
如今,人工智能驱动的应用程序正在实现更丰富的体验,这是由更大和更复杂的人工智能模型以及许多模型在管道中的应用所推动的。为了满足注入人工智能的应用程序日益增长的需求,人工智能平台不仅必须提供高性能,而且必须具有足够的通用性,以便在各种人工智能模型中提供这种性能。为了最大限度地提高基础设施利用率并优化 CapEx ,在同一基础设施上运行整个 AI 工作流的能力至关重要:从数据准备和模型培训到部署推理。
MLPerf 基准 已成为行业标准、同行评议的深度学习绩效衡量标准,涵盖人工智能培训、人工智能推理和 高性能计算 ( HPC )。 MLPerf 推断 2.1 是 MLPerf 推理基准套件的最新迭代,涵盖了广泛的常见 AI 用例,包括推荐、自然语言处理、语音识别、医学成像、图像分类和对象检测。
在这一轮中, NVIDIA 在最新 NVIDIA H100 Tensor Core GPU 的基础上首次提交了 MLPerf ,这是基于 NVIDIA Hopper 架构 的突破。
- H100 在所有数据中心测试中都创造了新的加速器记录,与 NVIDIA A100 Tensor Core GPU 相比,其推理性能提高了 4.5 倍。
- A100 在数据中心和边缘推断场景的全套 MLPerf 推断 2.1 测试中继续表现出优异的性能。
NVIDIA Jetson AGX Orin 是为边缘 AI 和机器人应用而构建的,在上一轮 MLPerf 推断中首次亮相后,每瓦特性能也提高了 50% ,并运行了所有边缘工作负载和场景。
实现这些性能结果需要深入的软件和硬件协同优化。在本文中,我们将讨论结果,然后深入探讨一些关键的软件优化。
NVIDIA H100 Tensor 核心技术
在每个流式多处理器( SM )的基础上, H100 张量核在使用 相同的数据类型 时为 A100 SM 的时钟提供两倍的矩阵乘法累加( MMA )吞吐量时钟,在比较 A100 SM 上的 FP16 和 H100 SM 上 FP8 时提供四倍的吞吐量时钟。为了利用 H100 的几个新功能,并利用这些速度极快的 Tensor Core ,必须开发新的内核。
H100 Tensor Cores 处理数据的速度如此之快,以至于很难同时向其提供足够的输入数据和对其输出数据进行后期处理。内核必须创建一个高效的管道,以便数据加载、 Tensor Core 处理、后处理和存储都能同时高效地进行。
