
您是否曾想构建自己的推理模型,但认为它过于复杂或需要大量资源?再想想。借助 NVIDIA 强大的工具和数据集,您可以在大约 48 小时内训练一个高效的小型推理模型,而这一切都发生在单个 GPU 上。更棒的是,我们已经为您提供了所有可用的代码,以便您立即开始使用。
我们来深入了解一下。
数据集和代码的快速链接:
- Hugging Face:Llama Nemotron 后训练数据集
- GitHub:NVIDIA NeMo Curator 的数据管护代码
- GitHub:使用 NVIDIA NeMo 框架训练和评估代码
推理模型和测试时计算
推理 (或思维) 语言模型的出现具有变革性意义。通过利用测试时计算扩展定律,在生成最终答案之前,更多的时间用于生成 token 并对问题的各个方面进行内部推理。这使得他们非常擅长处理需要深度批判性思维和推理的任务,例如数学和编码。这一进步标志着在各种环境中训练和使用语言模型的方式发生了范式转变。
NVIDIA 率先推出 Llama Nemotron 开放模型系列,专为各种任务的高性能推理而设计。如需详细了解这些模型,请查看这篇博客文章。本博客中讨论的原则也适用于其他领先模型,例如 ServiceNow 的 Apriel Nemotron 15B,强调了推理模型在企业问题领域中的更广泛相关性。如需详细了解此模型,请查看这篇博客文章。
从“关闭推理”到“开启推理”:可控推理模式
Llama Nemotron 模型的一项关键创新是其动态推理开关,允许用户在推理过程中通过系统提示中的简单指令在标准聊天 (“推理关闭”) 和高级推理 (“推理开启”) 模式之间切换。这种灵活性允许优化资源利用率:为科学分析或编码等复杂任务使用深度推理功能,同时恢复到轻量级模式以实现更简单的交互,从而降低延迟和计算成本。
用于推理的开放式后训练数据集
为了增强开发者社区的能力,NVIDIA 开源了 Llama Nemotron 模型后训练流程中使用的大部分数据。Llama Nemotron 后训练数据集包含数学、编码、聊天和科学等领域的 3200 多万个样本,为从业者训练自己的推理模型奠定了基础。此数据集是教会模型如何控制其推理模式的关键,可镜像 Llama Nemotron 功能。
在本博文中,我们将探讨如何利用 Llama Nemotron 后训练数据集、NVIDIA NeMo Curator 和 NVIDIA NeMo 框架,在周末训练您自己的推理语言模型。
Llama Nemotron 后训练数据集的解剖结构
Llama Nemotron 后训练数据集经过精心合成,可增强 LLM 的推理能力。它分为不同的子集,用于监督式微调 (SFT) 或强化学习 (RL) ,包含来自各种问题领域的样本。以下是撰写本文时不同领域的样本细分。
| 类别 | 样本计数 |
| 数学 | 22066397 |
| 编码 | 10108883 |
| 科学 | 708920 |
| 说明如下 | 56339 |
| 聊天 | 39792 |
| 安全性 | 21426 |
| 总样本数 | 32011757 |
此数据集中的所有样本均为 JSON 行 (JSONL) 格式,并包含许可证类型、源模型以及使用该样本训练的 Llama Nemotron 模型等元数据。每个样本都包含提示词、预期响应 (包含详细的思维链 (CoT) 推理轨迹,然后是响应 (即“逻辑推理”)) ,以及具有直接响应 (即“逻辑推理”) 的样本。更具体地说,每个样本都具有以下属性:
input:多轮聊天完成消息格式的模型提示。它始终以角色为user的消息开始,然后是零或更多回合,并以角色为assistant的消息结束,例如:
[
{"role": "user", "content": "Can you help me understand the Pythagorean theorem?"},
{"role": "assistant", "content": "The Pythagorean theorem states that... Does that make sense?"},
{"role": "user", "content": "Yes, but I have a follow up question..."},
#
# ... (zero or more messages),
#
{"role": "assistant", "content": "Sure, happy to help!"},
]
output:模型的预期响应 (真值) ,例如:
The Pythagorean theorem states that in a right triangle, the square of the hypotenuse equals the sum of the squares of the other two sides: a² + b² = c².
reasoning:示例是否用于推理“开启”模式。 如果值为“on”,则输出包含内部编码的详细 CoT 追踪<think></think>后跟输出,例如:
<think>
Hmm so the user is asking about the Pythagorean theorem. If I remember correctly...
