
NVIDIA NeMo Parakeet 是一个端到端平台,用于在任何地方(任何云端和本地)大规模开发多模态生成式 AI 模型,包括自动语音识别 (ASR) 模型。这些最先进的 ASR 模型是与 Suno.ai 合作开发的,能够极其准确地转录英语口语。
本文详细介绍了 Parakeet ASR 模型在语音识别领域的新突破。
隆重推出 Parakeet ASR 系列
四个已发布的 Parakeet 模型基于递归神经网络传感器 (RNNT) 或 connectionist Temporal Classification (CTC) 解码器。它们拥有 0.6 B 和 11 B 参数,可处理各种音频环境,表现出对音乐和静音等非语音片段的弹性。
这些模型基于广泛的 64000 小时公有和专有数据集进行训练,在各种口音和方言、人声范围以及不同的域和噪音条件下表现出出色的准确性。
| 模型 | 准确性/速度权衡 | 用例 |
| Parakeet CTC 1.1 B Parakeet CTC 0.6 B |
|
|
| Parakeet RNNT 1.1 B Parakeet RNNT 0.6 B |
|
|
使用 Parakeet ASR 模型的优势
Parakeet 模型使用 NeMo 框架构建,优先考虑用户友好性和灵活性。预训练检查点随时可用,因此可以轻松将这些模型集成到项目中。可以立即按原样部署这些模型,或针对特定任务进行进一步微调。
以下是 Parakeet 模型的主要优势:
- 卓越的准确性:在不同的音频源和领域中实现了出色的词错误率 (WER) 准确性,并对非语音片段具有强大的可靠性。
- 开源和可扩展性:无缝集成和定制化功能。
- 预训练检查点:可随时用于推理或进一步微调。
- 不同的模型规模:模型规模分别为 0.6 GB 和 1.1 GB,足以有效地理解复杂的语音模式。
- 许可:模型检查点在 CC-BY-4.0 许可下发布,可用于任何商业应用。
尝试 parakeet-rnnt-1.1B 模型的 Gradio 演示。有关工具包的更多信息,请参阅 NVIDIA/NeMo GitHub 库。
深入了解 Parakeet 架构
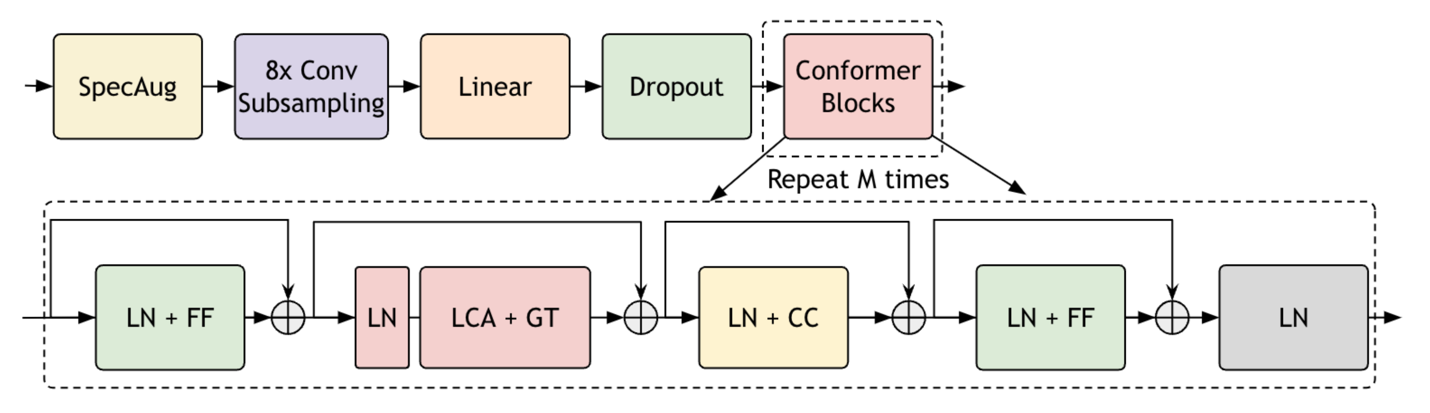
Parakeet 模型基于 FastConformer 优化的 Conformer 模型,其特点包括 8 倍的深度可分离卷积下采样、修改卷积核大小以及高效子采样模块。
Parakeet 架构旨在支持使用本地注意力在 NVIDIA A100 GPU 80GB 卡上对长音频片段 (长达 11 小时的语音) 进行推理。使用 RNNT 或 CTC 解码器对模型进行端到端训练。
想要了解更多有关长音频推理的信息,请参阅 ICASSP 2024 论文,该论文研究用于长格式音频转录的端到端 ASR 架构。
基于 Parakeet FC 的模型在推理和训练速度方面表现出色,可无缝应对内存限制。通常情况下,模型在不同的推理场景下通常具有不同的实时系数 (RTF) 分数。
我们通常会在整个数据集上测量 RTF,这些数据集由具有固定批量大小的不同音频文件组成。在这种情况下,我们将 RTF 计算为 ASR 系统转录单个音频片段所需的时间除以不同大小的 Parakeet 模型的语音总持续时间。在这种情况下,我们会测量模型转录长音频文件的速度,由于注意力模型相对于音频长度的二次计算复杂性,该文件通常无法被注意力模型处理。
表 2 显示了 RTF 和 NVIDIA A100 80GB 卡上用于推理的输入音频的最大持续时间 (一次传递)。
| 大小 | 全注意力模式下的音频最大持续时间[分钟] | RTF 30 秒音频 (RNNT) | RTF 30 秒音频 (CTC) | 上下文受限时的最长持续时间[小时] |
| 120M | 30 | 11.8 e-3 | 1.5 e-3 | 14 |
| 60 亿 | 30 | 13.3 e-3 | 2.0 e-3 | 13 |
| 11 亿 | 30 | 14.6 e-3 | 3.4 e-3 | 12.5 |