新的 H100 异步事务壁垒有助于提高这些管道的效率。异步屏障允许生产者线程在发出数据可用性信号后继续运行。在数据加载线程的情况下,这大大提高了内核隐藏内存系统延迟的能力,并确保 Tensor Core 可以使用稳定的输入数据流。异步事务屏障还为使用者线程提供了一种有效的机制来等待资源可用性,以便它们不会在自旋循环中浪费 SM 资源。
张量记忆加速器( TMA )进一步增压这些内核。 TMA 旨在以本机方式集成到异步管道中,并提供多维张量从全局内存到 SM 共享内存的异步传输。
Tensor Core 速度如此之快,以至于地址计算等操作可能成为性能瓶颈; TMA 卸载了这项工作,以便内核能够尽快集中精力运行数学和后处理。
最后,新内核使用 H100 线程块集群来利用 GPU 处理集群( GPC )的位置。每个线程块集群中的线程块协作以更高效地加载数据,并为 Tensor Cores 提供更高的输入带宽。
NVIDIA H100 Tensor Core GPU 性能结果
从数据中心类别开始, NVIDIA H100 Tensor Core GPU 在服务器和脱机场景中的每个工作负载上都提供了最高的每加速器性能,与 A100 Tensor-Core GPU 相比,在脱机场景中性能提高了 4.5 倍,在服务器场景中性能提升了 3.9 倍。
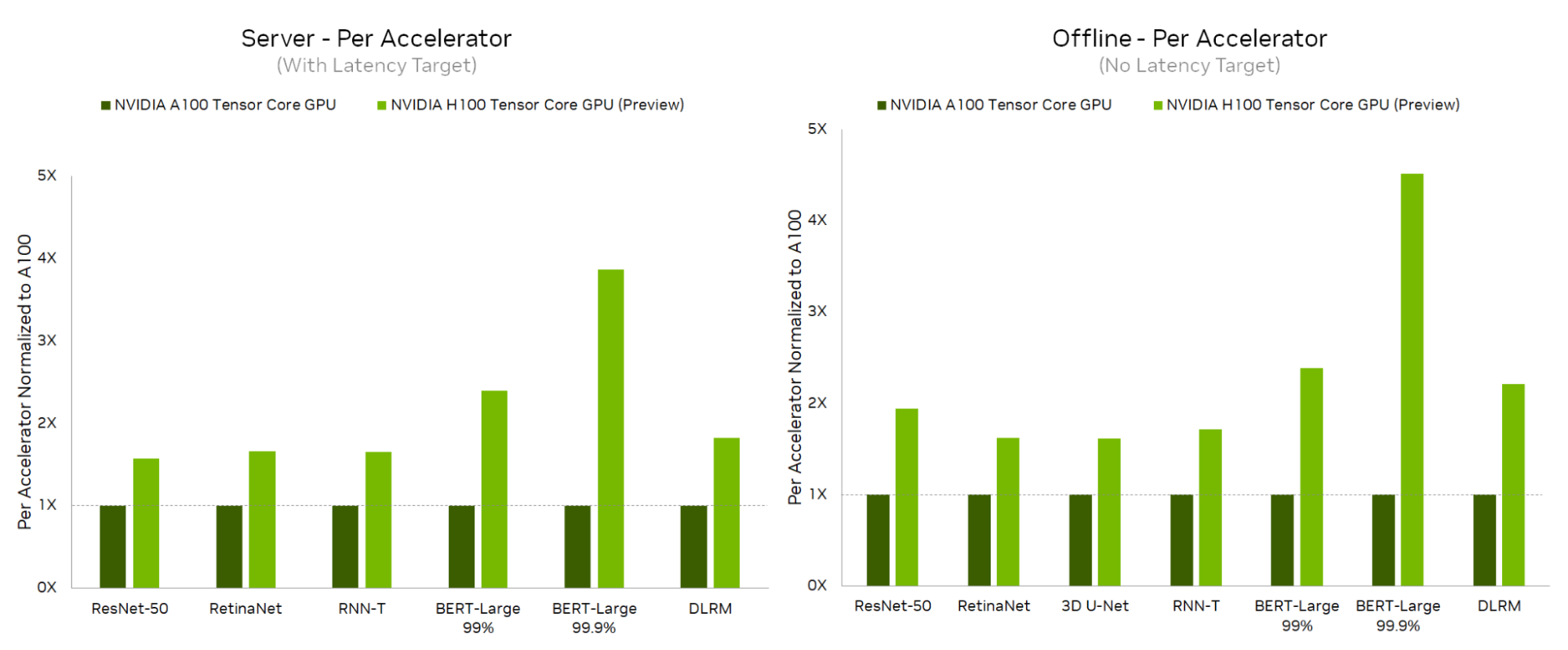
由于全栈改进,与上一轮相比, NVIDIA Jetson AGX Orin 实现了能源效率的大幅提高,效率提高了 50% 。
下面更详细地看一下使这些结果成为可能的软件优化。
使用 FP8 的高性能 BERT 推理
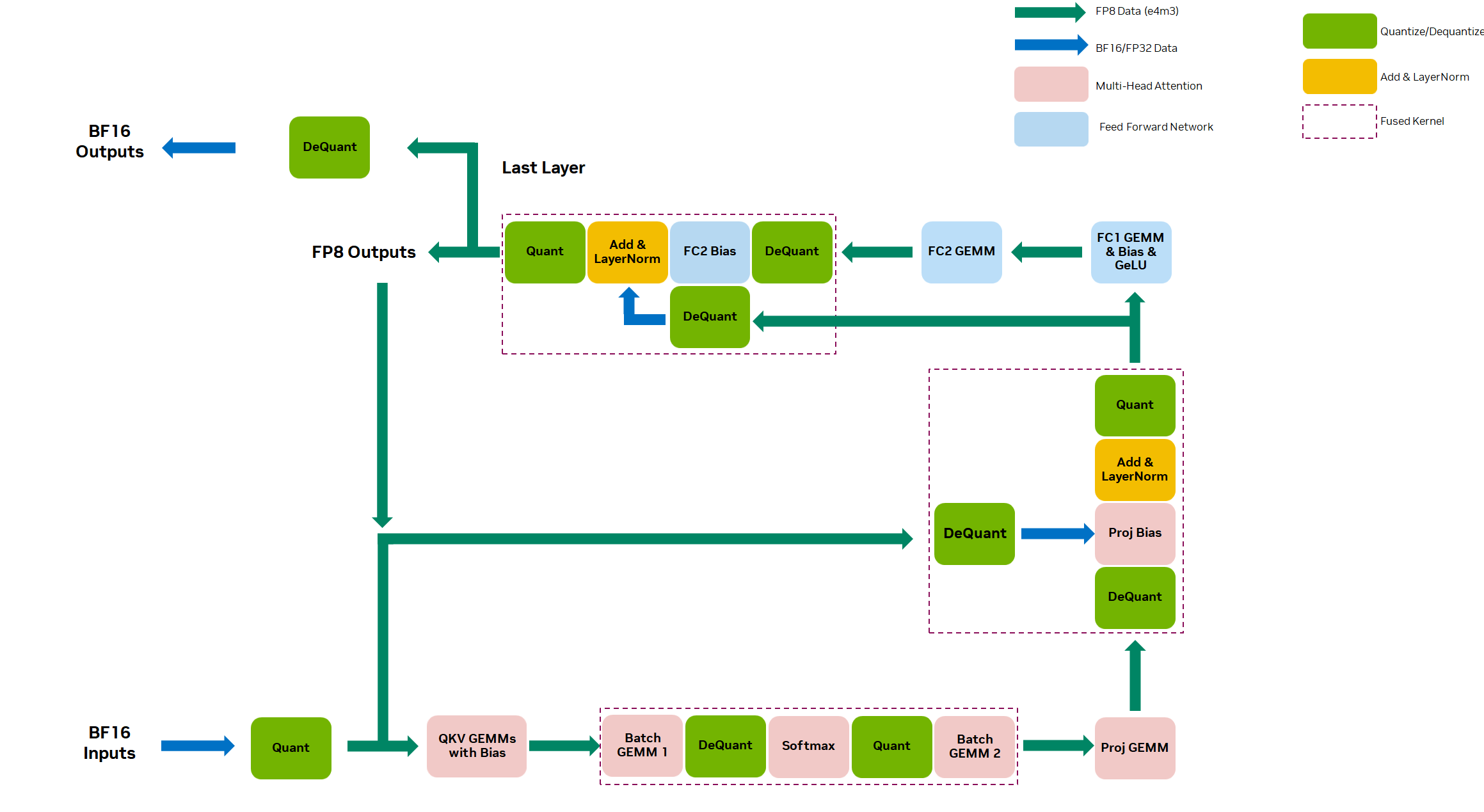
NVIDIA Hopper 架构 集成了新的第四代 Tensor Core ,支持两种新的 FP8 数据类型: E4M3 和 E5M2 。与 16 位浮点型相比,这些新的数据类型将 Tensor Core 吞吐量增加了 2 倍,并将内存需求减少了 2 倍。
E4M3 提供了一个额外的尾数位,这使得计算流程中的第一部份,前向传播的稳定性增加。 E5M2 的额外指数位更有助于防止反向传播期间的溢出/下溢。对于我们的 BERT FP8 提交,我们使用了 E4M3 。
我们对 BERT 等 NLP 模型的实验表明,当将模型从较高精度( FP32 )量化为较低精度(如 FP8 或 INT8 )时,用 FP8 观察到的精度下降低于 INT8 。