</think>
The Pythagorean theorem states that in a right triangle, the square of the hypotenuse equals the sum of the squares of the other two sides: a² + b² = c².
-
- 如果值为“
off”,则输出不包含任何推理轨迹,而是包含直接响应。
- 如果值为“
system_prompt: (建议的) 用于控制系统推理模式的系统提示。对于 Llama Nemotron 训练,系统提示始终为“detailed thinking on”或“tg_ 13”。不用说,此字段与字段“reasoning”中的值相关联 (反之亦然) 。category:示例类别,例如数学、编码、科学、指令遵循、聊天或安全。license:与该示例关联的许可证。generator:用于合成样本的生成器模型,例如 DeepSeek-R1 等。used_in_training:使用此样本进行训练的 Llama Nemotron 模型列表。例如,[“Ultra”, “Nano”]表示此示例用于训练 Llama Nemotron Nano 和 Ultra,而非 Super。version:与每个示例关联的版本标签。由于新样本会随着时间的推移添加到此数据集中,因此此版本标签有助于识别特定样本的添加时间。
通过 3 个简单步骤从 0 到推理
我们来回顾一下我们用于训练小型推理模型的训练和数据管护方法。我们利用 Llama Nemotron 后训练数据集,使您的模型能够学习类似于我们上述内容的可控推理。
训练您自己的推理模型通常涉及数据管护、微调和评估。本节中,我们将介绍一个经过验证的方法,让您只需 48 小时即可在单个 GPU 上训练模型。请注意,我们的 recipe 使用监督式微调 (SFT) 来增强推理能力。虽然强化学习 (RL) 也是一种选项,但最近的研究表明,多通道方法 (即。SFT 之后是 RL) 会产生最佳结果。
注意事项
- 数据集合成:Llama Nemotron Post-Training 数据集很大,因此您需要整理一个重点突出的子集,强调推理。对于实际使用情况,请优先考虑与领域特定任务高度一致的样本,并考虑使用您自己的领域特定样本进行增强。
- 基础模型选择:鉴于时间和计算限制,教授小模型进行推理具有挑战性,因此基础模型的选择至关重要。我们建议从至少 80 亿参数的模型开始。我们使用了 Llama 3.1 8B Instruct,效果不错。
- 微调技术:完全微调 80 亿参数模型的所有权重至少需要 8 个 GPU、积极的内存优化技术和大量时间!但是,我们在使用 LoRA 适配器的参数高效微调 (PEFT) 中观察到了类似的结果。事实上,您可以在 48 小时内为单个 NVIDIA H100 GPU 上的 80 亿参数模型微调 LoRA 适配器。
- 评估:发布微调后,使用标准基准评估模型,并将其性能与原始基础模型进行比较,以评估改进情况。
第 1 步:使用 NVIDIA NeMo Curator 处理数据
