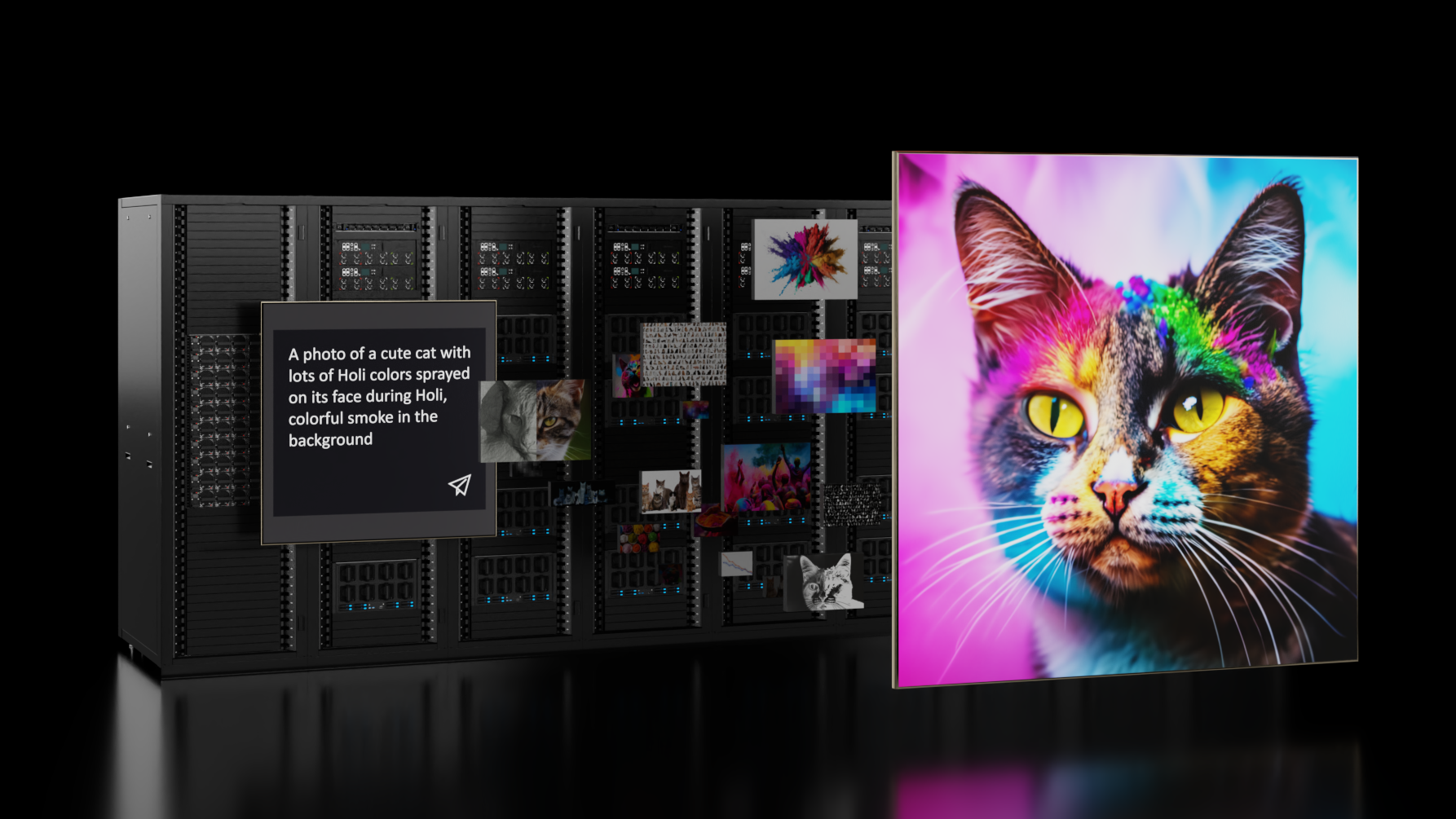
开发自定义 生成式人工智能 模型和应用程序是一段旅程,而不仅仅是一个目标。这个过程从选择一个预训练的模型开始,例如 大语言模型,出于探索的目的——开发人员通常希望针对他们的特定用例调整该模型。第一步通常需要使用可访问的计算基础设施,如 PC 或工作站。但随着训练工作的增加,开发人员可能需要扩展到数据中心或云中的额外计算基础设施。
这个过程可能会变得极其复杂和耗时,尤其是在尝试跨多个环境和平台进行协作和部署时。NVIDIA AI Workbench 通过提供用于管理数据、模型、资源和计算需求的单一平台,有助于简化流程。这使得开发人员能够无缝协作和部署,快速开发具有成本效益的可扩展生成人工智能模型。
什么是 NVIDIA AI Workbench ?
