NVIDIA cuOpt 是一个加速优化引擎,专为解决复杂的路线规划问题而设计。它能够高效地处理各种问题,包括但不限于:休息和等待时间、车辆的多个成本和时间矩阵、多目标优化、订单与车辆的匹配、车辆的起始和结束位置、以及车辆的起始和结束时间等。
更具体地说,cuOpt 解决了两个问题的多个变体:时间窗口容量车辆路线规划问题 (CVRPTW) 和时间窗口拾货和交付问题 (PDPTW).这些问题的目的是满足客户请求,同时尽可能减少车辆数量和按相应顺序行驶的总距离。
cuOpt 在过去三年中设定的最大路由基准测试中打破了 23 项世界纪录,由 SINTEF 进行。
本文将探讨优化算法的关键要素及其定义,以及将 NVIDIA cuOpt 与该领域的领先解决方案进行基准测试的过程,并重点介绍这些比较的重要性。在整篇博文中,我们将术语“请求”用于 CVRPTW 的订单,以及用于 PDPTW 问题的取货 – 配送订单对。
尽管该领域存在各种限制和问题维度,但本文的范围仅限于容量和时间窗口限制。容量限制要求执行车辆随时的商品总量不得超过车辆容量。时间窗口限制强制要求在不早于时间窗口开始时间且不晚于时间窗口结束时间的情况下执行订单。
组合优化
组合优化问题是世界上计算成本最高的问题之一 (NP-hard),搜索空间中的可能状态数量是因乘问题。由于无法对大型问题使用精确算法,因此使用启发式算法将解决方案近似于优化点。启发式算法使用各种计算成本高昂且具有二次或更高计算复杂性的算法来探索搜索空间。
由于问题的复杂性和本质,我们可以使用大规模并行 GPU 加速这些算法。得益于 GPU 加速,我们可以在合理的时间内获得接近最佳的解决方案。
构建进化路线优化算法
典型的路由求解器包含两个阶段:生成初始解决方案和改进解决方案。本节介绍生成初始解决方案和改进这些解决方案的步骤。
初始解决方案生成算法
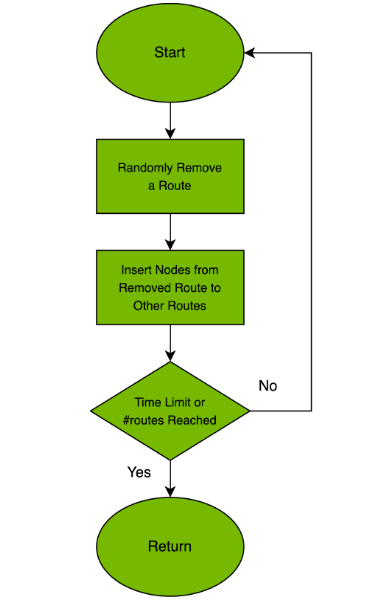
找到一组满足所有限制条件的有限机群来生成可行的初始解决方案本身就是一个 NP 难题。我们的团队已经改进并并行化了 引导式弹射搜索 (GES) 算法,用于向路由发出请求。
GES 的主要理念很简单。我们首先尝试将请求插入路由。如果无法插入该请求,我们会从路由中弹出一个或多个易于插入的请求,并将请求插入到已放松的路由。每个请求的惩罚分数 (p-score) 表示将该请求插入路由的难度。仅当被弹出请求的 p-score 的总和小于所考虑的请求时,算法才会插入请求。
每次无法将请求插入路由 (即使是弹射) 时,我们都会增加该请求的 p 分数,然后重试。我们会将所有未服务的请求保留在弹射池中,然后算法运行,直到弹射池变为空。换言之,它一直运行,直到所有请求都得到服务。
此算法的主要缺点是循环 (返回到解决方案中的前一组节点)、在弹射节点数量较多时查找弹射组合的速度较慢,以及仅考虑弱的随机微扰解决方案。我们已经消除了这些倒退,这使我们能够生成比当前先进方法更少路线数量的解决方案。
在探讨弹射算法之前,了解可行性检查和解决方案评估使用时间扭曲方法至关重要。这种方法显著缩短了计算时间,但也增加了并行化的难度,因为需要遵守搜索任意数量的弹射的字典顺序。
找到要弹出的请求以及在何处插入所考虑的请求是一个计算成本高昂的问题:它相对于弹出请求的数量呈指数级增长,并且需要检查所有路由中的所有插入位置。我们的实验表明,少量弹出会导致算法的循环。
因此,我们提出了一种方法,该方法可在执行广泛搜索时并行弹出多达 10 个请求 (启发式) 和 5 个请求。我们通过从每个路由中弹出片段并在线程块中处理这些临时路由来并行处理弹出算法。然后,我们尝试并行将考虑的请求插入所有可能的位置。
