻底改变人机交互。这一技术的前沿是大语言模型 (LLMs),它使企业能够使用大型数据集进行识别、汇总、翻译、预测和生成内容。然而,生成式人工智能对企业的潜力也伴随着相当多的挑战。
由通用 LLM 提供的云服务提供了一种快速入门生成人工智能技术的方法。然而,这些服务通常专注于一系列广泛的任务,而不是针对特定领域的数据进行培训,这限制了它们对某些企业应用程序的价值。这导致许多组织构建自己的解决方案——这是一项艰巨的任务——因为他们必须将各种开源工具拼凑在一起,确保兼容性,并提供自己的支持。
NVIDIA NeMo 提供了一个端到端平台,旨在简化企业 LLM 的开发和部署,开创人工智能能力的变革时代。NeMo 为您提供创建企业级、可生产的定制 LLM 的基本工具。NeMo 工具套件简化了数据管理、培训和部署过程,有助于根据每个组织的具体需求快速开发定制的人工智能应用程序。
对于依赖人工智能进行业务运营的企业, NVIDIA AI Enterprise 提供了一个安全的端到端软件平台。 NVIDIA AI enterprise 将 NeMo 与生成的人工智能参考应用程序和企业支持相结合,简化了采用过程,为人工智能功能的无缝集成铺平了道路。
面向生产的生成人工智能的端到端平台
NeMo 框架通过为各种模型架构提供端到端功能和容器化配方,简化了构建定制的企业级生成人工智能模型的途径。
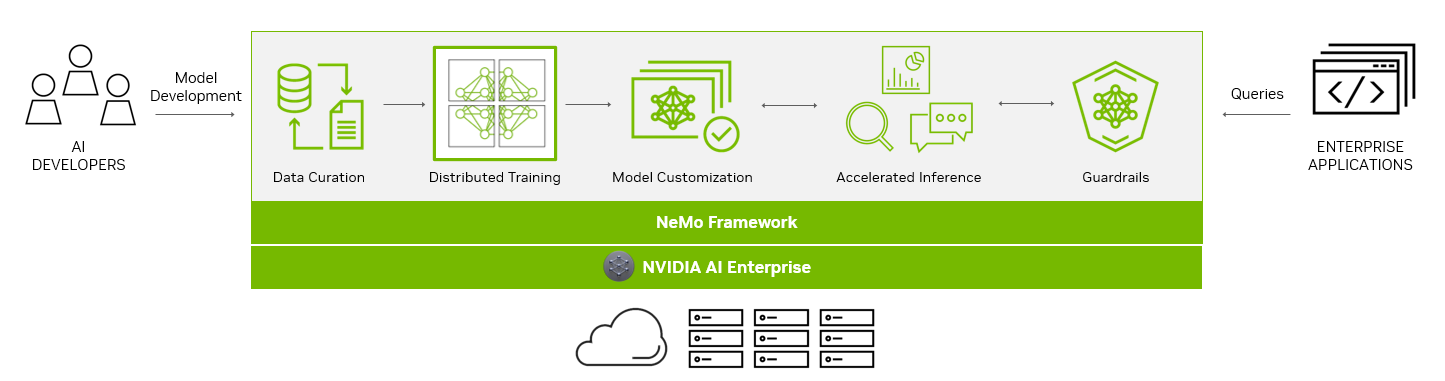
为了帮助您创建 LLM , NeMo 框架提供了强大的工具:
- 数据管理
- 大规模分布式培训
- 用于定制的预训练模
- 加速推理
- Guardrails
数据管理
在人工智能快速发展的环境中,对广泛数据集的需求已成为构建强大 LLM 的关键因素。
NeMo 框架通过 NeMo Data Curator 解决了在多语言数据集中管理数万亿代币的挑战。该工具的可扩展性使您能够轻松处理数据下载、文本提取、清洁、过滤以及精确或模糊重复数据消除等任务。
通过利用包括消息传递接口( MPI )、 Dask 和 Redis Cluster 在内的尖端技术的力量, Data Curator 可以在数千个计算核心中扩展数据管理过程,大大减少手动工作量并加快开发工作流程。
Data Curator 的主要优势之一在于其重复数据消除功能。通过确保 LLM 是在唯一的文档上进行培训的,您可以避免冗余数据,并在预培训阶段实现可观的成本节约。这不仅简化了模型开发过程,还优化了组织的人工智能投资,使人工智能开发更容易实现,更具成本效益。