高质量数据是强大推理模型的基石。Llama Nemotron Post-Training 数据集的子集方法有很多,但我们建议从数学子集和聊天子集开始,因为它们包含与领域无关推理的有力示例。
为了获得良好的结果,我们建议使用包含至少 50 万个样本的数据处理管道,并均衡混合“推理”和“推理”示例。以下是一种推荐的过滤和处理方法:
- 选择合适的小子集 使用 Llama Nemotron Nano 样本:从这些预先审核的高质量样本开始,这些样本用于 Llama Nemotron Nano 训练。 选择关键子集:仅选择
math_v1.1和 tg_ 22 子集,实现与领域无关的强推理。 按语言筛选:按语言识别删除所有非英语样本,以确保数据集的一致性。 - 过滤样本 强制答案格式:丢弃 LaTeX
\boxed{}格式中没有最终答案的数学样本。 排除拒绝示例:排除启用思考模式但为空<think></think>标签的示例。这些通常是拒绝样本,是额外安全训练所必需的,但为简单起见,我们可以丢弃它们。 限制样本长度:过滤出超过固定令牌限制 (例如。应用分词器的聊天模板后,为 8k 或 16k。 - 应用聊天模板:使用一致的聊天风格模板 (例如系统/ 用户/ 助理角色) 格式化所有训练样本。对于使用聊天模板训练的指令遵循模型来说,这是必需的,有助于模型更好地泛化到下游聊天界面。
- 通过系统提示进行推理模式:在系统提示中添加控制语句,以指示是否应启用推理。Llama Nemotron 模型使用“
detailed thinking on”或“tg_ 26”等短语来控制这种行为。
- 利用课程学习:按照难度不断增加的顺序对样本进行分类。您可以使用完成令牌计数来衡量样本难度。您可以随意尝试不同的方案。 将数据分为“逻辑推理”和“逻辑推理”两类。 通过增加完成长度对每个桶进行排序 (作为难度的替代) 将每个桶中的样本交错放置,逐渐引入复杂性。
您可以使用 NVIDIA NeMo Curator 高效实施此工作流。为了帮助您入门,我们在 GitHub 上发布了一个简单易懂的工作流。即使没有 GPU,它也能在有限的硬件上本地运行。请在此处查看代码。
NeMo Curator 工作流演示了框架中可用的各种设施 (例如语言识别和分布式处理) ,可快速处理 Llama Nemotron 后训练数据集的子集以进行微调。您可以根据需要轻松修改此工作流,并根据领域或业务的特定需求进行调整。
根据我们上面提供的建议,以下是一些入门命令。
从 Hugging Face 获取数据集 (需要约 130GB 的磁盘空间) :
$ git lfs install
$ git clone https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset
获取 FastText 语言识别模型:
$ wget https://dl.fbaipublicfiles.com/fasttext/supervised-models/lid.176.ftz -P ./
启动包含 8 个 worker 的数据管护工作流:
