
GPU 随着新一代的出现而不断加快,通常情况下 GPU 上的每个活动(如内核或内存拷贝)都会很快完成。在过去,每个活动都必须由 CPU 单独安排(启动),相关的开销可能会累积起来,成为性能瓶颈。 CUDA Graphs功能通过将多个 GPU 活动安排为单个计算图来解决这个问题。
这篇文章描述了 CUDA Graphs 最近是如何被GROMACS,是一个用于生物分子系统的模拟包,也是世界上使用率最高的科学软件应用程序之一。我们将介绍 CUDA Graphs 和 GROMACS ,描述我们将 CUDA Graphs 集成到 GROMACS (以及与 GROMACS 共同设计)中的工作,展示性能结果,并向您展示如何在 GROMACS 中使用 CUDA Graphs
经过 NVIDIA 和core GROMACS developers,以充分利用现代 GPU 加速服务器。有关更多详细信息,请参阅Creating Faster Molecular Dynamics Simulations with GROMACS 2020,Maximizing GROMACS Throughput with Multiple Simulations per GPU Using MPS and MIG,Massively Improved Multi-node NVIDIA GPU Scalability with GROMACS和Heterogeneous parallelization and acceleration of molecular dynamics simulations in GROMACS(以及其中的参考文献)。
出身背景
GROMACS 之旅的最新一步是使用 CUDA 图来进一步提高性能。此功能在 2023 年的新版本中可用。这项联合设计工作不仅包括应用程序级专家,还包括 NVIDIA CUDA 软件开发团队。将 GROMACS 与尖端的 CUDA Graphs 技术相结合进行改进,最终将使其他应用受益。
CUDA 图
本节以 GROMACS 友好的方式对 CUDA 图形进行了非常简要的概述。请参阅上一篇文章,Getting Started with CUDA Graphs,以全面介绍 CUDA 图形。
图 1 描述了许多 GPU 活动的计划和执行。对于传统的流模型(左),每个 GPU 活动都由 CPU API 调用单独调度。使用 CUDA Graphs (右),单个 API 调用可以调度整个 GPU 活动集
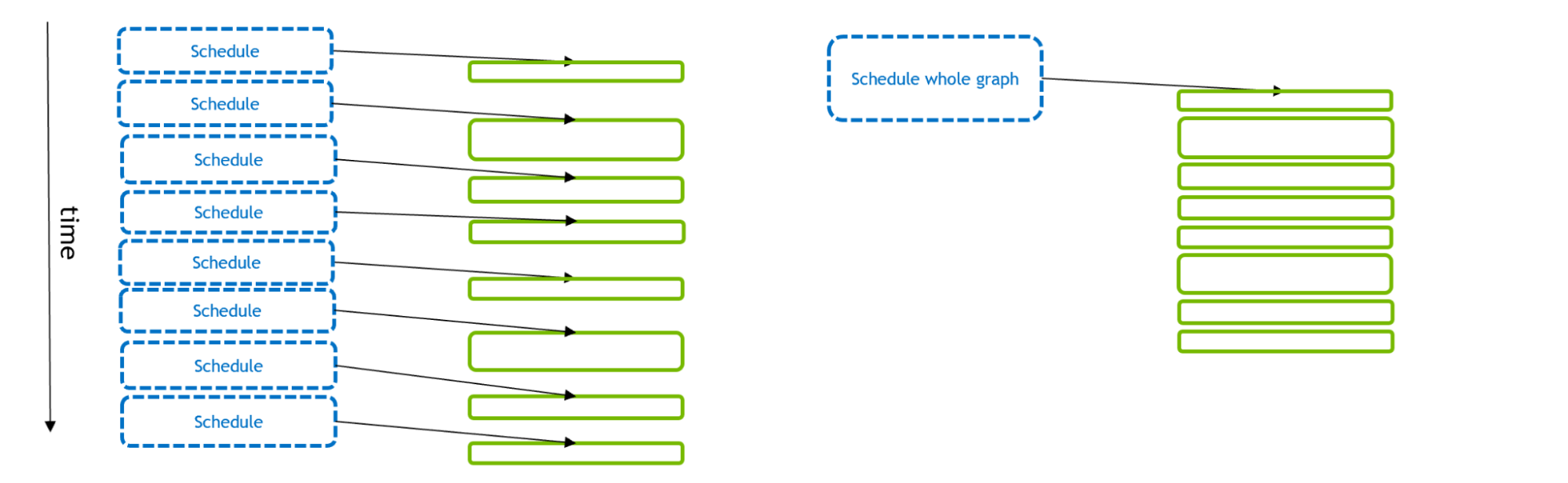
如果 GPU 活动很小,那么计划可能需要比执行更多的时间。这使 GPU (在内核之间留下间隙)变得匮乏,总体执行效果不佳。但是,如果在单个 CUDA 图中调度多个- GPU 活动,则可以减少 CPU API时间,从而实现更优化的 GPU 执行。此外,通过Graphs, CUDA 驱动程序具有关于工作流的额外信息,可以利用这些信息来优化图本身的 GPU 执行。
