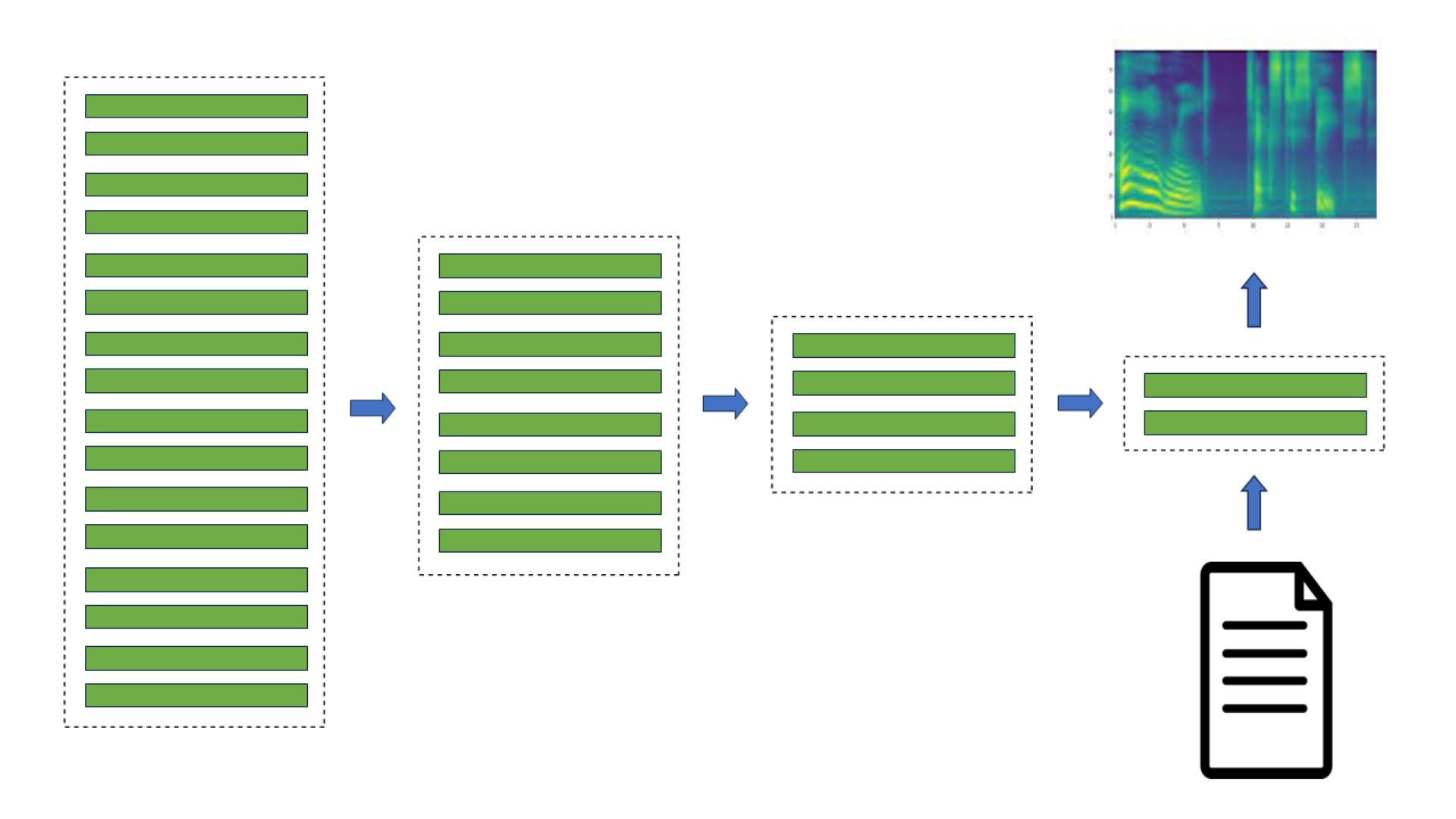
每年,作为课程的一部分,波兰华沙大学的学生都会在 NVIDIA 华沙办事处工程师的监督下,就深度学习和加速计算中的挑战性问题开展工作。我们展示了三位理学硕士学生——Alicja Ziarko、Paweł Pawlik 和 Michał 的TorToiSe,一个多阶段、基于扩散的文本到语音(TTS)模型。
Alicja、Paweł 和 Michał 首先了解了语音合成和扩散模型的最新进展。他们选择了 combination,这是 无分类器引导 和 渐进式蒸馏 的一部分,在计算机视觉中表现良好,并将其应用于语音合成。在不降低语音质量的情况下,他们将扩散延迟降低了 5 倍。小型感知语音测试证实了这一结果。值得注意的是,这种方法不需要从原始模型开始进行昂贵的训练。
为什么要加快基于扩散的 TTS?
