随着大语言模型 (LLM) 驱动更多能够执行自主操作、工具使用和推理的代理式系统,企业被其灵活性和低推理成本所吸引。这种自主性的增长会增加风险,导致目标不对中、提示注射、意外行为和减少人工监督,因此采用可靠的安全措施至关重要。
此外,零散的风险态势加上动态的监管转变会导致责任升级。信任因素会引入一些未知风险,例如幻觉、提示注入、数据泄露和冒犯性模型响应,而这些风险可能会破坏组织的安全、隐私、信任和合规性目标。这些因素共同阻碍了使用开放模型为企业 AI 智能体提供动力支持。
本文将介绍 NVIDIA AI 安全方案,该方案通过 NVIDIA 开放数据集、评估技术和后训练方案强化 AI 生命周期的每个阶段。在推理时,NVIDIA NeMo Guardrails 可帮助应对新出现的风险,例如绕过内容审核的对抗性提示、提示注入攻击和合规性违规。
这种整体方法使政策经理、首席信息官和首席信息官等风险负责人以及 AI 研究人员能够主动管理安全威胁、执行企业策略,并以负责任的方式自信扩展代理式 AI 应用。
为什么代理式工作流需要安全配方?
先进的开放权重模型并不总是与公司的安全策略保持一致,而且不断变化的环境带来的风险超过了内容过滤器和基准等传统保护措施的能力。由于缺乏持续的策略感知监控,这可能会使 AI 系统面临高级提示注入攻击。
代理式 AI 安全配方提供了一个全面的企业级框架,使组织能够构建、部署和运营可信且符合内部政策和外部监管需求的 AI 系统。
主要优势包括:
- 评估:能够根据生产模型和基础设施中定义的业务策略和风险值进行测试和衡量。
- 端到端 AI 安全软件堆栈:适用于企业 AI 系统的核心构建块支持在整个 AI 生命周期中监控和实施安全策略。
- 可信数据合规性:访问开放许可的安全训练数据集,构建透明可靠的 AI 系统。
- 先进的风险缓解:在关键维度提供系统安全性的技术,例如: 内容审核:解决内容安全问题,包括减少暴力、性或骚扰性内容。 安全性:通过提高系统对尝试提取有害信息的操作提示 (例如 Do Anything Now (DAN)) 的恢复能力,防止越狱和提示注入攻击。
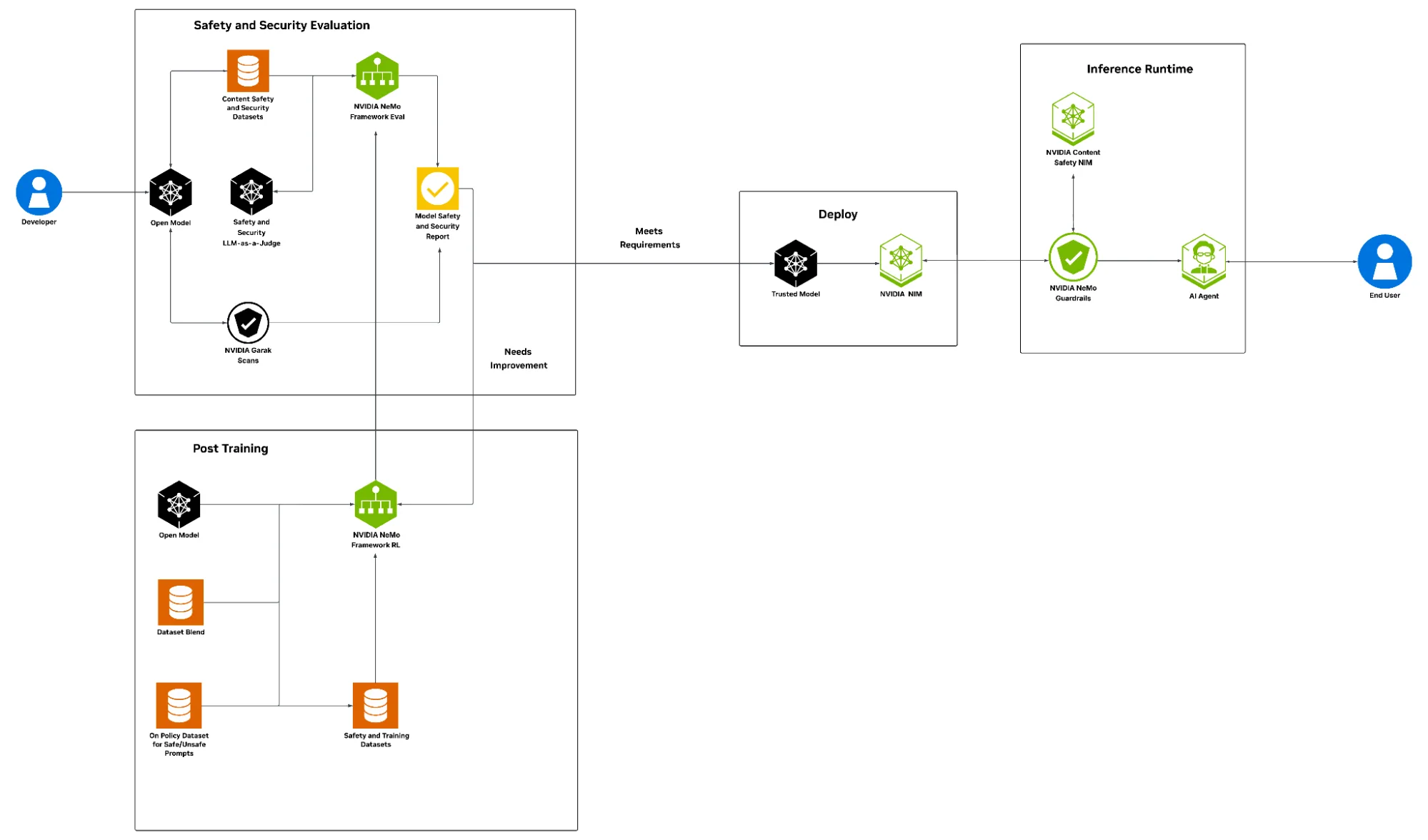
在构建、部署和运行中应用防御
在构建阶段,模型评估和对齐是确保模型输出符合企业特定用途、安全性、信任、用户隐私期望和监管合规性标准的关键步骤。NVIDIA 提供了一套评估工具,例如使用开放数据集和内容版主模型评估 NVIDIA NeMo 框架模型。
使用 Llama Nemotron Safety Guard v2 模型的 Nemotron 内容安全数据集和使用 AllenAI WildGuard 模型的 WildGuardMix 数据集严格筛选有害输出,增强内容完整性并与企业政策保持一致。此外,garak LLM 漏洞扫描器会针对产品安全漏洞进行调查,以确保在对抗性提示和越狱企图面前的鲁棒性,并测试系统的弹性。
NeMo 框架 RL 使开发者能够通过监督式微调 (SFT) 和强化学习 (RL) 应用先进的后训练技术。它还提供开放的许可数据集,用于构建透明、可靠的 AI 系统。用户准备策略数据集混合以确保安全,并将其用于后训练模型。
完成后训练后,生成对模型安全和安保报告的全面审查,确保其符合企业特定策略并符合所需的标准。在此阶段,重新评估特定任务的准确性也至关重要。在验证所有评估均符合业务和安全值后,该模型可被视为可信任部署。接下来,使用 LLM NIM 微服务大规模部署此可信模型,以跨多个环境进行推理。
