
零售商的供应链包括从供应商处采购原材料或成品;将其储存在仓库或配送中心;并将其运送至商店或顾客;管理销售。他们还收集、存储和分析数据,以优化供应链性能。
零售商有团队负责管理供应链的每个阶段,包括供应商管理、物流、库存管理、销售和数据分析。所有这些团队和流程协同工作,以确保在正确的时间以正确的价格向客户提供正确的产品。
通过收集、分析和解释来自各种来源的数据,如销售点( POS )系统、客户数据库和市场调查,对零售销售和运营做出明智的决策是很重要的。
大数据处理是零售分析的一个关键组成部分,因为它使零售商能够以低延迟处理和分析来自各种来源的大量数据。零售商可以获得对客户行为、市场趋势和运营效率的宝贵见解。
这篇文章概述了可以从 Spark 加速的 Apache GPU 工作负载中受益的零售应用程序。我们通过一个示例零售用例提供了详细的分步说明,说明如何在 Dataproc 上的 Spark 工作负载上开始使用 GPU 加速。该示例向您展示了如何加快零售商的数据处理管道。我们重点介绍了 Dataproc 的新 RAPIDS 加速器用户工具,这些工具可以帮助您设置应用程序调优,还可以深入了解 GPU 的运行细节。
要继续阅读本文,请访问 NVIDIA/spark-rapids-examples GitHub 存储库上的笔记本。

零售应用程序的数据分析类型
根据您的业务问题和目标,可以对零售数据执行几种类型的复杂分析:
- Inventory forecasting: 分析销售趋势、需求和库存数量,以预测未来的库存需求。
- Demand forecasting: 预测未来客户对产品的需求,以优化库存水平、定价和促销活动,从而满足该需求。
- Price optimization: 分析竞争对手的价格、货物成本和运输成本,以确定每种产品的最佳价格。
- 销售业绩分析: 分析个人客户的销售状态和购买历史,以确定模式和目标营销努力。
- Supply chain analysis: 分析供应商 ID 、运输成本和仓库成本,以确定节约成本和提高效率的机会。
- Customer segmentation: 分析客户人口统计、购买历史和联系信息,以细分客户和目标营销工作。
- Product analysis: 分析不同产品的销售情况,确定最畅销的产品和潜在的新产品。
- Location analysis: 分析销售地点,并确定可扩展到的潜在新地点。
- 零售降价优化: 分析大量数据,以取代手动降低产品价格的过程。
例如,您可以通过处理来自不同来源的最新产品销售数据来优化店内或在线库存水平。
零售数据源
零售数据可以来自多种来源:
- Sales data: 正在销售的产品的数据,如产品名称、价格、销售数量和销售日期。这些数据可以来自 POS 系统、在线销售平台或记录销售交易的其他系统。
- Stock data: 当前库存产品的数据,如产品名称、库存数量、库存位置和收到日期。这些数据可以来自库存管理系统、仓库管理系统或其他记录库存的系统。
- Supplier data: 从供应商处订购的产品数据,如产品名称、订购数量、价格和下订单日期。这些数据可以来自采购订单系统、供应链管理系统或记录供应商订单的其他系统。
- Customer data: 客户数据,如人口统计、购买历史和联系信息。这些数据可以来自客户关系管理( CRM )系统、电子商务平台或记录客户信息的其他系统。
- Market data: 关于市场状况、竞争对手的价格、销售趋势和需求预测的数据。这些数据可以来自外部来源,如市场研究公司、政府机构或其他数据提供商。
- Logistic data: 航运、运输和仓库管理等物流数据。这些数据可以来自物流管理系统、运输公司或其他记录物流信息的系统。
来自这些来源的数据可能有不同的格式( CSV 、 JSON 、 Parquet 等)。
在本文中,您将使用合成数据生成器代码来模拟前面解释的数据源和格式。下面的 Python 代码示例可以生成大量不同格式的合成销售数据、库存数据、供应商数据、客户数据、市场数据和物流数据。有一些数据质量问题可以作为模拟目的的示例。
# generate sales data
# Define the generate_data function which takes an integer i as input and generates sales data using random numbers. The generated data includes sales ID, product name, price, quantity sold, date of sale, and customer ID. The function returns a tuple of the generated data. The multiprocessing library is used to generate the data in parallel
def generate_data(i):
