大语言模型(LLM)正在成为企业不可或缺的工具,用于改善他们的运营、客户互动和决策过程。然而,由于行业特定的术语、领域专业知识或独特的要求,现成的 LLM 往往无法满足企业的特定需求。
这就是自定义 LLM 发挥作用的地方。
企业需要自定义模型来根据其特定的用例和领域知识定制语言处理能力。自定义 LLM 使企业能够在特定行业或组织环境中更高效、更准确地生成和理解文本。
定制模型使企业能够创建符合其品牌声音的个性化解决方案,优化工作流程,提供更精确的见解,并提供增强的用户体验,最终推动市场竞争优势。
这篇文章介绍了各种模型定制技术以及何时使用它们。 NVIDIA NeMo 支持许多方法。
NVIDIA NeMo 是一个端到端的云原生框架,用于在任何地方构建、定制和部署生成人工智能模型。它包括训练和推理框架、护栏工具包、数据管理工具和预训练模型,为采用生成人工智能提供了一种简单、经济高效、快速的方法。
选择 LLM 定制技术
与下游任务准确性要求相比,您可以通过数据集大小要求和定制过程中的培训工作量之间的权衡来对技术进行分类。
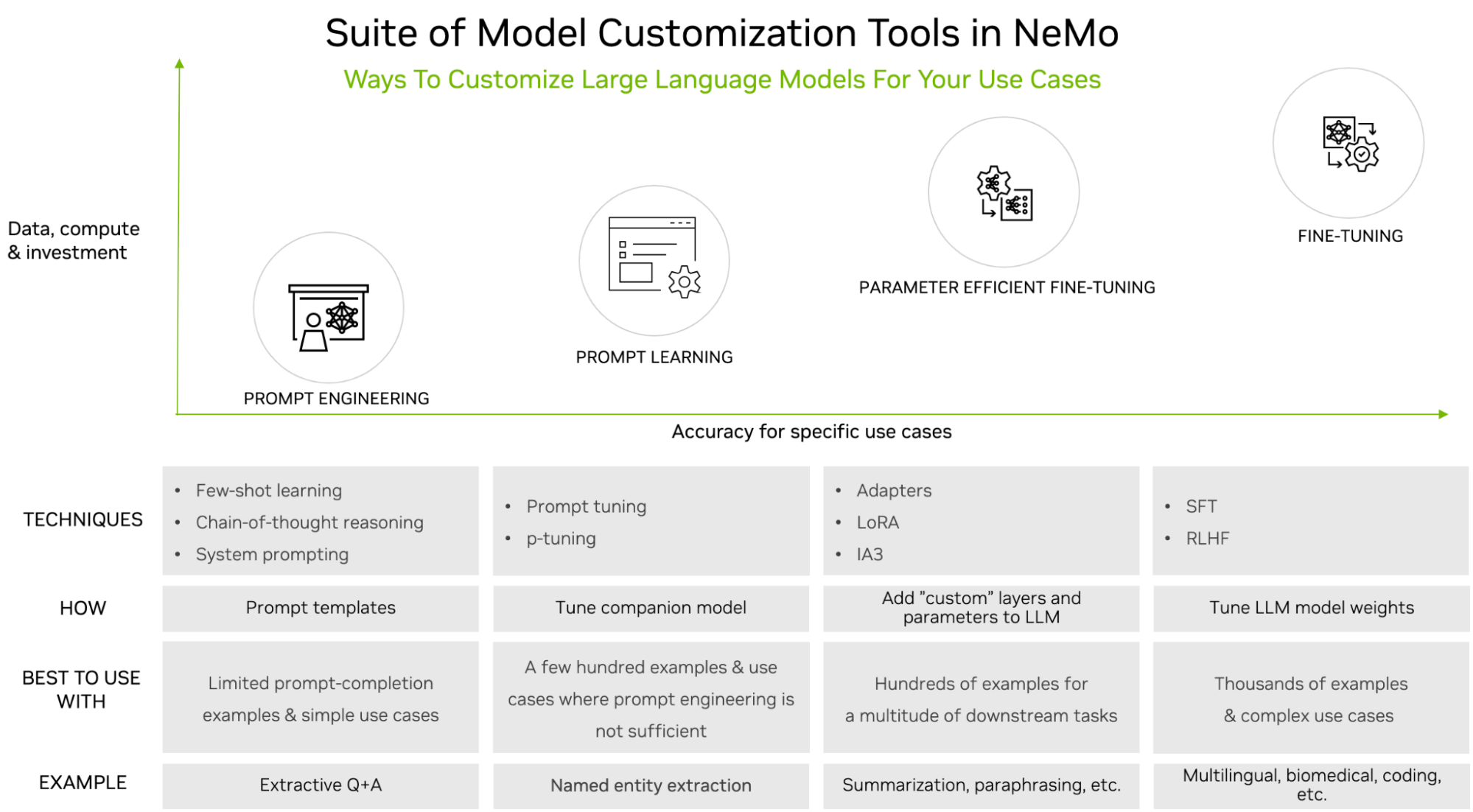
图 1 显示了以下流行的定制技术:
- 快速工程:操作发送给 LLM 的提示,但不会以任何方式更改 LLM 的参数。就数据和计算需求而言,它是轻量级的。
- 及时学习:通过使用提示和完成对,通过虚拟令牌向 LLM 传授特定于任务的知识。这一过程需要更多的数据和计算,但比快速工程提供了更好的准确性。
- 参数有效微调(PEFT):向现有的 LLM 架构引入少量参数或层,并使用特定于用例的数据进行训练。这提供了比即时工程和即时学习更高的准确性,但同时需要更多的训练数据和计算。
- 微调:涉及更新预先训练的 大语言模型 (LLMs) 的权重,这与前面概述的保持这些权重冻结的三种类型的定制技术不同。这意味着与这些其他技术相比,微调还需要最多的训练数据和计算。然而,它为特定的用例提供了最高的准确性,证明了成本和复杂性。
想要了解更多信息,请参阅 大语言模型简介:提示工程和 P-调优。
快速工程
即时工程包括在推理时通过展示和讲述示例进行定制。LLM 提供了示例提示和完井,在新提示前准备的详细说明,以生成所需的完成。模型的参数不变。
少镜头提示:这种方法需要在提示前准备一些示例提示和完成对,以便 LLM 学习如何为新的看不见的提示生成响应。虽然与其他定制技术相比,少镜头提示需要相对较少的数据量,并且不需要微调,但它确实增加了推理延迟。
思维链推理:正如人类将大问题分解为小问题并通过思维链有效地解决问题一样,思维链推理是一种高效的工程技术,可以帮助 LLM 提高在多步骤任务中的性能。这包括将问题分解为更简单的步骤,每个步骤都需要深思熟虑的推理。这种方法适用于逻辑、算术和演绎推理任务。