如中所述Getting Started with CUDA Graphs,将现有的基于流的代码调整为使用图是相对简单的。该功能通过一些额外的 CUDA API 调用将流执行“捕获”到一个图中。我们利用这一功能,使预先存在的 GROMACS 代码能够使用图形而不是流来执行。
格罗马克
GROMACS 是了解重要生物过程的关键工具,包括新冠肺炎等潜在流行病。每次 GROMACS 模拟都使用牛顿运动方程,通过重复更新来演化许多粒子的系统,其中粒子间的力决定粒子的运动
尽管物理原理相当简单,但要通过多个级别的并行化和加速来实现非常高的性能,实现(必然)极其复杂。因此,每个模拟时间步长都涉及一个高度复杂的(通常是微秒级的)任务调度
图 2 从左到右显示了 GROMACS 是如何进化成为分子动力学的异步 GPU 引擎的。
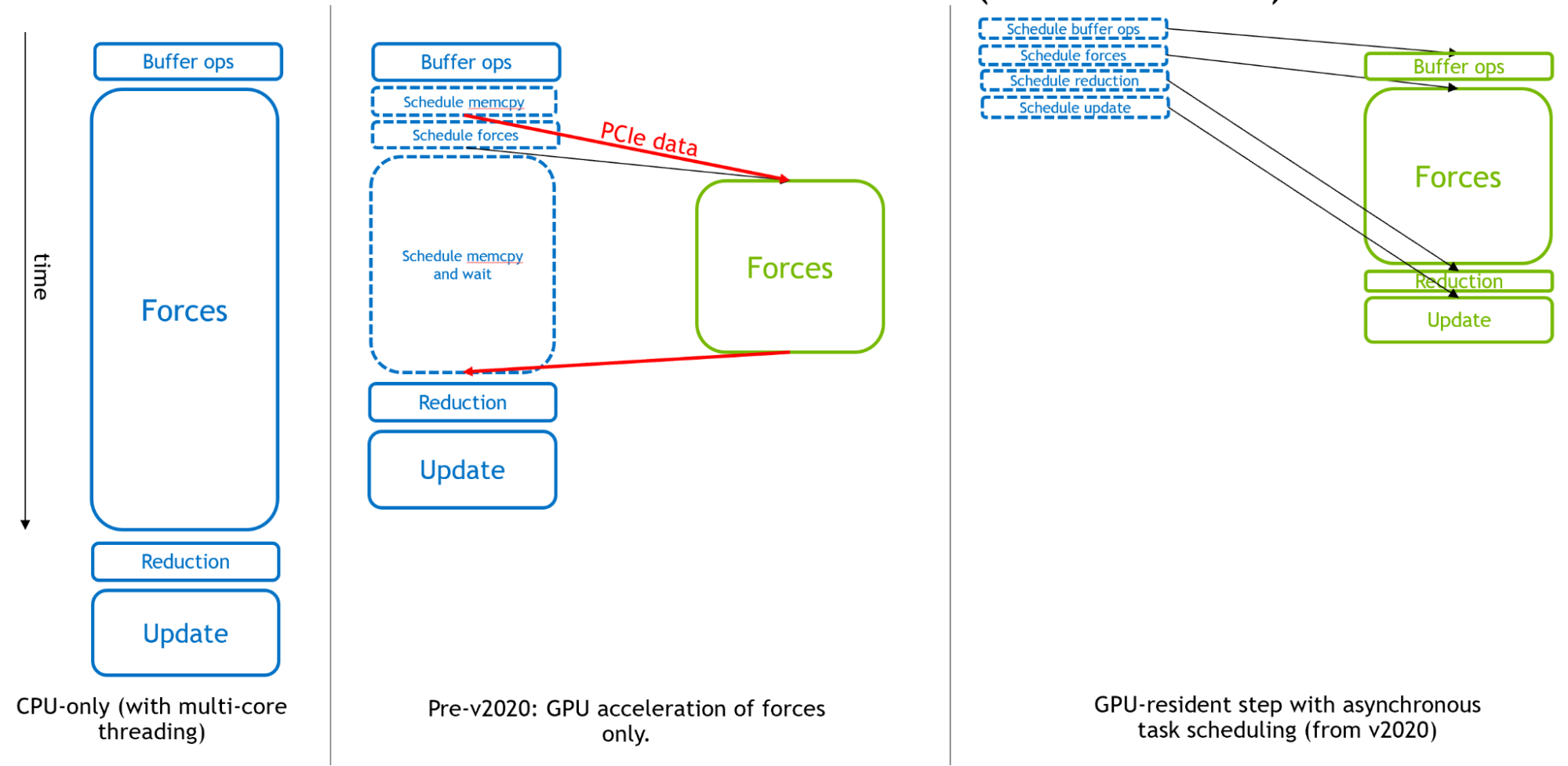
最初, CPU 用于整个模拟时间步长。然后,在 GPU 计算的早期,为了获得有效的整体加速度,昂贵的力计算被转移到GPU。
最后,为了支持极快的现代 GPU ,从GROMACS版本2020开始,所有其他组件都可以卸载,以启用“GPU驻留模式”,在这种模式下,模拟状态在 GPU 上保持多次迭代, CPU 主要负责调度在 GPU 上异步执行的活动。要了解更多信息,请参阅Creating Faster Molecular Dynamics Simulations with GROMACS 2020.
图 2 的右侧部分显示了 GPU 计算,如果它们足够大,将如何形成执行的“关键路径”,从而使这些组件的性能决定整体模拟性能
