
这篇文章是关于 优化端到人工智能 的系列文章中的第五篇。
NVIDIA TensorRT 是一种在 NVIDIA 硬件上部署光速推理的解决方案。有了人工智能模型架构, TensorRT 可以在部署前使用,以过度搜索最有效的执行策略。
TensorRT 优化包括重新排序图中的操作,优化权重的内存布局,以及将操作融合到单个内核以减少 VRAM 的内存流量。要应用这些优化, TensorRT 必须具有完整的网络定义及其权重。
评估的策略在 TensorRT 引擎中序列化,该引擎与应用程序一起提供,以在生产中实现最佳推理性能。在部署过程中,除了这个引擎之外,不需要其他任何东西来执行网络。
包含已编译的内核和对文件的序列化使该引擎仅与相同 计算能力 的 GPU 兼容。该文件也特定于 TensorRT 版本,但将与 8.6 之后的未来版本兼容。
生成性能良好且正确的发动机
网络图定义及其权重可以从 ONNX 文件中解析,也可以使用 NetworkDefinition API 手动构建网络。手动构建图形提供了对 TensorRT 最细粒度的访问,但也需要付出最大的努力。
在给定 ONNX 文件上评估 TensorRT 的一种快速方法是使用 trtexec 。该工具还可以用于生成引擎文件,该文件可以稍后通过--saveEngine选项与 Python 或 C ++ API 一起部署。运行以下命令以创建引擎:
trtexec –onnx="model.onnx" –saveEngine="engine.trt"
当您通过 ONNX Runtime 使用trtexec时,只会暴露 TensorRT 或 TensorRT API 提供的一些 TensorRT 本机构建功能。有关通过 ONNX Runtime 的 TensorRT 的更多信息,请参阅 TensorRT Execution Provider 。
在这篇文章中,我简要讨论了使用trtexec从 ONNX 文件中获取高性能引擎所需的内容。大多数命令行选项可以很容易地转换为 TensorRT C ++/ Python API 函数。
为了研究 TensorRT 的性能、精度或兼容性,有用的工具包括 polygraph 或 trex 。如果图中的操作不是 supported by TensorRT ,则可以 write plugins 来支持引擎中的自定义操作。
在执行自定义运算符之前,请评估该操作是否可以通过其他 ONNX 运算符的组合来实现。
精确
TensorRT 性能与各自的操作精度 INT8 或 FP16 和 FP32 高度相关。
将trtexec与 ONNX 文件一起使用时,当前没有使用 ONNX 中指定精度的选项。但是,您可以启用 TensorRT 来将权重转换为相应的精度,并评估推理成本。使用--fp16或--int8。较低的精度通常会导致更快的执行,因此这些权重更有可能在生成的引擎中选择。
降低数值精度可能会影响模型质量,因此可以使用--layerPrecisions选项手动标记要以更高精度执行的特定图层。为了通过使用张量核心获得最佳性能,重要的是要有 tensor alignment ,例如 FP16 的八个元素。这不仅适用于 TensorRT ,而且适用于 ONNX optimization 。
当型号需要 FP32 精度时,默认情况下, TensorRT 仍在 NVIDIA Ampere 架构及更高版本上启用 TF32 ,但可以使用--noTF32禁用。当使用 TF32 时,卷积的被乘数被四舍五入到最接近的 FP16 当量。保留了 FP32 的指数,因此也保留了其动态范围。在这些乘法运算之后,使用 FP32 对卷积乘法运算的结果求和。有关更多信息,请参阅 TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x 。
输入格式
结合使用的精度,使用--inputIOFormats和--outputIOFormats更改 I / O 缓冲区类型也很有用。
由于张量核心需要 HWC 布局,如果可能的话,在该布局中摄取数据可能是有益的。这样, TensorRT 就不必进行内部转换,尤其是在 FP16 中已经存在数据的情况下。如果 HWC 和 FP16 中有数据,请运行以下命令进行编译:
--inputIOFormats=fp16:hwc --outputIOFormats=fp16:hwc
CHW 和 HWC 也支持所有其他精度。
工作区大小
正如我前面提到的, TensorRT 有不同的策略来执行图中的操作。例如,通过加载完整内核,可以在没有中间缓冲区的情况下执行 2D 卷积。
对于大内核,在两次 1D 卷积过程中执行卷积是有意义的,需要中间缓冲区。使用trtexec中的– memPoolSize 参数来指定 TensorRT 可以超额分配的最大 VRAM 数量。例如,–-memPoolSize=workspace:100将中间缓冲区的大小限制为 100 MB 。用这个值进行实验可以帮助您在推理延迟和 VRAM 使用之间找到平衡。
有关优化 TensorRT 推理成本的更多信息,请参阅 Optimizing TensorRT Performance .