NVIDIA AI Workbench 是一个统一、易于使用的开发工具包,用于在 PC 或工作站上创建、测试和自定义预训练的 AI 模型。然后,用户可以将模型扩展到几乎任何数据中心、公共云或 NVIDIA DGX Cloud。它使各级开发人员能够快速轻松地生成和部署具有成本效益和可扩展性的人工智能模型。
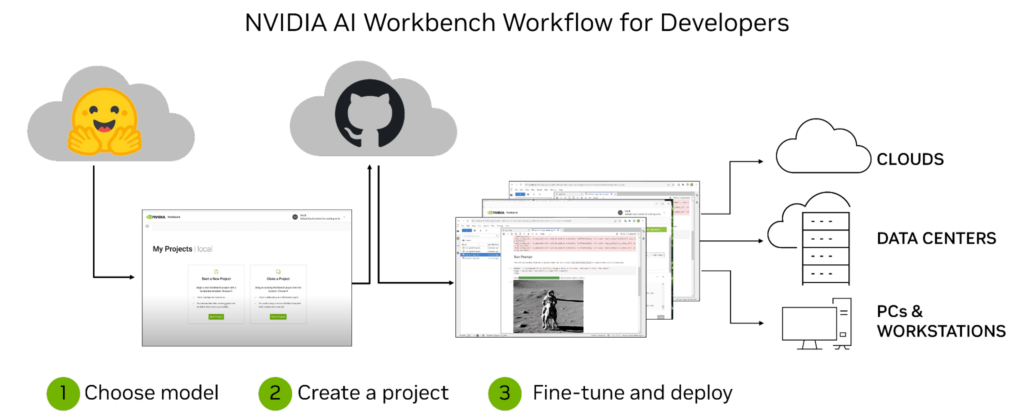
安装后,该平台为容器化开发环境提供管理和部署,以确保无论用户的机器如何,一切都能正常运行。AI Workbench 与以下平台集成:GitHub,Hugging Face 和 NVIDIA NGC,以及自托管注册表和 Git 服务器。
用户可以在 JupyterLab 和 VS Code 中自然开发,同时以高度的再现性和透明度管理各种机器的工作。拥有 NVIDIA RTX PC 或工作站的开发人员还可以在本地系统上启动、测试和微调企业级生成人工智能项目,并在扩展时访问数据中心和云计算资源。
企业可以将 AI Workbench 连接到 NVIDIA AI Enterprise,以加速采用生成人工智能,并为生产中的无缝集成铺平道路。当 AI Workbench 可用于早期访问时,您可以注册以便获得通知。
企业人工智能开发工作流挑战
虽然生成型人工智能模型为企业提供了难以置信的潜力,但开发过程可能复杂且耗时。