Data Curator 被包装在 NeMo 培训容器中,可以通过 NGC 获取。
大规模分布式培训
从头开始训练十亿参数 LLM 模型在加速和规模方面提出了独特的挑战。这一过程需要巨大的分布式计算能力、基于加速的硬件和内存集群、可靠且可扩展的机器学习( ML )框架以及容错系统。
NeMo 框架的核心是分布式训练和高级并行性的统一。 NeMo 熟练地跨节点使用 GPU 资源和内存,带来了突破性的效率提升。通过划分模型和训练数据, NeMo 实现了无缝的多节点和多 GPU 训练,显著减少了训练时间,提高了整体生产力。
NeMo 的一个突出特点是它结合了各种并行技术:
- 数据并行性
- 张量平行度
- 管道平行度
- 序列并行性
- 稀疏注意力减少( SAR )。
这些技术协同工作以优化训练过程,从而最大限度地利用资源并提高表现。
NeMo 还提供了一系列精度选项:
- FP32 / TF32
- BF16
- FP8
FlashAttention 和 Rotary Positional Embedding ( RoPE )等突破性创新可满足长序列任务的需求。注意线性偏差( ALiBi )、梯度和部分检查点以及分布式 Adam Optimizer 进一步提高了模型性能和速度。
用于定制的预训练模
虽然一些生成性人工智能用例需要从头开始进行培训,但越来越多的组织正在使用预训练模型来启动他们构建定制 LLM 的工作。
预训练模型最显著的好处之一是节省了时间和资源。通过跳过预训练通用 LLM 所需的数据收集和清理阶段,您可以专注于根据其特定需求对模型进行微调,从而加快最终解决方案的时间。此外,基础设施设置和模型训练的负担大大减轻,因为预训练的模型具有预先存在的知识,可以进行定制。
您可以在如 GitHub,Hugging Face 等平台上找到成千上万的开源模型,因此在选择开始的模型时,您有很多选择。虽然准确性是评估预训练模型的一种常见方法,但还有其他需要考虑的因素:
- 大小
- 微调成本
- 延迟
- 内存限制
- 商业许可选项
使用 NeMo,您现在可以访问广泛的预训练模型,包括 NVIDIA 和流行的开源存储库,如 Falcon AI,Llama-2 和 MPT 7B。
NeMo 模型经过了推理优化,非常适合生产用例。有了在现实世界应用程序中部署这些模型的能力,您可以推动变革性成果,并为您的组织释放人工智能的全部潜力。
模型自定义