尽管我们可以使用 Quantization Aware Training( QAT )来恢复 INT8 的一些模型精度,但 Post Training Quantization( PTQ )下 INT8 的精度仍然是一个挑战。这就是 FP8 的优势所在:它可以在 PTQ 下提供 FP32 模型 99.9% 的精度,而无需运行 QAT 所需的额外成本和努力。因此, FP8 可用于先前需要 FP16 的 MLPerf 99.9% 高精度类别。从本质上讲, FP8 为这个工作负载提供了 INT8 的性能和 FP16 的精度。
在 NVIDIA BERT 提交编码器中的所有全连接和矩阵层都使用 FP8 精度。这些层使用 cuBLASLt 在 H100 Tensor Core上执行 FP8 GEMM 。
扩展了关键 BERT 优化以支持 FP8 ,包括以下内容:
- Removing padding: BERT 的输入具有可变序列长度,并填充到最大序列长度。我们去除填充以避免在填充上浪费计算,并在最终输出时重新构造填充,以便与输入形状相同。
- Fused multi-head attention :这是四种操作的融合:转置 Q / K 、 Q * K 、 softmax 和 QK * V 来计算注意力。融合这些计算可提高内存效率,跳过填充以防止无用计算。融合式多头注意力提供大约 2 倍的端到端加速。
- Activation fusion: 我们将矩阵与更多计算操作进行合并 ,包括 bias 和激活函数( GeLU )。这种融合还通过删除额外的内存传输来帮助提高内存效率。
用于对象检测的 RetinaNet
在 MLPerf 推断 2.1 中,添加了一个名为 RetinaNet 的新的单阶段对象检测模型。这取代了 MLPerf Inference 2.0 的 ssd-resnet34 和 ssd-mobilenet 工作负载。这一更新的模型体系结构及其新的推理数据集为提供快速、准确和高效的推理带来了新的挑战。
NVIDIA 提交了所有平台的 RetinaNet 结果,证明了我们软件支持的广度。
RetinaNet 是使用 Open Images 数据集 进行训练和推断的,与之前使用的 COCO 数据集相比,它包含的对象类别和对象符号数量级更多。对于 RetinaNet ,为训练和推理任务选择了 264 个独特的类。这比 ssd-resnet34 使用的 81 个类要多得多。

尽管 RetinaNet 也是一种单次目标检测模型,但与 ssd-resnet34 相比,它有几个关键区别:
- RetinaNet 使用 Feature Pyramid Network ( FPN )作为前馈 ResNeXt 架构之上的主干。 ResNeXt 在其计算块中使用群卷积,并且与 ResNet34 具有不同的数学特性。
- 对于每个图像, 120087 个框和 264 个唯一类分数被输入到非最大抑制( NMS )层,并选择前 1000 个分数框作为输出。在 ssd-resnet34 中,这些数字减少了 25 倍: 15130 个盒子,每个盒子 81 个等级, 200 个 topK 。
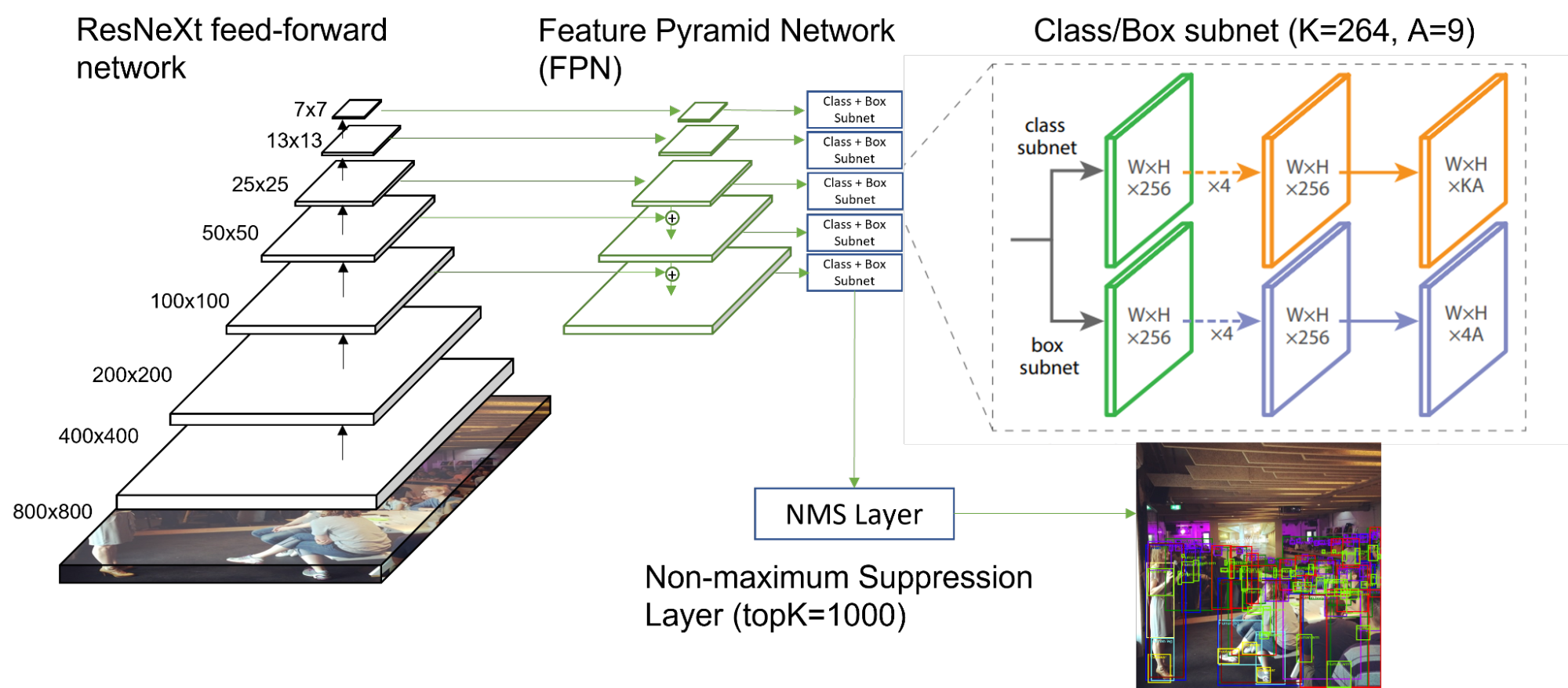
NVIDIA 使用 TensorRT 作为 RetinaNet 的后端。 TensorRT 通过自动优化图形执行和层执行,显著加快了推理吞吐量:
- TensorRT 完全支持以 FP32 / INT8 混合精度执行模型推断,与 FP16 和 FP32 精度相比,精度损失最小。
- TensorRT 自动为所有 16 个 ResNeXt 块的组卷积选择优化的内核。
- TensorRT 为卷积层、激活层和(可选)池层提供融合模式,通过合并层权重和减少操作次数,优化内存移动以加快推理。
- 对于后处理 NMS 层, NVIDIA 利用了 EfficientNMS ,这是一个开源的高性能 CUDA 内核,专门用于 NMS 任务,作为 TensorRT 插件提供。
NVIDIA Jetson AGX Orin 优化
NVIDIA Jetson AGX Orin 是最新的 NVIDIA 边缘人工智能和机器人应用平台。在这一轮 MLPerf 推断中, Jetson AGX Orin 在 MLPerf Inference 2.1 边缘工作负载的范围内展示了卓越的性能和能效改进。改进包括 ResNet-50 多流延迟减少 45% ,与上一轮( 2.0 版)相比, BERT 离线吞吐量提高 17% 。在提交的电源中, Orin 在选定基准上实现了高达 52% 的功率降低和 48% 的每瓦性能改进。提交的文件使用了 22.08 Jetson CUDA-X AI Developer Preview 软件,其中包括优化的 NVIDIA Jetson Linux ( L4T )映像、 TensorRT 8.5.0 、 CUDA 11.4.14 和 cuDNN 8.5.0 ,使客户能够轻松地从这些改进中受益。 RetinaNet 通过此软件堆栈在 Jetson AGX Orin 上得到完全支持并具有性能。这证明了 NVIDIA 平台和软件支持开箱即用的高性能 DL 推理的能力。