企业在开始开发定制生成人工智能之旅时面临的一些挑战包括以下方面。
技术专长:在研究生成式人工智能模型时,拥有正确的技术技能是关键。开发人员必须深入了解机器学习算法、数据处理技术、Python,以及类似的框架 TensorFlow。
数据访问和安全:敏感客户数据的激增意味着在此类项目中采取适当的安全措施至关重要。此外,企业必须考虑如何访问必要的数据集来训练其模型,这可能涉及处理来自多个来源的大量非结构化或半结构化数据。
移动工作流和应用程序:由于组件之间的依赖性,跨机器和环境的开发和部署可能很复杂。跟踪同一应用程序或工作流的不同版本可能很困难,尤其是在更分布式的环境中,如云计算平台Amazon AWS,Google Cloud Platform或Microsoft Azure。此外,管理凭据和机密信息对于保护跨机器和环境对资源的安全访问至关重要。
这些挑战强调了拥有像 NVIDIA AI Workbench 这样的综合平台的重要性,该平台可以简化整个生成人工智能开发过程。这使得管理数据、模型、计算资源、组件之间的依赖关系和版本变得更加容易。同时提供跨机器和环境的无缝协作和部署功能。
NVIDIA AI Workbench 的主要优势
开发生成式人工智能模型是一个复杂的过程, AI Workbench 简化了这一过程。凭借其管理数据、模型和计算资源的统一平台,所有技能水平的开发人员都可以快速轻松地创建和部署成本效益高、可扩展的人工智能模型。