$ python main.py \
--input-dir "/path/to/Llama-Nemotron-Post-Training-Dataset/SFT" \
--remove-columns "version" "license" "generator" "category" "used_in_training" "system_prompt" "reasoning" \
--filename-filter "chat" "math_v1.1" \
--tokenizer "meta-llama/Llama-3.1-8B-Instruct" \
--lang-id-model-path "/path/to/lid.176.ftz" \
--max-token-count 8192 \
--max-completion-token-count 16384 \
--output-dir "/path/to/curated-data" \
--json-blocksize "100mb" \
--n-workers 8 \
--device "cpu"
上述工作流完成执行后,精选数据集将被写入指定的输出路径。输出将以多个 JSONL 文件的形式写入。这是因为大型输入数据集被划分为较小的分区,以便每个分区都可以并行处理。
每个 JSONL 文件都采用 input/output 格式。对于每个文件中的每条记录,input 字段包含模型输入,即系统提示和用户消息 (在使用指定的分词器进行聊天模板转换后) ,tg_ 32 字段包含来自模型的预期响应,包括分词器的聊天模板添加的任何特殊标记 (例如,回合结束或句子结束标记) 。
要将所有不同的分区组合成一个 JSONL 文件,请运行以下命令:
$ find /path/to/curated-data -type f -name "*.jsonl" -size +0c -print0 | xargs -0 cat | awk 'NF' > training.jsonl
这将创建一个名为 training.jsonl 的 JSONL 文件,其中包含大约 170 万个样本。您可以直接将此生成文件与 NVIDIA NeMo 框架训练脚本一起使用,无需修改。
第 2 步:训练
我们试验了从 3B 到 8B 参数的基础模型,以及从 16 到 128 的 LoRA rank。Llama 3.1 8B Instruct 是始终提供强大推理性能的最小模型,其中 LoRA 排名第 64 位是最佳点。
成功训练的几个关键因素:
- 高学习率可加速收。
- 课程学习使用难度逐渐增加的样本,显著提高了稳定性和最终性能。
- 批量大小至少为 256。
完整的训练超参数如下表所示:
| 超参数 | 价值 |
| LoRA | |
| 排名 | 64 |
| Alpha | 128 |
| 学习率 | 0.0001 |
| 调度程序 | 余弦 |
| 热身步骤 | 占总训练步骤的 5% |
| 权重衰减 | 0.001 |
| 批量大小 | 256 (具有梯度累积) |
| 训练步骤 | 至少 2000 步 |