自从WaveNet 在 2016 年出现以来,神经网络已经成为语音合成的主要模型。在一些简单的应用中,例如基于人工智能的语音助手的语音合成,合成的语音几乎无法与人类的语音区分。这种语音合成的速度可以比实时快几个数量级,例如使用NVIDIA NeMo AI 工具包。
然而,基于几秒钟的录音(几次拍摄)来实现高表现力或模仿声音仍然被认为是具有挑战性的。
去噪扩散概率模型 (DDPMs)作为一种生成技术出现,它能够基于输入文本生成高质量和高表现力的图像。DDPM 可以很容易地应用于 TTS,因为基于频率的声谱图可以像图像一样进行处理,从而图形化地表示语音信号。
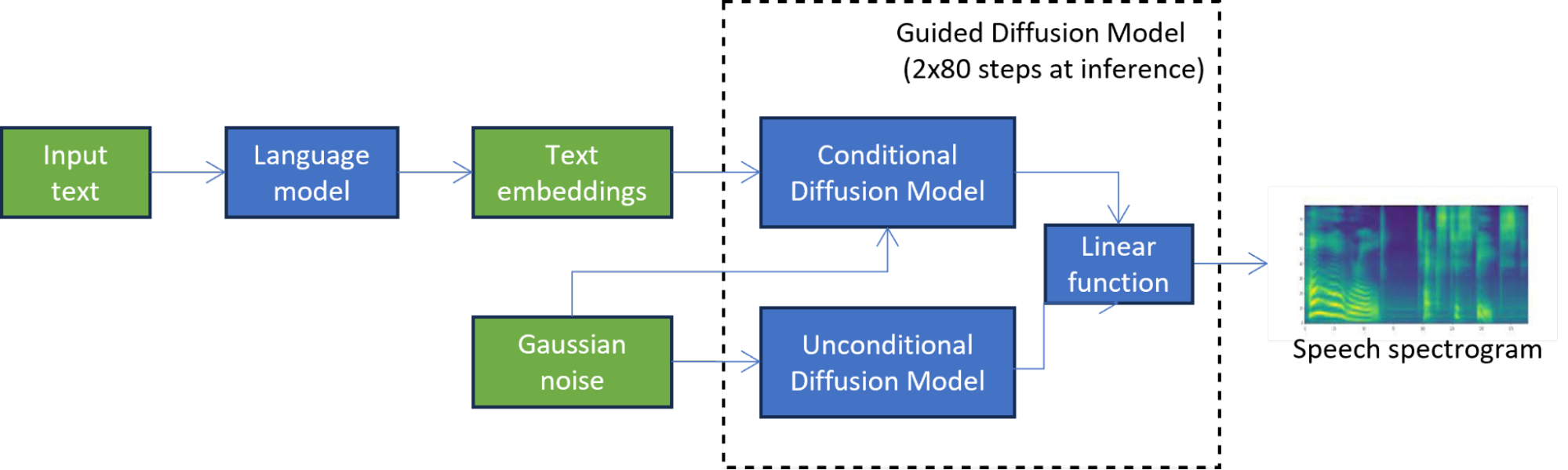
例如,在 TorToiSe 中,这是一个基于引导扩散的 TTS 模型,通过组合两个扩散模型的结果来生成谱图(图 1)。迭代扩散过程涉及数百个步骤来实现高质量的输出,与最先进的 TTS 方法相比,延迟显著增加,这严重限制了其应用。
在图 1 中,无条件扩散模型迭代地细化初始噪声,直到获得高质量的谱图。第二扩散模型进一步以语言模型产生的文本嵌入为条件。
加速扩散的方法
现有的基于扩散的 TTS 中的延迟减少技术可以分为无训练和基于训练的方法。
无训练方法不涉及通过反转扩散过程来训练用于生成图像的网络。相反,他们只专注于优化多步骤扩散过程。扩散过程可以看作是解决ODE/SDE方程,因此优化它的一种方法是创建一个更好的解算器DDPM,DDIM和DPM,这降低了扩散步骤的数量。并行采样方法,例如基于Picard iterations或Normalizing Flows,可以将扩散过程并行化,以受益于 GPU 上的并行计算。