然而,随着 GPU 性能的不断提高,小的情况可能会受到 CPU 调度开销的限制,而不是如前一节中所述的GPU执行。当并行使用多个 GPU 来执行单个GROMACS模拟时,尤其如此
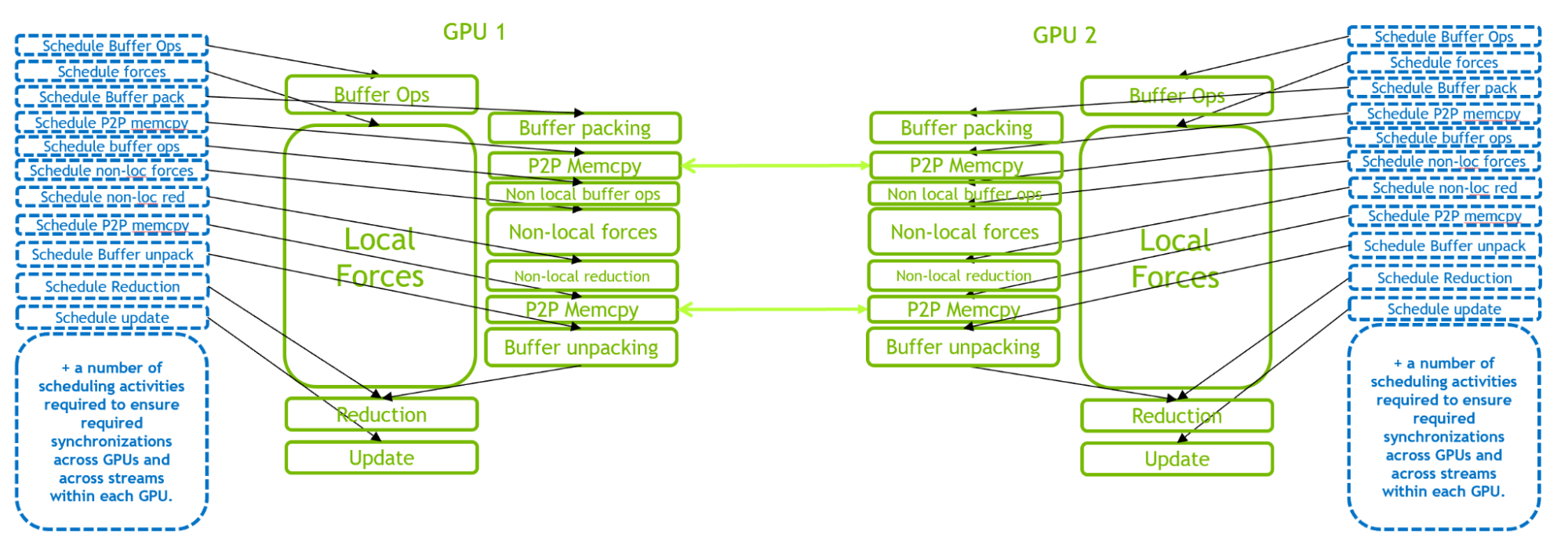
图3说明了2- GPU 情况下的 GPU -驻留模式。由于 GPU 内部和内部的复混合编程互,与单个GPU情况相比,这种情况下的 CPU 调度工作负载要求更高。当引入更多 GPU 时,调度工作负载的要求甚至更高。
因此,在许多小情况下,性能瓶颈是 CPU 调度开销,而不是 GPU 执行。这促使在 GROMACS 中引入 CUDA 图,以使多个活动能够作为单个图进行调度,如以下部分所述。
在 GROMACS 中实现 CUDA 图
本节介绍了 CUDA 图在 GROMACS 中的引入。在高层,图形捕获和回放功能的使用方式与中提供的示例类似Getting Started with CUDA Graphs.
GROMACS 实现中存在许多与 GROMACS 可以在不同步骤上执行的不同类型的任务有关的复杂性,以及与管理多 GPU 任务和域分解有关的复杂性。请继续阅读以获得简要概述。有关完整的技术细节,请参阅 GitLab Issue ,Implement CUDA Graph Functionality and Perform Associated Refactoring,以及其中链接的合并请求