sales_id = "s_{}".format(i)
product_name = "Product_{}".format(i)
price = random.uniform(1,100)
quantity_sold = random.randint(1,100)
date_of_sale = "2022-{}-{}".format(random.randint(1,12), random.randint(1,28))
customer_id = "c_{}".format(random.randint(1,1000000))
return (sales_id, product_name, price, quantity_sold, date_of_sale, customer_id)
with mp.Pool(mp.cpu_count()) as p:
sales_data = p.map(generate_data, range(100000000))
sales_data = list(sales_data)
print("write to gcs started")
sales_df = pd.DataFrame(sales_data, columns=["sales_id", "product_name", "price", "quantity_sold", "date_of_sale", "customer_id"])
sales_df.to_csv(dataRoot+"sales/data.csv", index=False, header=True)
print("Write to gcs completed")
访问 spark-rapids-examples GitHub 存储库上的完整笔记本。
数据清理、转换和集成
在将原始数据用于分析之前,可能必须对其进行清理、转换和集成。这就是 Apache Spark SQL 和 DataFrame API 的用武之地,因为它们为处理结构化数据提供了一套强大的工具。他们可以处理来自不同来源的大量数据,以处理和提取有用的见解和信息。
首先,提取数据,这些数据可以是不同的格式,例如 CSV 、 JSON 或 Parquet 。然后,使用 DataFrame API 将数据加载到 Spark 中。 Spark SQL 用于执行数据清理和预处理任务:
- 删除缺失的值。
- 处理异常值。
- 将数据转换为合适的格式进行分析。
数据清理和预处理后,使用 Spark SQL 和 DataFrame API 进行各种类型的分析,以进行库存优化。
例如,您可以使用 SQL 查询分析销售数据,以确定最畅销和表现不佳的产品。要执行高级分析,如时间序列分析,请使用 DataFrame API 预测未来需求和优化算法,或分析数据集中的购买模式。
最后,应用分析结果来做出决策,例如库存中要持有多少库存,从供应商那里订购多少,以及何时这样做。使用 Spark 的 Dataframe API 或与其他系统集成来自动更新库存水平。
此外,使用 Spark SQL 和 DataFrame API 处理来自不同来源的大量数据,如销售、库存和供应商数据,可以实现更高效、更准确的库存管理系统。
您可以通过在 GPU 支持的 GoogleDataproc 集群上运行数据管道来加速这一过程并节省计算成本。本文的其余部分是关于创建 GPU 供电集群和使用 RAPIDS 加速器运行加速数据处理管道的过程的分步指南。
创建 RAPIDS 加速器 GPU 启用的 Dataproc 集群
零售商的各种数据源将其原始数据推送到 Google Cloud Storage ,后者作为在启用 GPU 的 Dataproc 集群上处理数据的源。在 Dataproc 集群中,您可以启用 Jupyter 实验室组件网关来运行笔记本电脑,该笔记本电脑在合并的数据上执行数据清理、合并和分析。
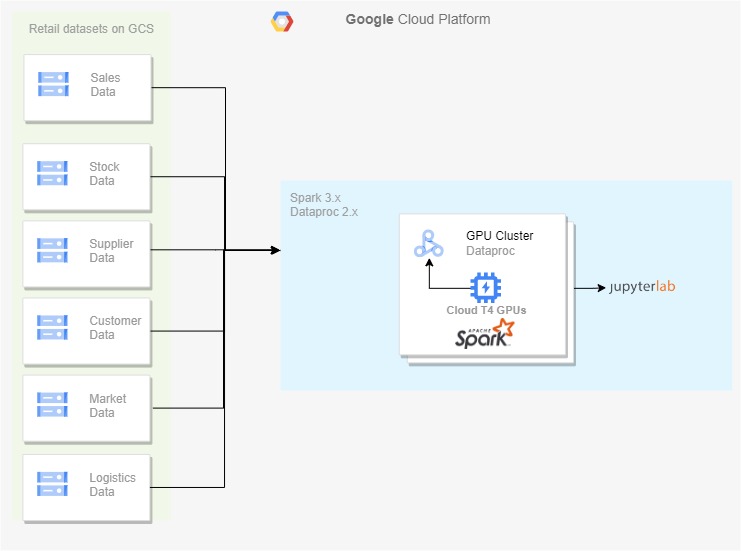
在图 1 中,我将生成的零售源数据集保存在云存储上,并使用 Dataproc 2.x 集群来处理数据。 RAPIDS 加速器的 GPU 启用可以基于该过程进行。
要创建启用 GPU 的 Dataproc 集群,请使用 Cloud shell 运行 shell 命令。要做到这一点,首先启用 Compute 和 Dataproc API 以获得对 Dataproc 的访问权限。此外,当您需要一个谷歌云存储桶来存储数据时,请启用存储 API 。此过程可能需要几分钟才能完成。