基于训练的方法主要优化扩散过程中使用的网络。网络可以被剪枝,量化 或 稀疏化,然后进行微调以提高精度。或者,可以手动或自动更改其神经结构,使用NAS 知识提取技术从教师网络中提取学生网络,以减少扩散过程中的步骤数量。
基于扩散的 TTS 中的蒸馏
Alicja、Paweł 和 Michał 决定使用基于有前景的结果在计算机视觉中的方法,并且它在推断时能够将扩散模型的延迟减少 5 倍。他们成功地将渐进蒸馏应用于预训练的 TorToiSe 模型的扩散部分,克服了无法访问原始训练数据等问题。
他们的方法包括两个知识提炼阶段:
- 模拟引导扩散模型输出
- 培训另一个学生模型
在第一个知识提取阶段(图 2),对学生模型进行训练,以在每个扩散步骤模拟引导扩散模型的输出。该阶段通过将两个扩散模型组合为一个模型,将延迟减少一半。
为了解决无法访问原始训练数据的问题,将语言模型中的文本嵌入传递到原始教师模型中,以生成用于提取的合成数据。合成数据的使用也使蒸馏过程更加高效,因为在每个蒸馏步骤都不必调用整个 TTS 引导扩散管道。
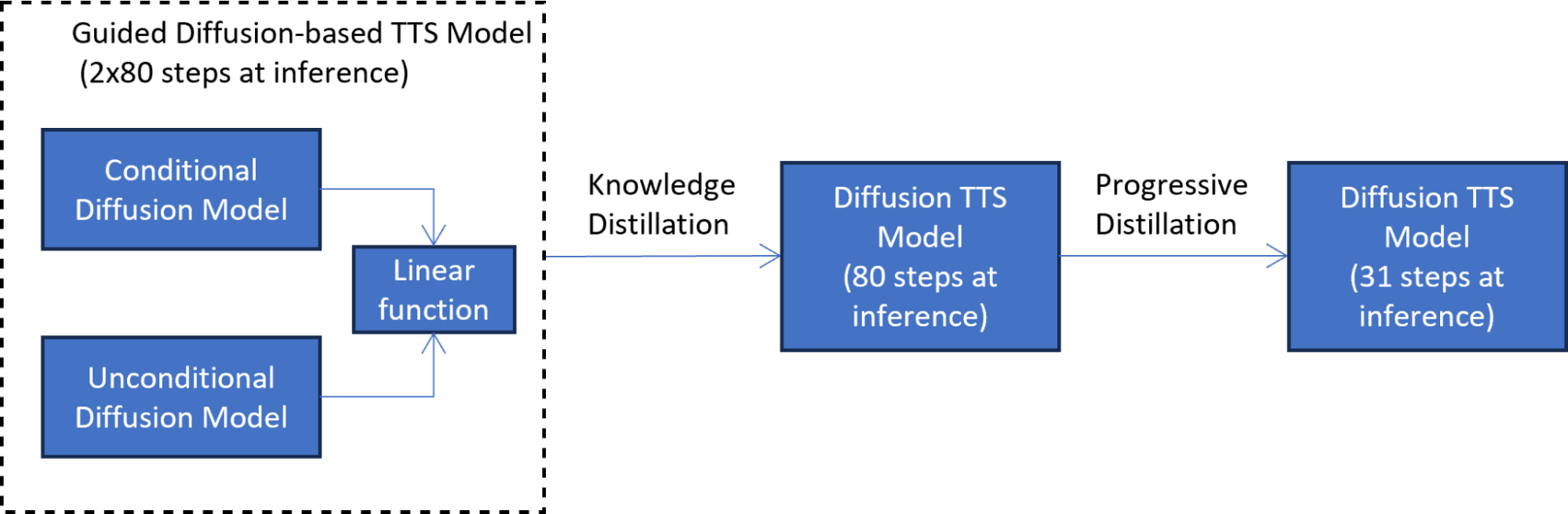
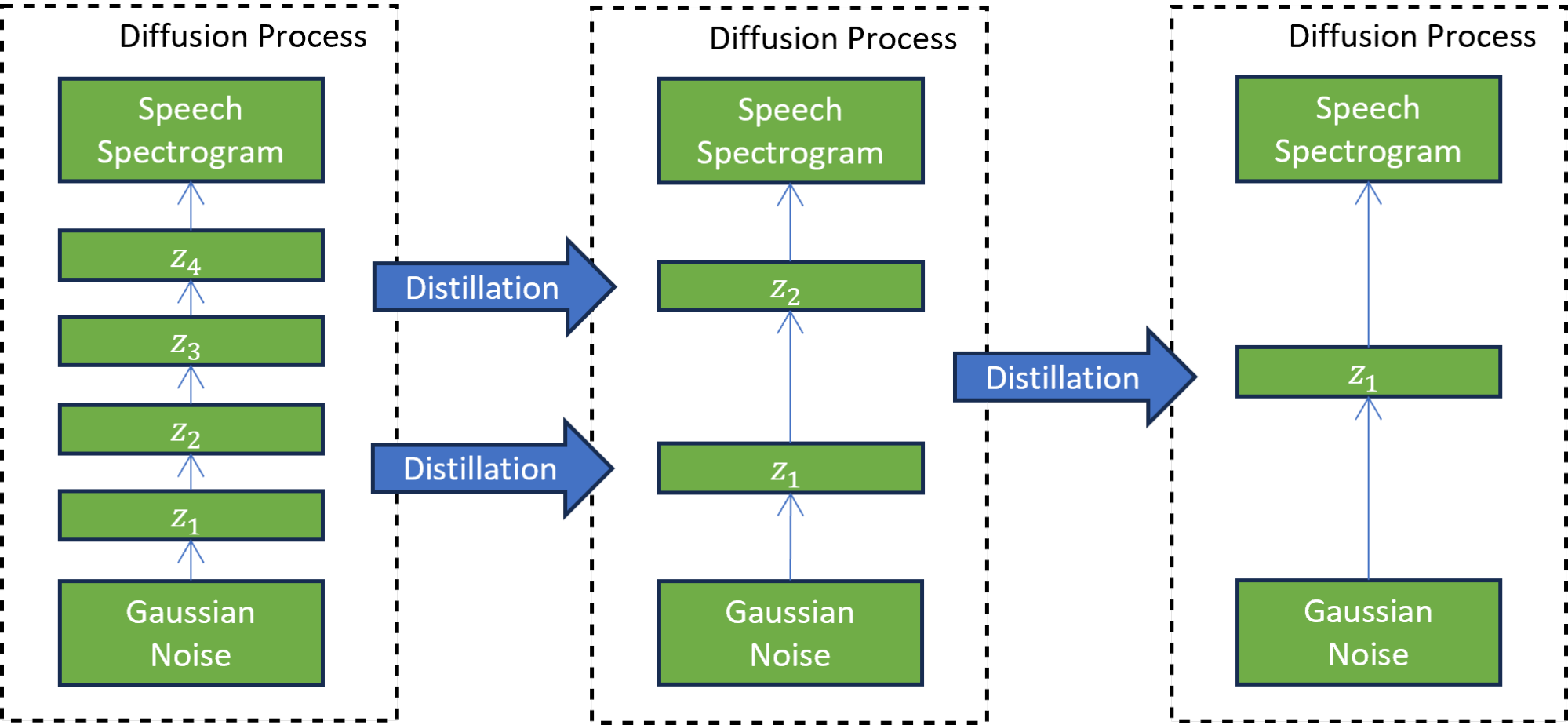
在第二个渐进升华阶段(图 3),新训练的学生模型充当教师来训练另一个学生模型。在这种技术中,学生模型被训练为模仿教师模型,同时将扩散步骤的数量减少两倍。这个过程重复多次,以进一步减少步骤数量,而每次都有一名新学生担任下一轮蒸馏的老师。
七次迭代的渐进蒸馏将推理步骤的数量减少了 7^2 次,从训练模型的 4000 个步骤减少到 31 个步骤。与引导扩散模型相比,这种减少导致了 5 倍的加速,不包括文本嵌入计算成本。