使用 AI Workbench 的一些关键好处包括以下内容:
易于使用的开发平台: AI Workbench 提供了一个用于管理数据、模型和计算资源的单一平台,支持跨机器和环境的协作,从而简化了开发过程。
与人工智能开发工具和存储库集成: AI Workbench 集成了 GitHub 、 NVIDIA NGC 、 Hugging Face 、自托管注册表和 Git 服务器等服务。用户可以使用 JupyterLab 和 VS Code 等工具,在不同平台和基础设施上进行开发,具有高度的可重复性和透明度。
增强的协作:AI Workbench 采用了一种以项目为中心的架构,这是一个 Git 存储库,其中包含描述内容及其关系、配置和执行说明的元数据文件。位置或用户相关的数据由 AI Workbench 透明处理,并在运行时注入,避免这些信息被硬编码到项目中。这种项目结构有助于自动化版本控制、容器管理和处理机密信息的复杂任务,同时实现跨团队协作。
访问加速计算:AI Workbench 的部署采用客户端 – 服务器模型。Workbench 用户界面在本地系统上运行,并与 Workbench Service 进行远程通信。用户界面和服务都在用户的主要资源(如工作笔记本电脑)上本地运行。该服务可以安装在可通过 SSH 连接访问的远程计算机上。这使得团队能够在工作站中利用本地计算资源开始开发,并随着培训工作的增加而转移到数据中心或云资源。