深度搜索算法尝试对路由中所有请求的弹射进行所有可能的排列。我们为每个请求插入位置使用不同的线程块,并通过将词汇表顺序拆分为独立的子排列来并行执行词汇表搜索。
GES 算法循环直到我们用完时间限制或请求池为空。在每次迭代中,我们都会对解决方案进行微扰,以改进解决方案状态并打开解决方案中的差距,以便找到可行的插入。微扰是一种随机本地搜索,它随机重新定位并交换路线之间和路线内的节点。
在找到满足要求的最佳车辆数量后,我们将切换到负责最小化目标的改进阶段。默认情况下,这是总行驶距离,但可以在 cuOpt 中配置其他目标。
进化过程和局部搜索算法
改进阶段适用于多个解决方案,并使用进化策略对其进行改进。生成的解决方案放在一个群体中。为了达到足够多样化的初始解决方案,我们在生成过程中使用随机化。利用 GPU 架构,我们并行生成了许多不同的解决方案。多样化的群体经历了一个进化改进过程,将解决方案的最佳属性保留在新一代中。
在进化过程的单个步骤中,我们采用两个随机解决方案并应用交叉运算符。这将生成一个子代解决方案,该解决方案继承了父母双方的良好属性。可以对解决方案应用不同的交叉运算符,其中一些操作会使子代处于不完整状态。我们通过弹出重复节点、插入未路由节点或对其执行不可行的本地搜索来修复解决方案。
例如,基于顺序的交叉运算符根据节点在另一父解决方案中的出现顺序,对一个父解决方案的一条或多条路由中的节点进行重新排序。生成的子代会保留一个父解决方案的分组属性和另一个解决方案的排序属性。然而,这种运算符的结果可能是一个在时间和容量限制方面不可行的完整解决方案。cuOpt 包含多个在解决方案上随机执行的交叉运算符。
在这种情况下,分频后的局部搜索阶段在减少或消除不可行性或改善总目标或行驶距离方面发挥着关键作用。局部搜索的目标权重由需要优化的重要内容决定。提高不可行性权重有助于将解决方案返回到可行区域,而大多数问题通常都是如此。
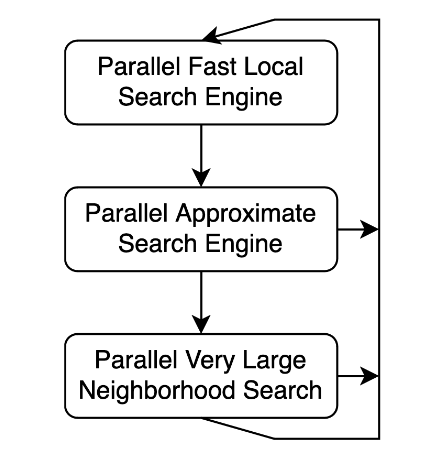
局部搜索为子代解决方案找到一个局部最小值,然后由后者参与进一步的进化步骤。拥有快速的局部搜索至关重要,因为这是决定在时间预算内可以进行多少次改进迭代的主要因素。我们使用快速、近似和大型邻域搜索算法来找到性能出色的局部最小值。我们没有像传统方法那样执行固定大小的邻域局部搜索,而是设计了一个“网络”,可以快速捕获简单的改进,并在达到停滞时捕获非常深入的运算符。
快速运算符可以快速探索小区域,而近似运算符可以在每次应用时评估不同的移动。这一点尤为重要,因为分频经常会使部分路线保持不变。大型运算符在移动链中移动请求,以路线之间的移动周期表示,正如在 用于查找图中负子集不相交周期的 GPU 并行算法 中所述。
循环运算符探索一个非常大的社区,无法使用简单的运算符进行探索。这仅仅是因为这些约束禁止这些简单的运算符通过搜索空间中的一些小山。此工作流允许经常使用快速运算符,而更频繁地使用计算成本较高的深度运算符。
GPU 并行化是通过将每个假设的路由映射到线程块来完成的。这允许使用共享内存来存储与路由相关的数据,这在搜索移动时是暂时的。临时路由或者是原始路由的副本,或者是弹出一个或多个请求的版本。线程块中的线程尝试将所有可能的请求从其他路由插入到临时路由中的所有位置。
在查找并记录所有移动后,我们通过求和每个路线对的插入/弹射成本增量来找到每个路线对的最佳移动。成本增量由目标权重计算,其中也包含不可行惩罚权重。如果多个此类移动在其修改的路线方面相互排除,则我们会执行多个此类移动。
cuOpt 基准测试