系统提示:这种方法包括在用户提示之外添加系统级提示,以向 大语言模型 (LLMs) 提供具体和详细的指示,使其按预期操作。系统提示可以被认为是 LLM 的输入,以生成其响应。系统提示的质量和特异性会对 LLM 响应的相关性和准确性产生重大影响。
及时学习
即时学习是一种有效的定制方法,可以在许多下游任务中使用预训练的 LLM,而无需调整预训练模型的全套参数。它包括两种具有细微差异的变体,称为 p 调谐和提示调谐;这两种方法统称为即时学习。
即时学习可以在 LLM 中添加新任务,而不会覆盖或中断模型已经预训练过的先前任务。由于原始模型参数被冻结且从未更改,因此快速学习也避免了微调模型时经常遇到的灾难性遗忘问题。灾难性遗忘当 LLM 在微调过程中以 LLM 预训练期间获得的基础知识为代价学习新行为时,就会发生这种情况。
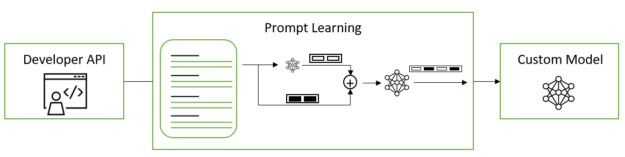
提示调整和 p 调整使用虚拟提示嵌入,而不是以手动或自动方式选择离散文本提示,您可以通过梯度下降进行优化。这些虚拟令牌嵌入的存在与构成模型词汇表的离散、硬或真实令牌形成了鲜明对比。虚拟令牌是维度等于每个真实令牌嵌入的维度的纯 1D 向量。在训练和推理中,根据模型配置中提供的模板,在离散的令牌嵌入之间插入连续的令牌嵌入。
提示调整:对于预训练的 LLM,软提示嵌入被初始化为大小为 total_virtual_tokens 的 2D 矩阵 Xhidden_size。每个需要快速调整的任务都有其自己的相关 2D 嵌入矩阵。在训练或推理过程中,任务不共享任何参数。 NeMo 框架的即时调优实现基于The Power of Scale for Parameter-Efficient Prompt Tuning。
P-调谐:在 LSTM 或 MLP 模型中,prompt_encoder被用于预测虚拟令牌嵌入。在 P-调谐开始时,prompt_encoder的参数被随机初始化。所有基本的 LLM 参数都被冻结,只有prompt_encoder在每个训练步骤中更新权重。P-调谐完成后,从prompt_encoder自动移动到prompt_table,其中存储了所有 P-调谐和提示调谐的软提示。prompt_encoder然后从模型中删除。这使您能够保留以前的 P-调谐软提示,同时仍然可以在将来添加新的 P-调谐或提示调谐软提示。
prompt_table 使用任务名称作为关键字来查找指定任务的正确虚拟令牌。 NeMo 框架的 p 调谐实现基于 GPT Understands, Too。
参数有效微调
参数有效微调(PEFT)技术通过巧妙的优化,选择性地向原始 LLM 架构添加和更新少数参数或层。使用 PEFT,可以针对特定用例训练模型参数。在使用领域和任务特定数据集的 PEFT 期间,预训练的 LLM 权重保持冻结,并且更新的参数明显较少。这使得 LLM 能够在经过训练的任务中达到高精度。