NVIDIA AI 工作台投入使用
在 SIGGRAPH 2023 上,我们展示了 AI Workbench 在文本和图像工作流中生成人工智能定制的能力。
使用 Stable Diffusion XL 生成自定义图像
而在面部空间等服务上,拥抱 Gradio 应用程序提供了与以下模特的一键互动 StableDiffusion XL,这使得在本地运行这些模型和应用程序可能变得困难。
用户必须使用适当的 NVIDIA 软件设置本地环境,如 NVIDIA TensorRT 和 NVIDIA Triton 。然后,他们需要 HuggingFace 的模型、 GitHub 的代码和 NVIDIA NGC 的容器。最后,他们必须配置容器,处理 JupyterLab 等应用程序,并确保他们的 GPU 支持模型大小。
只有到那时,他们才准备好开始工作。即使对于专家来说,也有很多事情要做。
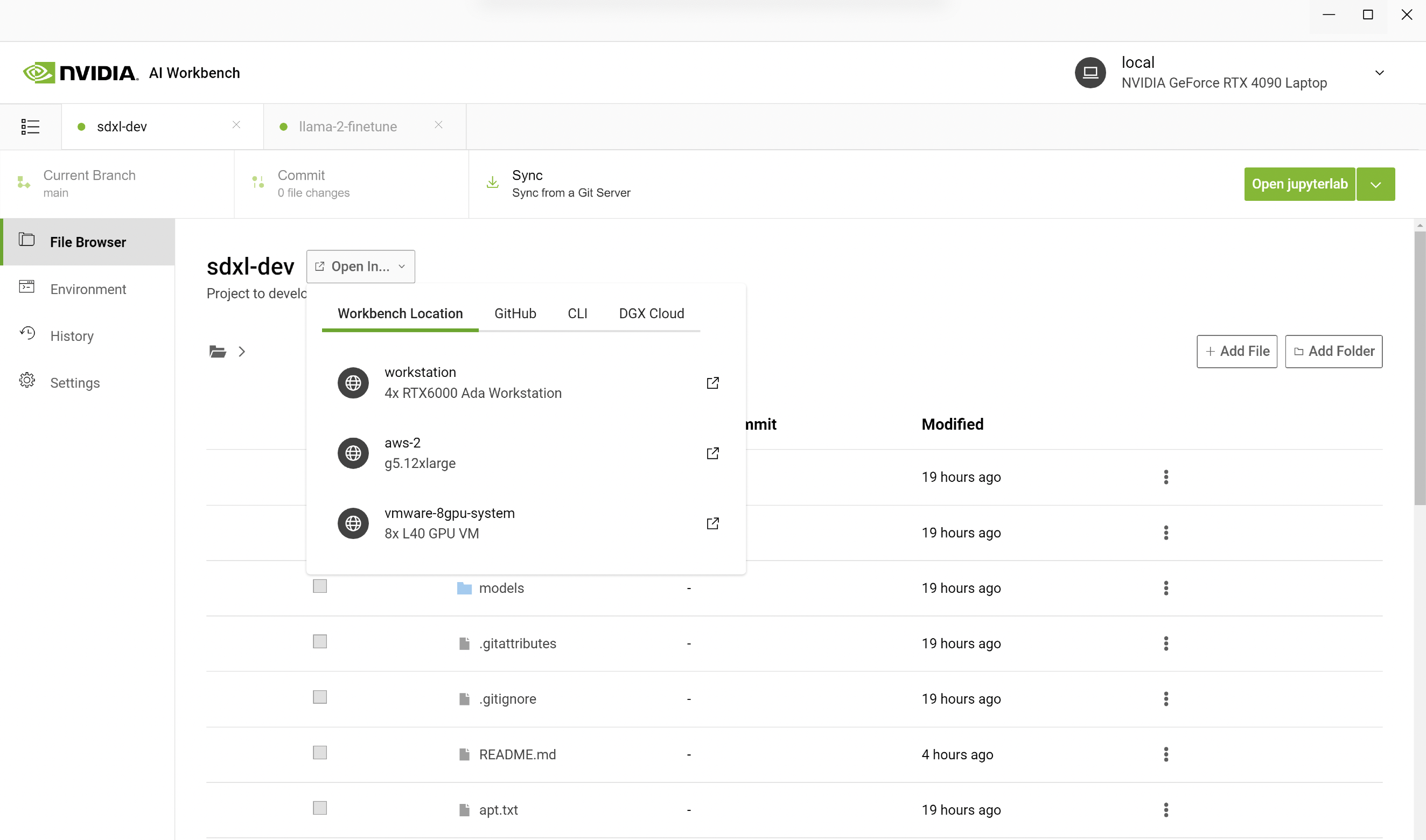
AI Workbench 使通过从 GitHub 克隆 Workbench 项目来完成整个过程。以下示例概述了我们的团队在创建 Toy Jensen 图像时所采取的步骤。
首先,我们在 PC 上打开 AI Workbench,然后使用 URL 克隆一个 repo。我们选择在配备更多 GPU 的远程工作站上运行 Jupyter Notebook,而不是在本地运行。在 AI Workbench 中,您可以选择您的工作站并打开 Jupyter 笔记本。
