合成数据在训练部署在自主移动机器人(AMR)上的感知 AI 模型时起着关键作用。这一过程在制造业中变得越来越重要。如果想查看使用合成数据生成可检测仓库中托盘的预训练模型的示例,请参见利用 OpenUSD 和合成数据开发托盘检测模型。
这篇文章探讨了如何训练 AMR 使用合成数据检测仓库托盘搬运车。托盘搬运车通常用于仓库中提升和运输重型托盘。在拥挤的仓库中,AMR 检测并避免与托盘搬运车碰撞非常重要。
为了实现这一目标,我们需要在各种照明和遮挡条件下,使用大量多样的数据来训练人工智能模型。真实数据很少能够捕捉到所有潜在的场景。合成数据生成 (SDG),这是由 3D 模拟生成的注释数据,使开发人员能够克服数据缺口并引导模型训练过程。
这个用例将再次采用以数据为中心的方法,通过操纵数据,而不是更改模型参数来适应数据。该过程首先使用 NVIDIA Omniverse Replicator 在 NVIDIA Isaac Sim 中生成数据,然后使用这些合成数据来训练模型,使用的是 NVIDIA TAO 工具包。最后,我们将在真实数据上可视化模型的性能,并修改参数以生成更好的合成数据,从而达到所需的性能水平。
Omniverse Replicator 是 NVIDIA Omniverse 的一部分,这是一个计算平台,使个人和团队能够基于 通用场景描述(OpenUSD) 构建。Replicator 使开发人员能够构建自定义的合成数据生成管道,以生成用于引导计算机视觉模型训练的数据。
使用合成数据迭代以提高模型性能
以下部分解释了团队如何使用合成数据进行迭代,以提高我们的目标检测模型的真实世界性能。它使用与 Omniverse Replicator API 配合使用的 Python 脚本来完成各个步骤。
对于每次迭代,我们递增地更改模型中的各种参数,并生成新的训练数据集。然后根据实际数据验证了模型的性能。我们继续这个过程,直到我们能够缩小模拟到真实的差距。
改变对象或场景参数的过程被称为 领域随机化。您可以随机化许多参数,包括位置、颜色、纹理、背景、对象和场景的照明,这使您能够快速生成用于模型训练的新数据。
OpenUSD 是一个可扩展的框架、3D 场景描述和 NVIDIA Omniverse 的基础,可以轻松地对场景的不同参数进行实验。参数可以在各个层中进行修改和测试,用户可以在这些层的顶部创建非破坏性覆盖。
准备
要开始使用此示例,您需要一个已安装最新 NVIDIA Isaac Sim 版本的NVIDIA RTX GPU 。Isaac Sim 是一个可扩展的机器人模拟应用程序,利用 Omniverse Replicator 的核心功能生成合成数据。有关安装和配置的详细信息,请参阅 文档 部分。
当 Isaac Sim 启动并运行时,您可以从 NVIDIA-AI-IOT/synthetic_data_generation_training_workflow GitHub 上获取。
迭代 1:更改颜色和相机位置
在第一次迭代中,团队改变了托盘搬运车的颜色和姿势,以及相机的姿势。按照以下步骤在您自己的会话中复制此场景。
从加载阶段开始:
ENV_URL = "/Isaac/Environments/Simple_Warehouse/warehouse.usd"
open_stage(prefix_with_isaac_asset_server(ENV_URL))
然后将托盘搬运车和相机添加到场景中。托盘搬运车可以从 SimReady 资产 图书馆中获取。
PALLETJACKS = ["http://omniverse-content-production.s3-us-west-2.amazonaws.com/Assets/DigitalTwin/Assets/Warehouse/Equipment/Pallet_Trucks/Scale_A/PalletTruckScale_A01_PR_NVD_01.usd",
"http://omniverse-content-production.s3-us-west-2.amazonaws.com/Assets/DigitalTwin/Assets/Warehouse/Equipment/Pallet_Trucks/Heavy_Duty_A/HeavyDutyPalletTruck_A01_PR_NVD_01.usd",
"http://omniverse-content-production.s3-us-west-2.amazonaws.com/Assets/DigitalTwin/Assets/Warehouse/Equipment/Pallet_Trucks/Low_Profile_A/LowProfilePalletTruck_A01_PR_NVD_01.usd"]
cam = rep.create.camera(clipping_range=(0.1, 1000000))
SimReady 或模拟就绪资源是物理上精确的三维对象,包含精确的物理特性和行为。它们预装了模型训练所需的元数据和注释。
接下来,为托盘搬运车和相机添加域随机化:
with cam:
rep.modify.pose(position=rep.distribution.uniform((-9.2, -11.8, 0.4), (7.2, 15.8, 4)),look_at=(0, 0, 0))
# Get the Palletjack body mesh and modify its color
with rep.get.prims(path_pattern="SteerAxles"):
rep.randomizer.color(colors=rep.distribution.uniform((0, 0, 0), (1, 1, 1)))
# Randomize the pose of all the added palletjacks
with rep_palletjack_group:
rep.modify.pose(
position=rep.distribution.uniform((-6, -6, 0), (6, 12, 0)),
rotation=rep.distribution.uniform((0, 0, 0), (0, 0, 360)),
scale=rep.distribution.uniform((0.01, 0.01, 0.01), (0.01, 0.01, 0.01)))