ML 模型的定制正在迅速发展,以适应企业和行业的独特需求。 NeMo 框架提供了一系列技术来为专门的用例细化通用的、预训练的 LLM 。通过这些多样化的定制选项, NeMo 提供了广泛的灵活性,这对于满足不同的业务需求至关重要。
Prompt engineering 是一种有效的定制方法,可以在许多下游任务中使用预训练的 LLM,而无需调整预训练模型的参数。提示工程的目标是设计和优化足够具体和清晰的提示,以从模型中获得所需的输出。
P-tuning 和即时调整是参数有效微调(PETF)技术的一部分,它使用巧妙的优化策略来选择性地只更新 LLM 的少数参数。如在 NeMo 中实现的那样,可以将新任务添加到模型中,而不会覆盖或中断模型已经调整的先前任务。
NeMo 优化了其 p 调谐方法,用于多 GPU 和多节点环境,从而实现加速训练。 NeMo p 调谐还支持一种“早期停止”机制,该机制可以识别模型何时收敛到进一步训练不会大大提高精度的点。然后它停止了培训工作。此技术减少了自定义模型所需的时间和资源。
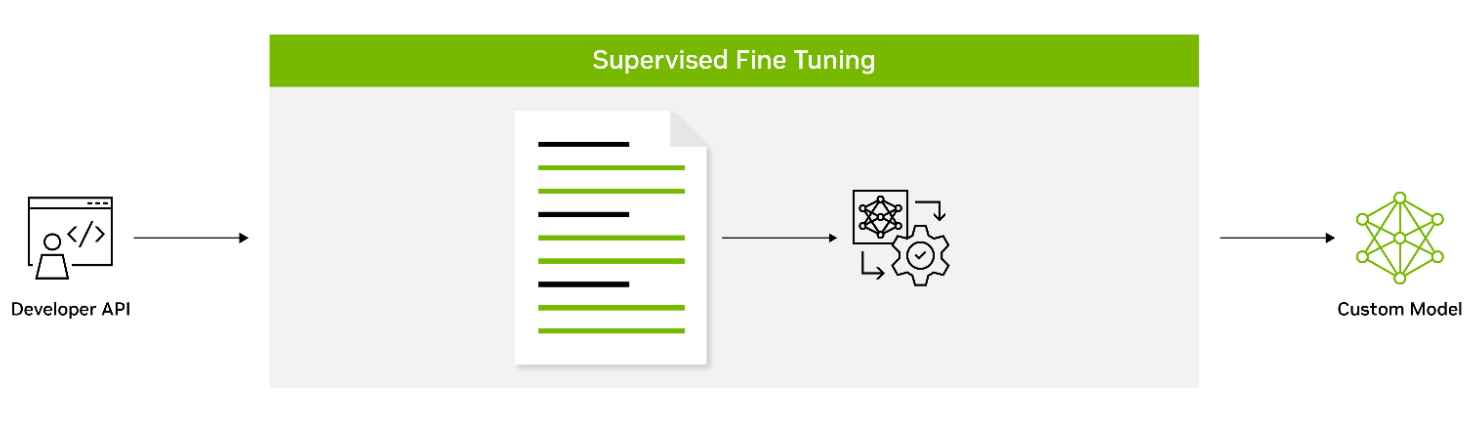
有监督的微调(SFT)涉及使用标记数据来微调模型的参数。这种方法也被称为指令调整,通常在预训练后进行。它提供了使用最先进的模型而不需要初始训练的优势,从而降低了计算成本并减少了数据收集要求。
Adapters 在模型的核心层之间引入了小的前馈层。然后,这些适配器层会针对特定的下游任务进行微调,从而提供针对当前任务需求的独特定制级别。
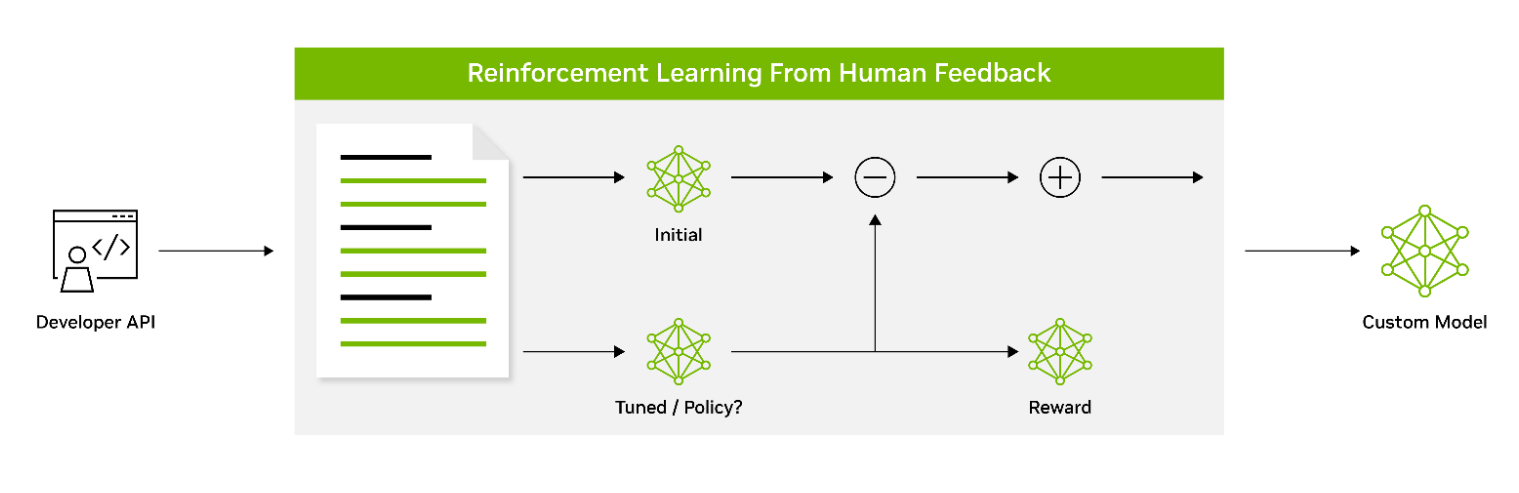
通过人类反馈进行强化学习( RLHF )采用了三阶段的微调过程。该模型根据反馈调整其行为,以更好地与人类的价值观和偏好保持一致。这使得 RLHF 成为创建能与人类用户产生共鸣的模型的强大工具。
AliBi 使 transformer 模型能够在推理时处理比训练时更长的序列。这在处理信息较长或复杂的情况下特别有用。
NeMo Guardrails 有助于确保 LLM 支持的智能应用程序准确、适当、主题明确且安全。NeMo Guardrails 是开源的,包括企业为生成文本的人工智能应用程序添加安全性所需的所有代码、示例和文档。NeMo Guardrails 与 NeMo 以及所有 LLM 一起工作,包括 OpenAI 的 ChatGPT。
加速推理
NeMo 与 NVIDIA Triton Inference Server 的无缝集成显著加快了推理过程,提供了卓越的准确性、低延迟和高吞吐量。这种集成有助于安全高效的部署,从单个 GPU 到大规模多节点 GPU ,同时遵守严格的安全和安保要求。