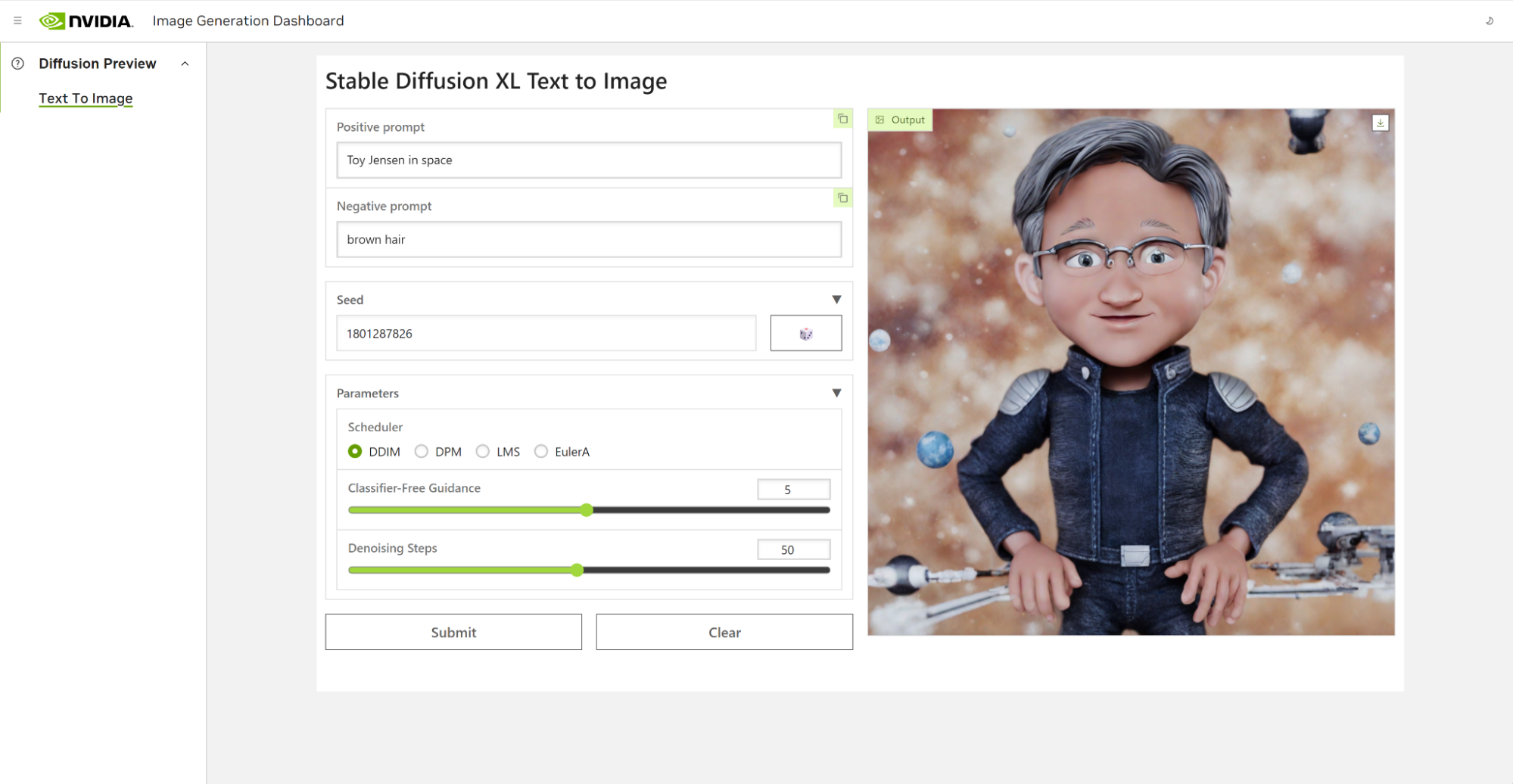
在 Jupyter Notebook 中,我们从 Hugging Face 加载了预训练的 Stable Diffusion XL 模型,并要求它生成一张“ Toy Jensen In space ”的图像。然而,根据输出的图像,模型不知道 Toy Jenson 是谁。
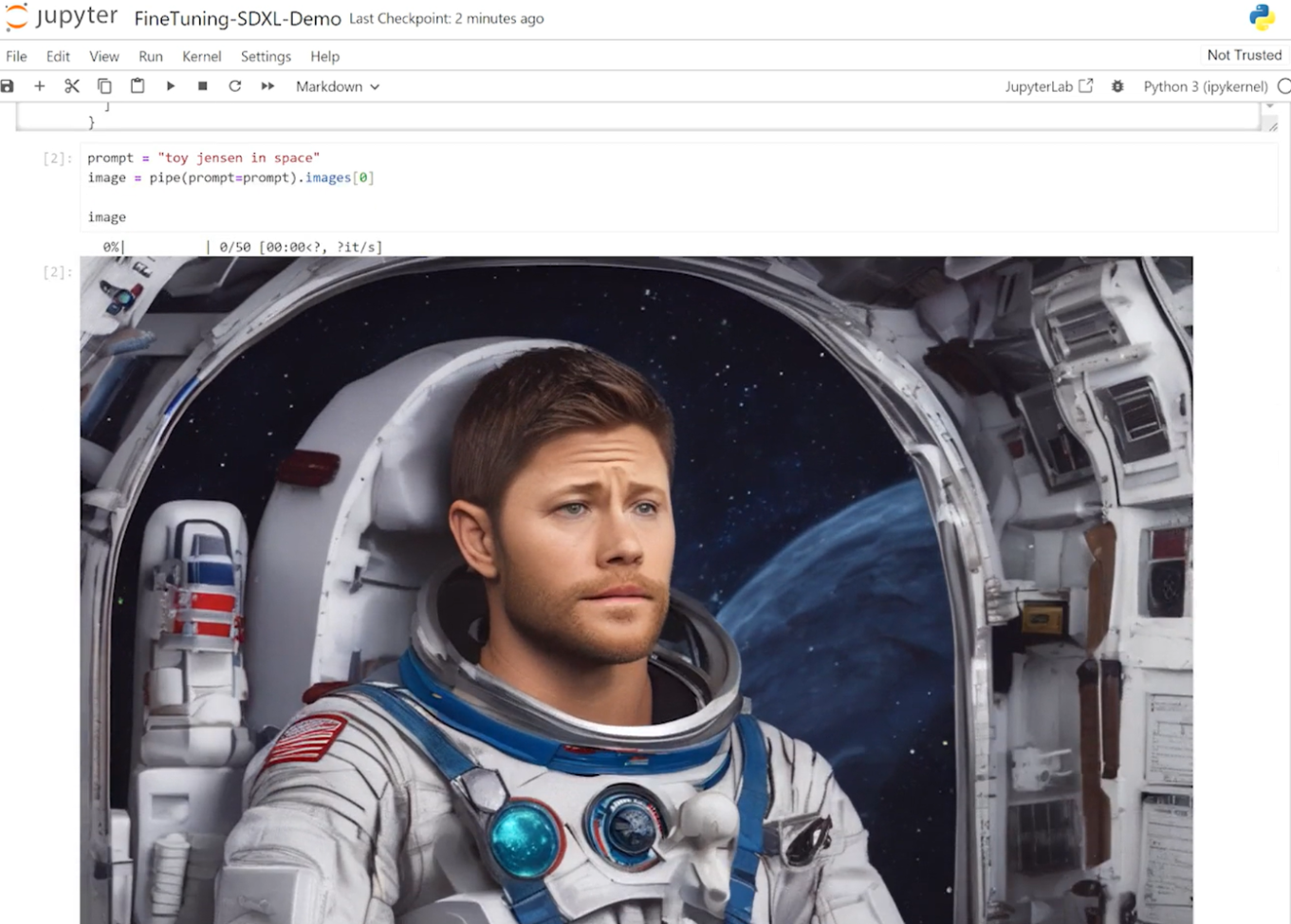
使用 DreamBooth 对模型进行微调,使我们能够根据感兴趣的特定主题对其进行个性化设置。在 Toy Jensen 的案例中,我们使用了 8 张 Toy Jenson 的照片来微调模型,并获得了良好的效果。现在,我们准备使用用户界面重新运行推理。该模型现在知道 Toy Jensen 是什么样子的,并且可以生成更好的图片,如图 4 所示。
为医学推理微调 Llama 2
较大的模型如Llama 2 70B需要更多的加速计算能力来进行微调和推理。在这个演示中,我们需要在数据中心配置 GPU,以便能够自定义模型。
通常,设置环境、连接服务、下载资源、配置容器等工作都是在远程资源上完成的。使用 AI Workbench,我们只需要从 GitHub 克隆一个项目,然后点击 启动 JupyterLab。