最后,配置用于注释数据的编写器:
writer = rep.WriterRegistry.get("KittiWriter")
writer.initialize(output_dir=output_directory,
omit_semantic_type=True,)
请注意,此示例使用 Replicator 提供的 KittiWriter 以 KITTI 格式存储对象检测标签的注释。这将确保更容易与培训管道兼容。
后果
对于第一批合成数据,该团队使用了LOCO 数据集,这是一个用于物流场景理解的数据集,涵盖了检测物流特定对象以及可视化真实世界模型性能的问题。
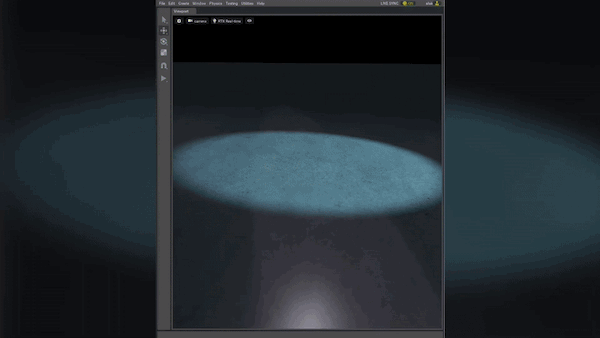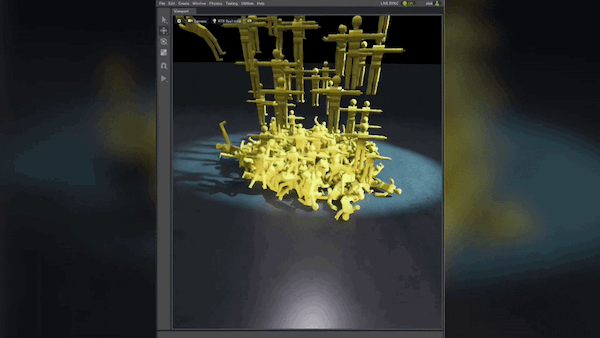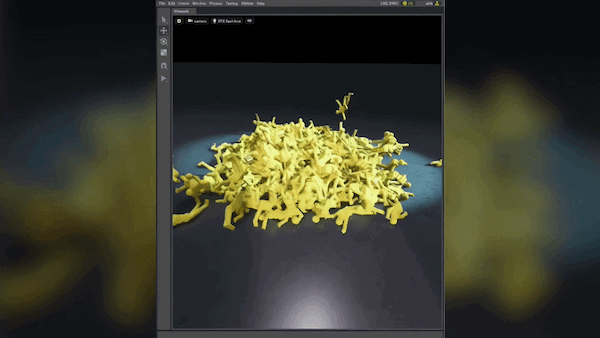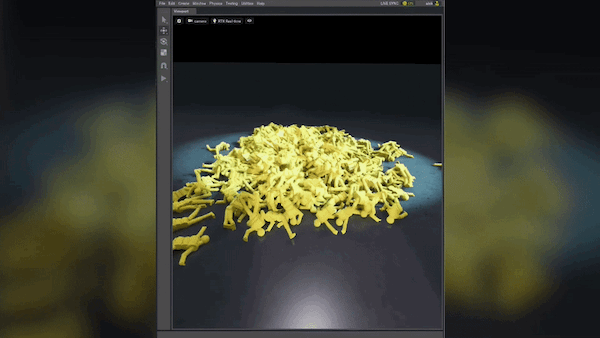
由此产生的图像显示,该模型仍在试图检测拥挤仓库中的托盘搬运车(图 2)。已经在托盘搬运车周围的对象周围创建了许多边界框。这个结果在某种程度上是意料之中的,因为这是第一次训练迭代。减少领域差距将是后续迭代的重点。

迭代 2:添加纹理和更改环境光
在这次迭代中,除了第一次迭代的托盘颜色和相机位置外,团队还随机化了纹理和环境照明。
激活纹理和照明的随机化:
# Randomize the lighting of the scene
with rep.get.prims(path_pattern="RectLight"):
rep.modify.attribute("color", rep.distribution.uniform((0, 0, 0), (1, 1, 1)))
rep.modify.attribute("intensity", rep.distribution.normal(100000.0, 600000.0))
rep.modify.visibility(rep.distribution.choice([True, False, False, False, False, False, False]))
# select floor material
random_mat_floor = rep.create.material_omnipbr(diffuse_texture=rep.distribution.choice(textures), roughness=rep.distribution.uniform(0, 1), metallic=rep.distribution.choice([0, 1]), emissive_texture=rep.distribution.choice(textures), emissive_intensity=rep.distribution.uniform(0, 1000),)
with rep.get.prims(path_pattern="SM_Floor"):
rep.randomizer.materials(random_mat_floor)
图 3 显示了生成的合成图像。请注意已添加到背景中的各种纹理,以及入射到对象上的不同类型的环境光。