对于微调预训练的语言模型,有几种流行的参数有效的替代方案。与即时学习不同,这些方法不会在输入中插入虚拟提示。相反,他们在 transformer 体系结构中引入了可训练的层,用于特定任务的学习。这有助于在下游任务上获得强大的性能,同时与微调相比,将可训练参数的数量减少了几个数量级(参数减少了 10000 倍)。
- 适应性学习
- 通过抑制和放大内激活(IA3)注入适配器
- 低秩自适应(LoRA)
适配器学习:在核心 transformer 架构的层之间引入了小型前馈层。只有这些层(适配器)在微调时被训练用于特定的下游任务。适配器层通常使用向下投影来投影输入 

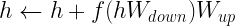
适配器模块通常进行初始化,以使适配器的初始输出始终为 ze ROS,以防止添加此类模块导致原始模型性能下降。NeMo 框架的适配器实现基于 Parameter-Efficient Transfer Learning for NLP。
IA3:与适配器相比,IA3 添加的参数更少。适配器只需使用学习向量来缩放 transformer 层中的隐藏表示。这些缩放参数可以针对特定的下游任务进行训练。学习的矢量 lk,lv 和 lff,分别用于重新缩放注意力机制中的键和值以及位置前馈网络中的内部激活。这项技术还使得混合任务批次成为可能,因为批次中的每个激活序列都可以单独且廉价地乘以其相关的学习任务向量。NeMo 框架的 IA3 实现基于 Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning。
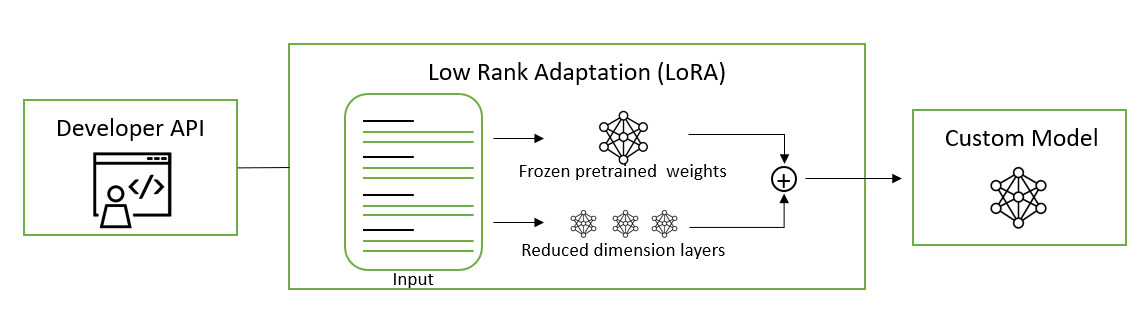
LoRA:这是一种将可训练的低秩矩阵注入到 transformer 层以近似权重更新的方法。LoRA 不是更新完整的预训练权重矩阵 W,而是更新其低秩分解。与微调相比,这将可训练参数的数量减少了 10000 倍,并将 GPU 内存需求减少了 3 倍。这种更新应用于多头注意力子层中的查询和值投影权重矩阵。将更新应用于低秩分解而不是整个矩阵已被证明在模型质量上与微调不相上下或更好,从而实现更高的训练吞吐量,并且没有额外的推理延迟。
NeMo 框架的 LoRA 实现基于 Low-Rank Adaptation of Large Language Models。要了解如何将 LoRa 模型应用于提取 QA 任务的更多信息,请参阅 LoRA 教程 笔记本。
微调
当数据和计算资源没有硬性约束时,监督微调(SFT)和人反馈强化学习(RLHF)等定制技术是 PEFT 和即时工程的绝佳替代方法。与其他定制方法相比,微调可以帮助在一系列用例中实现最佳精度。