我们使用单个 NVIDIA H100 80GB GPU 对模型进行了约 30 小时的训练。值得注意的是,经过大约 13 个小时的训练 (在逐步检查大约 100000 到 130000 个样本后) ,就出现了一致的推理行为。
如果您的 GPU 显存低于 80GB,您可以减小 (设备上) 批量大小并增加梯度累积步骤,以保持更大的有效批量大小,同时仍然能够使用较低的显存容量进行训练。
我们在 GitHub 上为您准备了一个 Jupyter Notebook,该 Notebook 使用 NVIDIA NeMo 框架为上述训练工作流设置了适当的超参数。此 Notebook 将为您介绍各种可用于微调模型的设置。此外,如果您选择执行完整模型微调 (而非 PEFT) ,此 Notebook 还为您提供了一个选项。
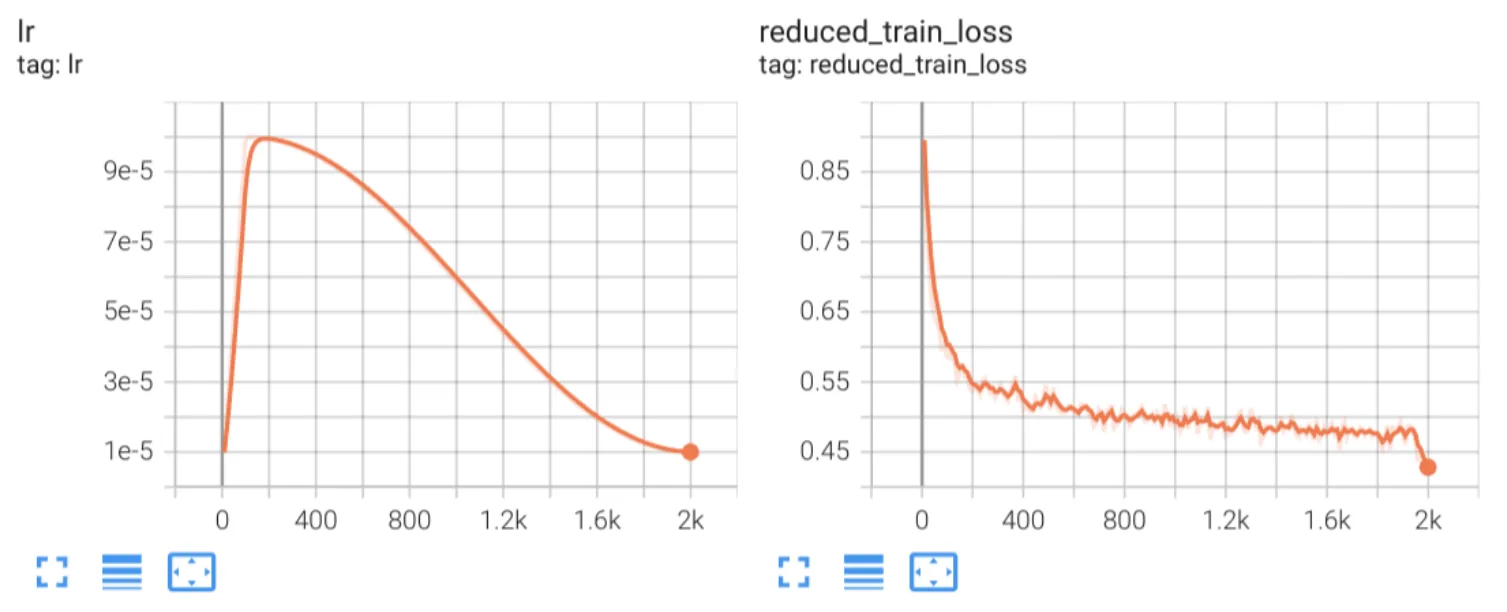
以下是我们自己的实验中的损失图,使用过滤和数据管护工作流中的前 500000 个训练样本 (批量大小为 256 和 2000 个训练步骤) 微调 rank 为 64 的 LoRA 适配器,供您参考。
你可能会想知道损失最终会突然下降。这是预期结果。回想一下,我们精心策划的数据集按照课程学习的样本难度不断增加的顺序排列。有 50 万个训练样本,批量大小为 256 步和 2000 步,这只是训练 1 次多一点。训练结束时,当模型再次看到前几个 (更简单的样本) 时,它可以轻松预测这些样本的正确标记,因此损失值最终会更低。
第 3 步:评估
完成训练后,评估模型以确认已学习推理能力至关重要。我们建议:
- 根据基础模型进行基准测试:对推理密集型任务进行并行比较,以评估改进情况。
- 标准和特定领域的基准测试: 对 MMLU、GPQA Diamond、GPQA Main 或 OpenBookQA 等数据集进行评估,以了解模型的整体功能。 评估特定领域的数据,以清晰了解模型在生产环境中的行为。
- 手动检查:“推理开启”和“推理关闭”模式的输出样本,以验证可控性和一致性。只需确保正确设置聊天模板和系统提示即可。
我们来深入探讨上述三项建议,看看经过训练的模型的表现如何。
我们准备了一组脚本,以便根据 GPQA Diamond、GPQA Main 和 MMLU 数据集上的基础模型对训练好的模型进行基准测试。单击此处查看这些脚本,可以对其进行扩展,以整合其他基准测试数据集。这些脚本演示了数据集的下载和准备、模型部署以及运行相关基准测试。
评估的第一步是准备用于模型评估的数据集。我们从 Hugging Face 下载 MMLU、GPQA Diamond 和 GPQA 主要数据集,并对数据进行预处理,将其重新排列为问题和选择,并将正确答案重新排列为多项选择选项之一 (“A”、“B”、“C”、“D”) 。
接下来,我们将部署和评估经过训练的适配器以及底座。在此步骤中,我们将使用提供 OpenAI API 端点的 Triton 推理服务器启动服务器并部署模型。the /v1/chat/completions/ 端点允许与模型进行多轮对话式交互。此端点接受具有不同角色 (系统、用户、助手) 的结构化消息列表,以维护上下文并生成类似聊天的响应。在引擎盖下,应用聊天模板将对话转换为单个输入字符串。