后果
该迭代显示,通过添加纹理和照明随机化,误报数量有所减少。生成合成数据时的一个关键因素是确保生成的数据集中的数据具有良好的多样性。来自合成领域的类似或重复数据可能无助于改进真实世界模型性能。
若要提高数据集的多样性,请在场景中添加更多随机对象。这在第三次迭代中得到了解决,应该有助于提高模型的稳健性。

迭代 3:添加干扰物
此迭代将称为干扰物的附加对象引入到场景中。这些干扰因素为数据集增加了更多的多样性。此迭代还包括前两次迭代中显示的所有更改。
在场景中添加干扰因素:
DISTRACTORS_WAREHOUSE = ["/Isaac/Environments/Simple_Warehouse/Props/S_TrafficCone.usd",
"/Isaac/Environments/Simple_Warehouse/Props/S_WetFloorSign.usd",
"/Isaac/Environments/Simple_Warehouse/Props/SM_BarelPlastic_A_01.usd",
"/Isaac/Environments/Simple_Warehouse/Props/SM_BarelPlastic_A_02.usd",
"/Isaac/Environments/Simple_Warehouse/Props/SM_BarelPlastic_A_03.usd"]
# Modify the pose of all the distractors in the scene
with rep_distractor_group:
rep.modify.pose(
position=rep.distribution.uniform((-6, -6, 0), (6, 12, 0)),
rotation=rep.distribution.uniform((0, 0, 0), (0, 0, 360)),
scale=rep.distribution.uniform(1, 1.5))
请注意,此项目中使用的所有资产都可以使用默认的 Isaac Sim 安装。通过在 nucleus 服务器上指定路径来加载它们。

后果
图 6 显示了第三次迭代的结果。该模型可以准确地检测托盘搬运车,并且边界框较少。与第一次迭代相比,模型性能显著提高。

继续迭代
该团队使用 5000 张图像来训练每次迭代的模型。您可以通过生成更多的变体,同时增加合成数据的大小,继续迭代此工作流,以达到所需的准确性水平。
我们曾经使用 NVIDIA TAO 工具包 来训练具有 resnet18 骨干的 DetectNet_v2 模型用于这些实验。使用此模型并非工作流程的要求。您可以利用注释生成的数据来训练您选择的架构和框架的模型。
我们在实验中利用了 KITTI 编写器。但是,您可以使用 Omniverse Replicator 编写自己的自定义编写器,以正确的注释格式生成数据。这使您能够与培训工作流程无缝兼容。
您还可以在训练过程中尝试混合真实数据和合成数据。在获得令人满意的评估指标后,最终模型可以在 NVIDIA Jetson 上进行优化并部署在现实世界中。
使用 Omniverse Replicator 开发合成数据管道
使用 Omniverse Replicator,您可以构建自己的自定义合成数据生成管道或工具,以编程方式生成大量不同的合成数据集,从而引导您的模型并快速迭代。引入各种类型的随机化为数据集增加了必要的多样性,使模型能够在各种条件下识别感兴趣的对象。
要开始使用本文中的工作流程,请访问在 GitHub 上的 NVIDIA-AI-IOT/synthetic_data_generation_training_workflow 。要了解完整的工作流程,请观看 NVIDIA 的 Rishabh Chadha 和 Edge Impulse 的 Jenny Plunkett 展示如何使用 Omniverse Replicator 和合成数据来训练制造过程的对象检测模型的视频(视频 2)。
如果您想构建自己的自定义合成数据生成管道,可以免费下载 Omniverse 并按照说明开始使用 Omniverse Code 中的 Replicator。您也可以参加自定进度的在线课程,如 用于训练计算机视觉模型的合成数据生成 和 观看最新的 Omniverse Replicator 教程。
NVIDIA 最近发布了 Omniverse Replicator 1.10,为开发人员构建低代码 SDG 工作流提供了新的支持。想要了解更多信息,请参阅 NVIDIA Omniverse Replicator 1.10 中的低代码工作流促进合成数据生成。
NVIDIA Isaac ROS 2.0 和 NVIDIA Isaac Sim 2023.1 现在也提供了性能感知和高保真模拟的主要更新。要了解更多信息,请参阅 在 NVIDIA Isaac 平台上使用高级模拟和感知工具加速人工智能机器人。