部署目标
在找到使用 TensorRT 为网络提供服务的理想方式后,归根结底是如何部署该模型。
为此,确定必须满足的需求并比较策略是很重要的。这些都会随着部署目标的变化而发生重大变化:服务器、嵌入式或工作站。
对于服务器和嵌入式部署场景,硬件种类通常是有限的,这使得将专用引擎与二进制一起运送成为一个有吸引力的解决方案。
本系列文章的重点是工作站部署,必须考虑各种各样的系统。在开发过程中,最终用户工作站是完全未知的,这使得它成为最困难的部署场景。
TensorRT 在工作站上面临的挑战有两方面。
首先,根据人工智能模型的复杂性,在用户设备上编译引擎可能是一个漫长的过程(从几秒钟到几分钟),例如,这可能隐藏在安装程序中。理想情况下, GPU 应在发动机生成期间处于怠速状态,因为推断是在[Z1K1’上计时的,并且选择了性能最佳的。在 GPU 上运行任何其他任务同时会扭曲时序并导致次优执行策略。
其次, TensorRT 引擎特定于特定的计算能力(例如,对于 NVIDIA Ampere 和 NVIDIA Ada Lovelace 架构)。对于单个模型,您需要运送多个预编译的引擎来支持多个 GPU 。当您试图从 GPU 中挤出最佳推理性能时,您必须为每个 GPU SKU (例如 4080 、 4070 和 4060 )提供一个引擎,而不是为整个计算能力提供一个。运送许多相同型号的发动机是违反直觉的。这通常是不可行的,因为每个发动机都已经拥有了所有需要的重量,而且这只会使二进制装运量增加。
基于这些挑战,有两种解决方案最适合工作站:
- 装运预制发动机
- 运送预先填充的定时缓存
对于这两种方法,在部署之前必须在所有受支持的 GPU 体系结构上编译引擎。
请注意,这些解决方案不仅仅是第一次部署时的考虑因素,因为工作站硬件可能会发生变化。如果您决定将 GPU 升级到最新一代,则必须生成一个新的引擎。
装运预制发动机
运送预构建的引擎对于服务器或嵌入式设备特别有用,通常是最好的解决方案。在这些场景中,硬件是已知的,并且可以将适合该硬件的引擎包含在部署二进制文件中。
对于工作站来说,运送所有所需的发动机通常是不可行的。必须在安装期间或请求特定功能时执行下载。
对于此下载,您必须查询 GPU 的计算能力并下载相应的引擎。在这种情况下,除了共享库之外, TensorRT AI 部署根本不会影响应用程序的交付规模。例如, ONNX 文件形式的原始权重和网络定义不必发货。
通常, TensorRT 引擎比其对应的 ONNX 文件小得多。这样做的明显缺点是无法进行离线安装。如今,这不一定是个大问题。
| Name | Engine size (MB) |
| RoBERTa | 475 |
| Fast Neural Style Transfer | 3 |
| sub-pixel CNN | 0 |
| YoloV4 | 125 |
| EfficientNet-Lite4 | 25 |
运送预先填充的定时缓存
首先,我想解释什么是定时缓存,以及如何获取定时缓存。
在构建引擎时,可以评估评估的执行计划的推断时间。可以通过trtexec的--timingCacheFile选项将此计时的结果保存到计时缓存中,以便以后重用。
定时缓存不必是特定于型号的。事实上,我建议对所有 TensorRT 构建过程使用系统范围的定时缓存。每当需要内核定时时,进程都会检查定时缓存,并跳过定时或扩展定时缓存。这大大缩短了发动机的制造时间!
定时缓存通常只有几 MB 大,甚至不到 1MB 。这使得在应用程序的初始二进制文件中包含多个缓存成为可能,并大大减少了构建时间。
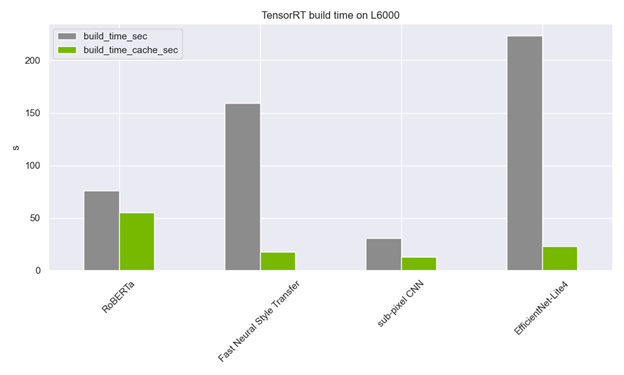
仍然需要在多个计算功能上预编译所有引擎以填充缓存。但是,对于装运,只需要一个小的附加文件。
与引擎一样,理想的情况是每一个 GPU 都有一个缓存,但也可以在整个计算能力中进行 ignore those mismatches 部署。有了这个文件,在用户端构建引擎是一个仅限 CPU 的操作,可以在安装期间完成,而不用担心定时期间会出现繁忙的 GPU 。使用这种运送定时缓存和 ONNX 模型的方法,可以在用户设备上实现可控的引擎构建过程,而无需按需下载文件。
使用新的启发式算法选择(--heuristic标志)可以进一步加速。它目前只修剪了不太可能是最快的卷积策略,但它将在未来的版本中扩展到其他操作。
结论
这篇文章展示了在不运送大量二进制文件的情况下将 TensorRT 引擎部署到工作站的选项。这些选项还可以避免在繁忙的情况下让您经历耗时且可能不正确的构建过程 GPU 。
本文中提到的所有trtexec选项都可以在trtexec的 开源代码 中找到,也可以在 C ++或 Python API 文档中搜索相应的功能。
阅读后,您应该能够决定哪种方法是应用程序的最佳部署选择,并在二进制大小和用户设备上的计算时间之间找到平衡。请注意,在多个模型上混合使用策略也是一种选择。
对于常用的模型,您可能希望在安装程序中使用定时缓存对其进行编译。对于并非所有用户都需要的其他型号,请按需下载相应的 ONNX 或 TensorRT 引擎。
在我们的论坛 AI & Data Science 中了解有关 TensorRT 部署的更多信息。
从 3 月 21 日至 23 日免费参加 GTC 2023 ,并观看我们的 AI for Creative Applications 课程。