这个演示的目标是使用 Llama-2 模型为医疗用例构建一个专门的聊天机器人。开箱即用, Llama-2 模型对有关研究论文的医学问题反应不佳,因此我们必须定制该模型。
从笔记本电脑开始,我们连接到在数据中心或云中运行的八个 NVIDIA L40 GPU 。本地项目迁移到远程计算机使用 AI Workbench 。
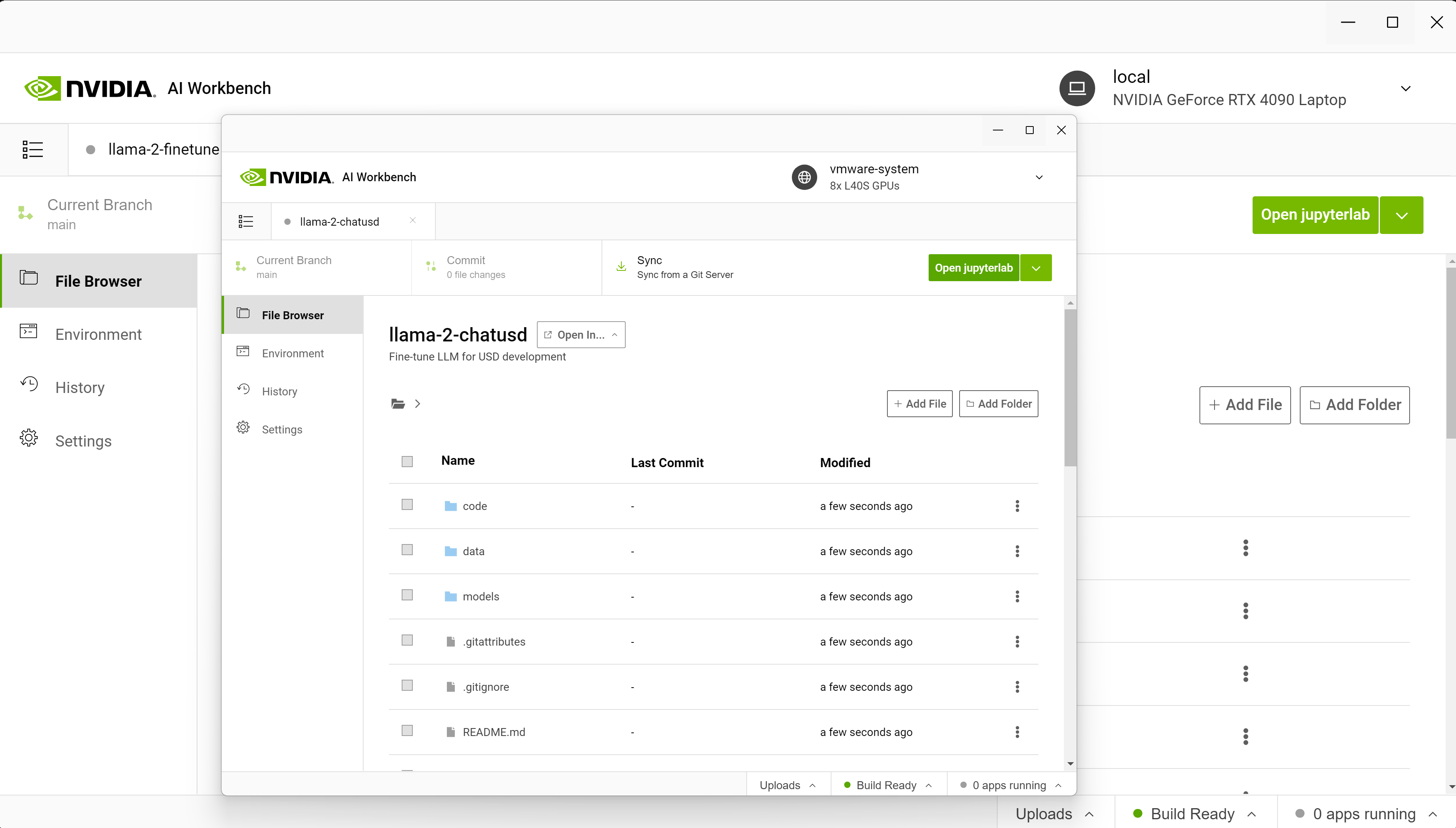
从 AI Workbench 启动了 Jupyter 环境,其中包括 P 调优笔记本,我们在其中加载预训练的 Llama-2 模型。
接下来,我们使用 NeMo 将其与开源 PubMedQA 数据集进行 P 调优。然后,我们打开用户界面再次运行推理,现在我们的模型根据给定的医学背景更准确地回答了关于以前未知疾病的问题。
在本例中,我们提供了以下提示来指导调优模型如何响应。
| 目标:确定早期超声图预测孪生 A 出生时表现的能力。 方法:对 7 个胎龄间隔的双胎 A 表现的声像图记录进行审查,并对分娩时双胎 A 的住院医疗记录进行审查。 结果:妊娠 28 周后,超声检测双胎 A 的头位对分娩时头位持续存在的阳性预测值达到 95% 。妊娠 32 周后,通过超声检查确定的分娩时非头痛表现的阳性预测值> 90% 。 问题:孕晚期超声能预测分娩时第一对孪生的表现吗? |