为了使用“详细思考”来部署经过训练的模型,我们可以使用以下聊天模板:
chat_payload = {
"messages": [{"role": "system", "content": "detailed thinking on"}, {"role": "user", "content": prompt}],
"model": model_name,
"max_tokens": 20000,
}
同样,对于“详细思考”模式,您可以使用以下聊天模板:
chat_payload = {
"messages": [{"role": "system", "content": "detailed thinking off"}, {"role": "user", "content": prompt}],
"model": model_name,
"max_tokens": 20000,
}
max_tokens 会考虑输入、系统提示和响应表单模型所需的令牌。
最后,我们通过提取最终答案来比较真值响应和上一步中生成的模型响应,以计算准确率。
基于上述过程,当比较基础模型与经过训练的网卡时,我们观察到以下评估结果:
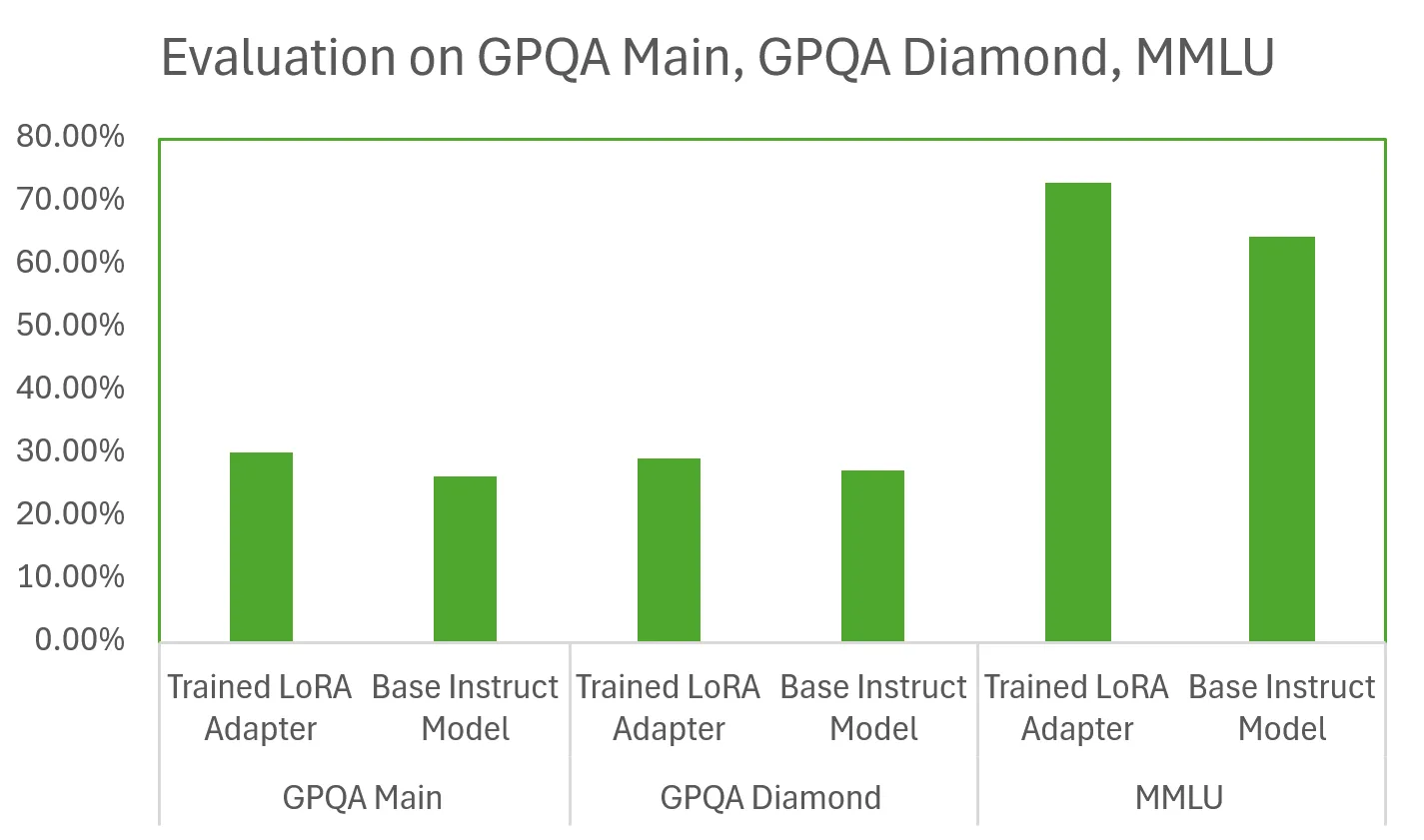
这些结果表明,经过训练的 LoRA 适配器在各种基准测试中的表现优于基础指令模型,有时甚至超过 10 个点。这些结果非常重要,因为我们的模型仅使用单个 GPU 在相对较少的训练样本上训练了 48 小时。LLM 扩展定律预测,通过增加训练样本数量和分配的训练时间,我们可以训练更强大的推理模型。如果您更喜欢使用微服务而不是框架来简化评估,请查看 NVIDIA NeMo Evaluator 微服务。NeMo Evaluator 可简化生成式 AI 应用的端到端评估,并提供 LLM 评判功能,以及适用于各种自定义任务和领域 (包括推理、编码和指令遵循) 的全套基准和指标。
结论和后续步骤
在这篇博客中,我们介绍了一种简单且计算高效的推理模型训练方法,其中基于 Llama Nemotron 后训练数据集精选了少量训练数据。我们讨论了基于 LoRA 适配器训练的策略,并重点介绍了在 48 小时内成功教授小语言模型进行推理的关键因素和超参数。通过评估,我们证明,经过训练的 LoRA 适配器在 GPQA 和 MMLU 数据集上的性能明显优于基础指令模型。
由于我们的模型仅使用数学和聊天数据进行训练,因此其推理能力将是通用的。通过引入特定领域的数据,您可以训练精通与您的应用程序或业务需求相关的问题领域的模型。
要训练您自己的推理模型或复制本教程,请单击以下链接:
- Hugging Face:Llama Nemotron 后训练数据集
- GitHub:NVIDIA NeMo Curator 的数据管护代码
- GitHub:使用 NVIDIA NeMo 框架训练和评估代码
致谢
我们要感谢 Christian Munley 在这项工作中提供的宝贵帮助