NVIDIA Orin 性能改进
MLPerf Inference v2.1 的显著改进来自于系统映像和 22.08 Jetson CUDA-X AI 开发者预览中 TensorRT 8.5 的总体性能提升。优化后的 Jetson L4T 映像为用户提供了 MaxN 电源模式,从而提高了 GPU 和 DLA 单元的频率。同时,此图像可以选择使用 64K 的放大页面大小,这样可以在运行某些推断工作负载时减少 TLB 缓存未命中。此外,映像中本机包含的 3.10.1 DLA 编译器包含一系列优化功能,可将 Orin DLA 上运行的工作负载性能提高 53% 。
TensorRT 8.5 包括两种新的优化,可提高推理性能。第一个是对 cuDLA 的本机支持,它消除了在 DLA 节点和 GPU 节点之间插入复制节点的强制要求。我们观察到,从 NVMedia 到 cuDLA , DLA 引擎端到端的改进约为 1.8% 。第二个是为小通道*滤波器大小的卷积添加优化核,与 beta = 1 剩余连接融合。这将 Orin 中 GPU 的 BERT 性能提高了 17% , ResNet50 性能提高了 5% 。
NVIDIA Orin 能效改进
NVIDIA Orin 电源提交文件得益于上述所有性能改进,并重点关注进一步降低功率。使用 Orin 更新的 L4T 映像,可以通过微调每个基准的 CPU 、 GPU 和 DLA 频率来降低功耗,以实现每瓦特的最佳性能。此图像还支持新的平台节能功能,如调节器自动断相和低负载条件下的低功率状态。 Orin 中 USB-C 支持的灵活性被用于通过 USB 通信上的以太网整合所有 I / O 。通过禁用以太网、 WiFi 和 DP 等非推理必需的 I / O 子系统,以及使用现成的更高效 GaN 电源适配器,进一步降低了系统功耗。
这些平台和软件优化将系统功耗降低了 52% ,每瓦特性能比我们之前在 2.0 中提交的文件提高了 48% 。
3D U-Net 性能改进
在 MLPerf Inference v2.0 中, 3D U-Net 医学成像工作负载切换到 KITS19 数据集,这将图像大小增加了 8 倍,并且由于滑动窗口推断,将给定样本所需的计算处理量增加了 18 倍。有关 NVIDIA MLPerf Inference v2.0 提交的更多信息,请参阅 Getting the Best Performance on MLPerf Inference 2.0 。