在现实世界中,威胁不会在后训练时结束;始终存在剩余风险。通过 garak 评估和后训练获得的见解与 NeMo Guardrails 相结合,可在推理运行时提供持续、可编程的安全性和保护。
Llama 3.1 Nemoguard 8B Content Safety NIM 可防止偏差或有害输出,Llama 3.1 Nemoguard 8B Topic Control NIM 可确保交互始终位于经批准的业务或合规性域内,Nemoguard Jailbreak Detect NIM 有助于防御旨在绕过模型保护措施的恶意提示工程。
实现领先的模型安全性基准
行业领先的基准测试凸显了基准开放式权重模型与通过训练后安全配方增强的同一模型之间的安全性差距。
内容安全模型评估的完成方式是结合使用 Nemotron Content Safety Dataset v2 测试集的内容审核基准、Nemotron Safety Guard v2 评委模型,以及使用 WildGuardTest 数据集和 WildGuard 评委模型的外部社区基准。
通过使用安全数据集应用 NVIDIA AI 安全配方,产品安全性从基准开放权重模型的 88% 提高到 94%,在没有可测量的准确性下降的情况下,内容安全性提高了 6%。这是使用策略安全训练完成的,其中响应由目标模型或与相同预期行为保持一致的密切相关的模型生成。
产品安全性从基准开放权重模型的 56% 提高到 63%,安全性提高了 7%,没有可测量的准确性损失,防止对抗提示词、越狱企图和有害内容生成,使用 garak 来衡量弹性分数,评估为模型执行高于平均值的探针的百分比。
NVIDIA AI 安全配方可帮助企业组织自信地在从开发到部署的整个过程中运营开放模型,从而实现企业级代理式 AI 系统的安全保护和负责任的采用。领先的网络安全和 AI 安全公司正在将这些 NVIDIA AI 安全基础模组集成到其产品和解决方案中。
Active Fence 使企业能够通过实时护栏安全地部署智能体,确保更安全的生成式 AI 交互。
思科 AI Defense 与 NeMo 集成,使用算法红色团队评估模型漏洞,并为运行时应用提供补充性安全、安保和隐私护栏。
CrowdStrike Falcon Cloud Security 与 NeMo 训练生命周期配合使用,允许客户将从其持续的提示监控和运行时模型中的威胁情报数据中学习的内容整合到进一步的模型后训练中。
Trend Micro 正在与 NeMo 模型开发流程集成,以确保模型安全机制在企业环境中可靠、安全地扩展。


开始提高 AI 系统安全性
代理式 AI 的安全配方提供了一个结构化参考,旨在尽早评估和调整开放模型,从而提高代理式工作流程的安全性和合规性。该 recipe 可作为 Jupyter notebook 下载,也可通过 build.nvidia.com 上的 NVIDIA Brev 在云上部署可启动选项。
致谢
感谢所有为此博文做出贡献的人士,包括 Yoshi Suhara、Prasoon Varshney、Ameya Sunil Mahabaleshwarkar、Zijia Chen、Makesh Narasimhan Sreedhar、Aishwarya Padmakumar、Pinky Xu、Negar Habibi、Joey Conway、Christopher Parisien、Erick Galinkin、Akshay Hazare、Jie Lou、Vinita Sharma、Vinay Raman、Shaona Ghosh、Katherine Luna 和 Leon Derczynski。