NVIDIA Triton 使 NeMo 能够简化和标准化生成人工智能推理。这使团队能够在任何基于 GPU 或 CPU 的基础设施上从任何框架部署、运行和扩展经过训练的 ML 或深度学习( DL )模型。这种高度的灵活性使您可以自由选择最适合您的人工智能研究和数据科学项目的框架,而不会影响生产部署的灵活性。
Guardrails
作为 NVIDIA AI Enterprise software suite 的一部分,NeMo 使组织能够放心地部署生产就绪的人工智能。组织可以利用长达 3 年的长期分支机构支持,确保无缝运营和稳定。定期的常见漏洞和暴露( CVE )扫描、安全通知和及时的补丁增强了安全性,而 API 的稳定性简化了更新。
购买 NVIDIA AI Enterprise 软件套件时会附带 NVIDIA 人工智能企业支持服务。我们提供与 NVIDIA AI 专家的直接联系、定义的服务级别协议,以及通过长期支持选项控制升级和维护时间表。
为企业级生成人工智能提供动力
作为 NVIDIA AI Enterprise 4.0 的一部分,NeMo 提供了跨多个平台的无缝兼容性,包括云、数据中心,以及现在由 NVIDIA RTX 供电的工作站和 PC。这实现了真正的一次性开发和随时随地部署体验,消除了集成的复杂性,并最大限度地提高了运营效率。
NeMo 在希望构建定制 LLM 的前瞻性组织中已经获得了巨大的吸引力。Writer 和 Korea Telecom 已经接受了 NeMo ,并利用其能力推动其人工智能驱动的举措。
NeMo 提供的无与伦比的灵活性和支持为企业打开了一个充满可能性的世界,使他们能够根据自己的特定需求和行业垂直领域设计、培训和部署复杂的 LLM 解决方案。通过与 NVIDIA AI Enterprise 合作并将 NeMo 集成到其工作流程中,您的组织可以开启新的增长途径,获得有价值的见解,并向客户、客户和员工提供尖端的人工智能应用程序。
开始使用 NVIDIA NeMo
NVIDIA NeMo 已成为一种改变游戏规则的解决方案,弥合了生成性人工智能的巨大潜力与企业面临的现实之间的差距。作为 LLM 开发和部署的综合平台, NeMo 使企业能够高效、经济地利用人工智能技术。
有了这些强大的能力,企业可以将人工智能集成到运营中,简化流程,增强决策能力,并开启新的增长和成功途径。
了解更多关于 NVIDIA NeMo 以及它如何帮助企业构建可生产的生成人工智能的信息。