gcloud services enable compute.googleapis.com gcloud services enable dataproc.googleapis.com gcloud services enable storage-api.googleapis.com
以下示例配置可帮助您在 GCP 上运行 GPU 启用的工作负载。根据您的需要调整 GPU 的大小和数量。
要使用 RAPIDS 加速器启动启用 GPU 的群集,请在 CLI 中运行以下命令:
gcloud dataproc clusters create sparkrapidsnew \ --region us-central1 \ --subnet default \ --zone us-central1-c \ --master-machine-type n1-standard-8 \ --master-boot-disk-size 500 \ --num-workers 4 \ --worker-machine-type n1-standard-8 \ --worker-boot-disk-size 1000 \ --worker-accelerator type=nvidia-tesla-t4,count=2 \ --image-version 2.0-debian10 \ --properties spark:spark.eventLog.enabled=true,spark:spark.ui.enabled=true \ --optional-components HIVE_WEBHCAT,JUPYTER,ZEPPELIN,ZOOKEEPER \ --project PROJECT_NAME \ --initialization-actions=gs://goog-dataproc-initialization-actions-us-central1/spark-rapids/spark-rapids.sh --metadata gpu-driver-provider="NVIDIA" \ --enable-component-gateway
图 2 显示了创建一个 GPU 集群,每个集群在工作节点上有一个 T4 GPU 。初始化操作中的脚本在集群中安装最新版本的 RAPIDS 加速器库。

您还可以构建一个自定义的 dataproc 映像来加速集群初始化时间。有关更多信息,请参阅 Getting started with RAPIDS Accelerator on GCP Dataproc 快速入门页。
在 Jupyter 实验室运行 Py Spark
要将笔记本电脑与 Dataproc 群集一起使用,请选择 Dataproc 集群下的群集,然后选择 Web Interfaces, Jupyter Lab 。
数据清理
运行以下命令以完成这些任务:
- 读取 JSON 和 CSV 等不同格式的所有数据。
- 执行数据清理任务,例如删除缺失值和处理异常值。
- 执行数据转换任务,例如将日期列转换为日期类型和更改字符串的大小写。
# remove missing values
sales_df = sales_df.dropDuplicates()
# remove duplicate data
sales_df = salesdf.dropna()
# convert date columns to date type
sales_df = sales_df.withColumn("date_of_sale", to_date(col("date_of_sale")))
# standardize case of string columns
sales_df = sales_df.withColumn("product_name", upper(col("product_name")))
# remove leading and trailing whitespaces
sales_df = sales_df.withColumn("product_name", trim(col("product_name")))
# check for invalid values
sales_df = sales_df.filter(col("product_name").isNotNull())
清理完数据后,将所有数据连接到一个公共列(product_name或customer_name)上,并将清理和转换后的数据写入 Parquet 文件格式。
这是 Py Spark 如何用于在大型数据集上执行数据清理和预处理任务的示例。但是,请记住,具体的清洁和预处理步骤因数据的性质和分析要求而异。
零售数据分析
您可以使用 Py Spark 执行各种零售数据分析。在演示笔记本中, Py Spark 正在读取 Apache Parquet 格式的清理数据,根据某些条件创建新列,计算每个产品的滚动平均销售额,并使用窗口函数进行预测。