感知成对语音测试表明,提取的模型(在第二阶段之后)与基于引导提取的 TTS 模型产生的语音质量相匹配。
例如,收听表 1 中由基于渐进蒸馏的 TTS 模型生成的音频样本。样本与来自基于引导扩散的 TTS 模型的音频样本的质量相匹配。如果我们简单地将蒸馏步骤的数量减少到 31,而不是使用渐进蒸馏,则生成的语音的质量会显著恶化。
发言者 |
基于引导扩散的 TTS 模型 (2×80 扩散步骤) |
渐进蒸馏后基于扩散的 TTS (31 个扩散步骤) |
基于引导扩散的 TTS 模型 (初始减少到 31 个扩散步骤) |
|---|---|---|---|
| 女的 1 |
Audio | Audio | Audio |
| 女性 2 | Audio | Audio | Audio |
| 女性 3 | Audio | Audio | Audio |
| 男 1 | Audio | Audio | Audio |
结论
与学术界合作,帮助年轻学生塑造他们在科学和工程领域的未来,是 NVIDIA 的核心价值观之一。Alicja、Paweł和 Michał;的成功项目体现了 NVIDIA 驻波兰华沙办事处与当地大学的合作关系。
学生们设法解决了加快预先训练的、基于扩散的文本到语音(TTS)模型的挑战性问题。他们在基于扩散的 TTS 的复杂领域设计并实现了一个基于知识蒸馏的解决方案,实现了扩散过程的 5 倍加速。最值得注意的是,他们基于合成数据生成的独特解决方案适用于预训练的 TTS 模型,而无需访问原始训练数据。
我们鼓励您探索 NVIDIA Academic Programs 并尝试使用 NVIDIA NeMo Framework 来为生成人工智能的新时代创建完整的会话人工智能(TTS、ASR 或 NLP/LLM)解决方案。