我们持续致力于提升 cuOpt 的性能和质量。为了评估质量,我们已针对研究最深入的基准,将求解器与最知名的解决方案进行了比较,包括针对 CVRPTW 的 Gehring&Homberger 以及针对 PDPTW 的 Li&Lim。在实际应用中,求解器能够以多快的速度找到所需的解决方案,对于企业来说至关重要。
评估标准和目标
- 精度的定义是,在目标方面,找到的解决方案与已知的最佳解决方案 (BKS) 之间的百分比差距。问题规范将第一个目标指定为车辆数量,将第二个目标指定为行驶距离。
- 解决方案测量时间表示达到 BKS 或期望目标结果的特定差距所需的时间。解决方案时间是实际用例中最重要的标准之一。在时间预算内达成高精度解决方案非常重要。组合优化算法需要大量时间。
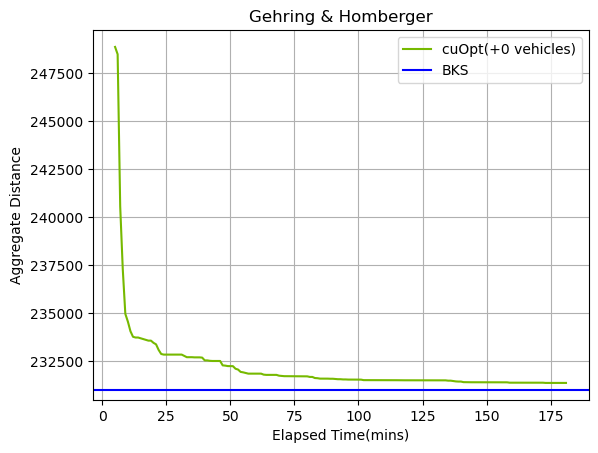
图 3 和图 4 显示了求解器在一组大型基准实例上的收行为。
我们从每个类别 (C1_10_1,C2_10_1,R1_10_1,R2_10_1,RC1_10_1,RC2_10_1) 中选择了一个实例,以显示求解器的整体行为,具体取决于 (集群、随机) 和 (长路径、短路径) 实例。我们将每分钟采样的聚合求和与聚合 BKS 进行比较。
开始时的急剧收会随着时间的推移逐渐接近 BKS 聚合。对于这些实例集,我们能够匹配 BKS 的车辆总数。cuOpt 求解器可以在 Gehring 和 Homberger 实例的几乎所有实例中找到 BKS 车辆数量。但是,与改进阶段相比,实际性能取决于生成初始解决方案所花费的时间。
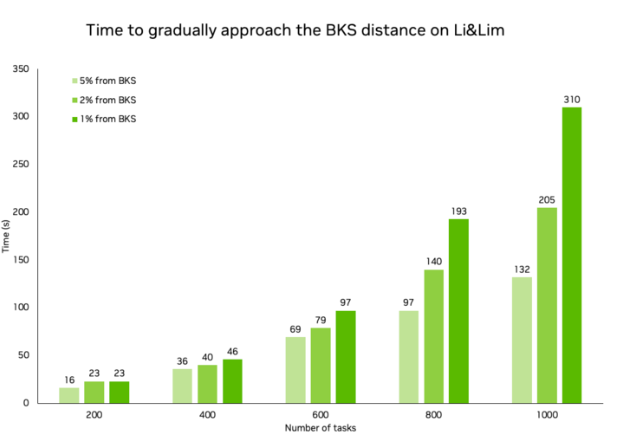
虽然求解器在较大的实例上能够快速收,但在较小的实例上,求解器的收速度却快了几个数量级。在下表中,我们展示了针对各种问题规模达到 BKS 所需的时间,同时实现了与 BKS 相同的车辆数量。
cuOpt 创造 23 项世界纪录
借助 GPU 加速启发式算法的新方法和先进的进化策略,cuOpt 打破了 Gehring&Homberger 基准测试中 15 个实例和 Li&Lim 基准测试中 8 个实例的记录。
现在, NVIDIA 保留了过去三年 CVRPTW 和 PDPTW 类别的所有记录。
在图 5 中,每个边缘都表示从一个任务到另一个任务的路径。绿线表示与之前记录相同的边缘。两个解决方案之间的蓝色和红色边缘不同。得益于进化策略,cuOpt 解决方案在可能解决方案的搜索空间中处于完全不同的位置,这意味着有许多不同的边缘。

Gehring&Homberger 与 BKS 的总体平均差距为 -0.0 息%的距离差距和 0.29%的车辆计数差距。Li&Lim 与 BKS 的总体平均差距为 1.2 息%的距离差距和 0.36%的车辆计数差距。基准测试在单个测试中运行了 200 分钟 NVIDIA H100 GPU。
结束语
NVIDIA cuOpt 利用 GPU 加速和 NVIDIA 技术(如 RAPIDS),与基于 CPU 的实现相比,我们在本地搜索操作中实现了 100 倍的加速。相比之下,基于 CPU 的求解器需要数小时才能找到类似的解决方案。
了解详情和 开始使用 NVIDIA cuOpt。您还可以通过 NVIDIA API 目录 和 NVIDIA LaunchPad 了解如何 cuOpt 可以帮助您的组织节省时间和资金。
加入我们参加 NVIDIA GTC 2024 会议,聆听 NVIDIA 优化 AI 工程经理 Alex Fender 的演讲,以优化 AI 领域的进展。此外,您还可以参加 NVIDIA 深度学习培训中心(DLI)的培训,了解如何使用我们的路线优化微服务提高效率并节省成本。