然后,它执行各种聚合和 group-by 语句以获得以下内容:
- 总销售额
- 按产品和地点划分的销售量
- 供应商的库存总量和总销售额
- 每个地点易腐产品与非易腐产品的对比数量
- 每个地点的良好销售状态与不良销售状态的对比数量
- 包含 10% 折扣促销的销售额计数
聚合的结果然后以 Apache Parquet 格式保存到磁盘。代码的执行时间也在测量和打印中。
具有优化设置的引导 GPU 集群
引导工具在 Dataproc 的 GPU 集群上的 Apache Spark 上应用 RAPIDS 加速器的优化设置。该工具获取集群的特征,包括工作者数量、工作者核心、工作者内存以及 GPU 加速器类型和计数。然后,t使用集群财产来确定运行 GPU 加速 Spark 应用程序的最佳设置。
Usage: spark_rapids_dataproc bootstrap --cluster <cluster-name> --region <region>
该工具生成以下示例输出:
##### BEGIN : RAPIDS bootstrap settings for sparkrapidsnew spark.executor.cores=4 spark.executor.memory=8192m spark.executor.memoryOverhead=4915m spark.rapids.sql.concurrentGpuTasks=2 spark.rapids.memory.pinnedPool.size=4096m spark.sql.files.maxPartitionBytes=512m spark.task.resource.gpu.amount=0.25 ##### END : RAPIDS bootstrap settings for sparkrapidsnew
调整 GPU 集群上的应用程序
Spark 应用程序在 GPU 集群上运行后,运行 profiling tool 分析应用程序的事件日志,以确定是否应配置更优化的设置。该工具输出每个应用程序的一组配置设置,以进行调整以增强性能。
Usage: spark_rapids_dataproc profiling --cluster <cluster-name> --region <region>
该工具生成以下示例输出:

通过优化设置,您可以运行数据清理和处理代码,并将其与 CPU 对应代码进行比较。您还可以分析 profiling tool output results ,并根据各自的见解进一步调整作业。
|
Pipeline step |
Data cleaning (CPU) |
Data analysis (CPU) |
Data cleaning (GPU) |
Data analysis (GPU) |
|
Dataproc cluster |
Five nodes n1-standard-8 |
Five nodes n1-standard-8 |
Five node n1-standard-4 +2 T4 / worker |
Five node n1-standard-2 +2 T4 / worker |
|
Time taken (secs) |
239 |
178 |
123 |
48 |
|
Cost ($) |
0.34 |
0.27 |
||
|
Yearly cost |
$2,978 |
$2,365 |
||
|
Yearly cost saving/workload |
|
$613 |
||
|
Cost savings % |
|
20% |
||
|
Speed-up |
|
2.45x |
||
表 1 。零售渠道 GPU Dataproc 上的加速和成本节约计算
首先,该管道仅在带有 CPU 的 Dataproc 集群上运行。然后,它在使用 T4 GPU s 启用的 Dataproc 集群的不同配置上运行。
表 1 显示,在 GPU 集群上运行管道的速度是等效的 CPU 集群的 2.45 倍,在迁移到 GPU 集群时可节省 20% 的成本。
接下来的步骤
将作业从 CPU 集群移动到 GPU 集群可能有不同的动机,例如提高性能、节省成本、满足 SLA 要求,或解决长期运行作业的任何资源争用问题。
此示例场景探讨了如何通过相应地配置集群大小来节省数据处理成本。您可以尝试 GPU 和虚拟机的不同组合来实现您的目标。
如果您希望加快数据处理、机器学习模型训练和推理,请加入我们的 GTC 2023 ,参加我们即将举行的 Accelerate Spark with RAPIDS For Cost Savings 会议,在会上我们讨论了显示利用 GPU 进行 Spark ETL 处理的性能和成本效益的基准。