监督微调:SFT 是一种对输入和输出的标记数据上的所有模型参数进行微调的过程,它教导模型领域特定的术语以及如何遵循用户指定的指令。这通常在模型预训练之后完成。与预训练阶段相比,使用预训练模型可以带来许多好处,包括使用最先进的模型而不必从头开始训练,降低计算成本,以及减少数据收集需求。SFT 的一种形式被称为指令调优,因为它涉及在通过指令描述的数据集集合上微调语言模型。
带有指令的 SFT 利用了 NLP 任务可以通过自然语言指令描述的直觉,例如“将下面的文章总结成三句话”或“用西班牙语写一封关于即将到来的学校节日的电子邮件”。这种方法成功地结合了微调和提示范式的优势,以提高 LLM 在推理时的零样本性能。
指令调整过程涉及在通过以不同比例混合的自然语言指令表达的几个 NLP 数据集的混合物上对预训练的模型执行微调。在推理时,对看不见的任务评估微调模型,并且已知该过程显著提高了看不见任务的零样本性能。SFT 也是使用强化学习提高 LLM 能力过程中的一个重要中间步骤,我们将在下面进行描述。
利用人类反馈的强化学习:人类反馈强化学习(RLHF)是一种定制技术,使得 LLM 能够更好地与人类价值观和偏好保持一致。它使用强化学习使模型能够根据收到的反馈调整其行为。这涉及一个三阶段的微调过程,使用人类偏好作为损失函数。如前一节所述,用指令微调的 SFT 模型被认为是 RLHF 技术的第一阶段。
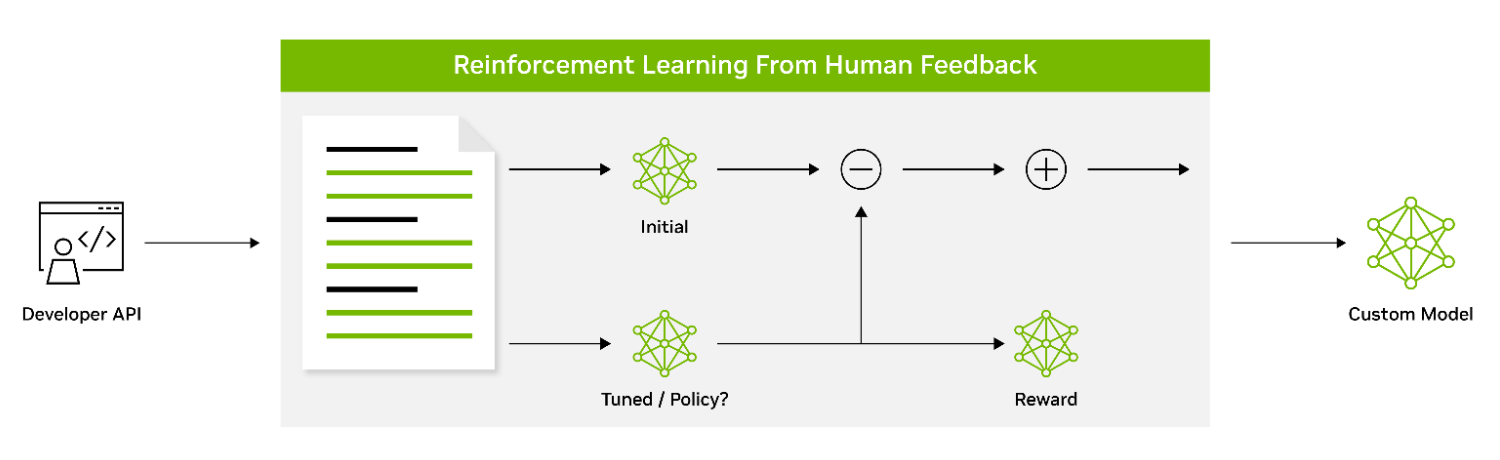
在 RLHF 的第 2 阶段中,SFT 模型被训练为奖励模型(RM)。一个由提示和多个反应组成的数据集被用于训练 RM 来预测人类偏好。
在训练 RM 之后,RLHF 的第 3 阶段侧重于使用具有近端策略优化(PPO)算法的强化学习来针对 RM 微调初始策略模型。迭代执行的 RLHF 的这三个阶段使 LLM 能够生成更符合人类偏好的输出,并且能够更有效地遵循指令。
虽然 RLHF 会产生强大的 LLM,但缺点是这种方法可能会被滥用和利用,产生不想要的或有害的内容。 NeMo 方法使用 PPO 价值网络作为评论家模型来引导 LLM 避免产生有害内容。研究界正在积极探索其他方法,以引导 LLM 采取适当的行为,并减少 LLM 虚构事实时产生的毒性或幻觉。
自定义 LLM
这篇文章介绍了各种模型定制技术以及何时使用它们。其中许多方法都由 NVIDIA NeMo 提供。
NeMo 为使用 3D 并行技术进行训练提供了加速的工作流程。它提供了多种定制技术的选择,并针对语言和图像应用程序的大规模模型的规模推断进行了优化,具有多 GPU 和多节点配置。
今天就下载 NeMo 框架,并在您喜欢的内部部署和云平台上定制预先训练的 LLM。