在上下文注意力有限的情况下,即使是最大的模型也可以一次推理长达 13 小时的音频。
具有 1B 参数的 Parakeet 模型一次可以处理 12.5 小时的音频,而中型 (0.6 B) 模型可以处理 13 小时。CTC 模型在推理速度方面表现出色,CTC RTF 为 2e-3,30 秒音频,是转录会议音频的理想选择。
FastConformer 在上下文注意力有限的情况下使用全局令牌进行微调,即使在处理大量长格式音频数据集时也能实现更高的准确性 (表 3)。
| 模型 | TED-LIUM3 | 收益 21 | 收益 22 | CORAAL |
| 上下文注意力受限的 FC | 5.88 | 17.08 | 24.67 | 37.35 |
| *微调 | 5.08 | 14.82 | 20.44 | 30.28 |
| 全局令牌 | 4.98 | 13.84 | 19.49 | 28.75 |
如何使用 Parakeet 模型
要使用 Parakeet 模型,请将 NeMo 安装为 pip 包。在安装 NeMo 之前安装 Cython 和 PyTorch (2.0 及更高版本)。然后将 NeMo 安装为 pip 包:
pip install nemo_toolkit['asr'] |
安装 NeMo 后,评估音频文件列表:
import nemo.collections.asr as nemo_asrasr_model = nemo_asr.models.ASRModel.from_pretrained(model_name="nvidia/parakeet-rnnt-1.1b")transcript = asr_model.transcribe(["some_audio_file.wav"]) |
用于长形式语音推理的 Parakeet 模型
加载 Fast Conformer 模型后,您可以在构建模型后轻松地将注意力类型修改为有限的上下文注意力。您还可以为子采样模块应用音频分块,对大型音频文件执行推理。
这些模型经过全局注意力训练,切换到本地注意力会降低其性能。但是,它们仍然可以合理地转录长音频文件。
对于大型文件的有限上下文注意力 (在 A100 GPU 上最多需要 11 小时),请执行以下步骤:
# Enable local attentionasr_model.change_attention_model("rel_pos_local_attn", [128, 128]) # local attn# Enable chunking for subsampling moduleasr_model.change_subsampling_conv_chunking_factor(1) # 1 = auto select# Transcribe a huge audio fileasr_model.transcribe([".wav"]) # 10+ hours! |
您可以在自己的数据集上针对其他语言微调 Parakeet 模型。以下是一些实用教程:
- 通过 NeMo 清单格式对数据进行微调:ASR CTC 语言微调指南
- 对 Hugging Face 数据集格式的数据进行微调:ASR 模型与使用 HF 数据集的传感器模型教程。
结束语
NeMo 模型提高了英语转录的准确性和性能,为企业和开发者提供了一系列选项,用于具有不同语音模式和噪音级别的真实应用程序。有关更多信息,请参阅 NeMo 模型页面。
欲了解 Parakeet ASR 模型的架构详细信息,请参阅 具有线性可扩展注意力的快速变形器:高效语音识别 和 适用于长格式音频转录的端到端 ASR 架构。
在最新的 NeMo ASR 模型中,Parakeet-CTC 已经发布。其他模型将在不久的将来作为 NVIDIA Riva 出现。尝试 Parakeet-RNNT-1.1B 的第一手资料,包括 Gradio 演示 和本地 GitHub 库。
通过 NVIDIA API 目录,并在本地使用 NVIDIA NIM 和 NVIDIA LaunchPad,您可以探索更多功能和工具。