p 调谐模型能够利用从 PubMedQA 数据集学习到的信息正确响应提示。
| 答案:是的,孕晚期超声可以高度准确地预测分娩时第一对孪生的表现。根据您提供的研究,在妊娠 28 周后,通过超声确定的双胎 A 的头部出现对分娩时头部出现持续性的阳性预测价值达到 95% 。 同样,妊娠 32 周后,通过超声检查确定的分娩时非头部表现的阳性预测值> 90% 。 这些发现表明,孕晚期的超声波可以可靠地预测第一对孪生出生时的表现。然而,需要注意的是,超声波并不总是 100% 准确,胎动和定位等其他因素可能会影响预测的准确性。 |
有了 AI Workbench ,用户可以快速创建或克隆现有的生成型 AI 项目。开发人员可以从早期在本地机器上进行探索,一直到在工作站上进行模型调整,并在云和数据中心中投入可扩展资源进行大规模培训。
使用 NVIDIA AI Workbench 实现生成 AI 的经济高效可扩展性
随着人工智能模型变得越来越复杂和计算密集,开发人员必须拥有成本效益高的工具,使他们能够快速高效地扩展。 AI Workbench 提供了一个用于管理数据、模型和计算资源的单一平台,实现跨机器和环境的无缝协作和部署。有了这个平台,所有技能水平的开发人员都可以快速创建和部署成本效益高、可扩展的生成人工智能模型。
如果您想了解更多关于 AI Workbench 的信息,或者想注册以获取早期访问的通知,请访问 AI Workbench 页面。