对于 MLPerf Inference 2.1 ,我们使用 TensorRT IPluginV2DDynamicExt 插件进一步改进了第一个卷积层的性能。
KiTS19 图像是单通道张量,这对 3D U-Net 中第一个 3D 卷积的性能提出了挑战。在 3D 卷积中,此通道尺寸通常会影响 GEMM 的 K 尺寸。这一点特别重要,因为 3D U-Net 的总体性能主要由前两个和后两个 3D 卷积决定。在 MLPerf Inference v2.0 中,这四个卷积约占整个网络运行时间的 38% ;第一层占 8% 。一个非常重要的因素解释了这一点,即需要使用零填充来适应 NC / 32DHW32 矢量化格式布局,其中张量核心可以得到最有效的利用。
在我们更新的插件中,我们使用 INT8 Linear 格式对这个单通道有限的 3D 形状输入进行高效计算。这样做有两个好处:
- 更有效地使用触发器 :不执行不必要的计算
- PCIe 传输 B / W 节省 :避免在主机和 GPU 内存之间移动零填充输入张量或在将输入张量发送到 TensorRT 之前在 GPU 上进行零填充的开销
此优化将第一层性能提高了 2.7 倍。此外,切片内核不再需要处理零填充,因此其性能也提高了 2 倍。最终, 3D UNet 在 MLPerf Inference 2.1 中的端到端性能提高了 5% 。
打破跨工作负载的性能记录
在 MLPerf Inference 2.1 中,首次提交的 NVIDIA H100 为数据中心场景中的所有工作负载创造了新的每加速器性能记录,性能比 A100 高出 4.5 倍。由于 NVIDIA Hopper 体系结构的许多突破以及利用这些功能的巨大软件优化,这一代性能提升是可能的。
NVIDIA Jetson AGX Orin 仅在一轮中就实现了高达 50% 的能效提升,并继续为边缘人工智能和机器人应用提供整体推理性能领先。
最新一轮 MLPerf 推断展示了 NVIDIA AI 平台在全方位 AI 工作负载和场景中的领先性能和多功能性。凭借 H100 Tensor Core GPU ,我们正在为 NVIDIA AI 平台提供最先进的型号,并为用户提供更高级别的性能和能力,以满足最苛刻的工作负载。
有关详细信息,请参阅 NVIDIA Hopper Architecture In-Depth 。