请注意, GROMACS 执行不同类型的模拟步骤:“常规”步骤加上不频繁的“不规则”步骤,其中包括必须偶尔执行的额外活动(压力耦合、温度耦合、邻居列表更新、域分解和许多其他)。我们已经通过每一步使用一个单独的图将 CUDA 图引入 GROMACS ,并且到目前为止只支持在自然界中完全 GPU 存在的常规步骤
在每个模拟时间步长上:
- 检查此步骤是否可以支持 CUDA Graphs 。如果是:
- 检查是否已经存在合适的图形。如果是:
- 执行该图
- 否则:捕获、实例化和保存新图形
- 检查是否已经存在合适的图形。如果是:
- 否则:使用传统流执行步骤
这使得可以在绝大多数步骤中使用 CUDA 图来执行。有必要为每个邻居列表或域分解步骤(通常每 100-400 个步骤)重新捕获并创建一个可执行的新图,这是非常罕见的,因此开销最小
对于多个 GPU ,在所有 GPU 中使用单个图形。到目前为止,这只支持thread-MPI,其中,多 GPU 图是通过利用 CUDA 的自然能力来定义的,该能力可以在同一进程内(使用基于事件的 GPU – 侧同步)在不同的 GPU 之间分叉和连接流,并将这些工作流自动捕获到单个图中。
我们在 GROMACS 中创建了一个新类来管理所有必需的功能。对于 multi-GPU ,这包括额外的基于事件的分叉和连接操作,以使单个图能够在多个 GPU 上定义和执行。
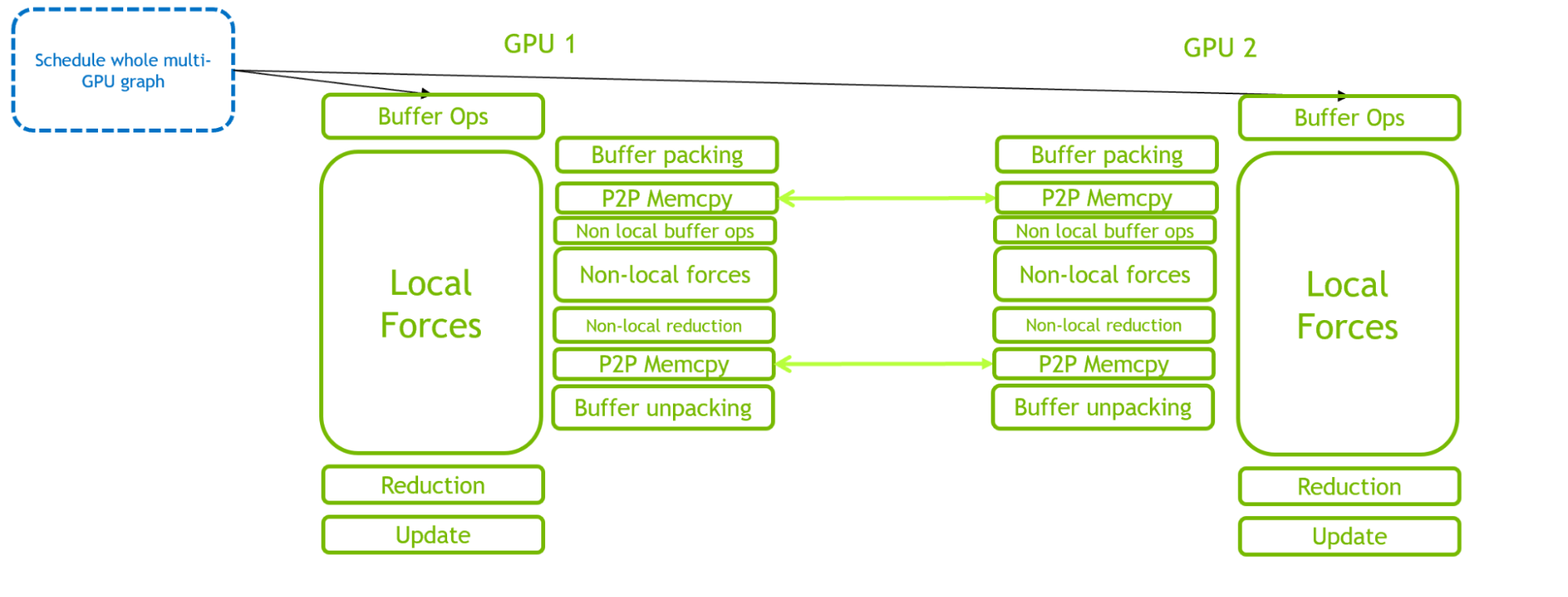
通过比较图 3 和图 4 ,可以清楚地看到 CUDA 图在减少 CPU 侧开销方面的优势。关键路径从 CPU 调度开销转移到 GPU 计算。
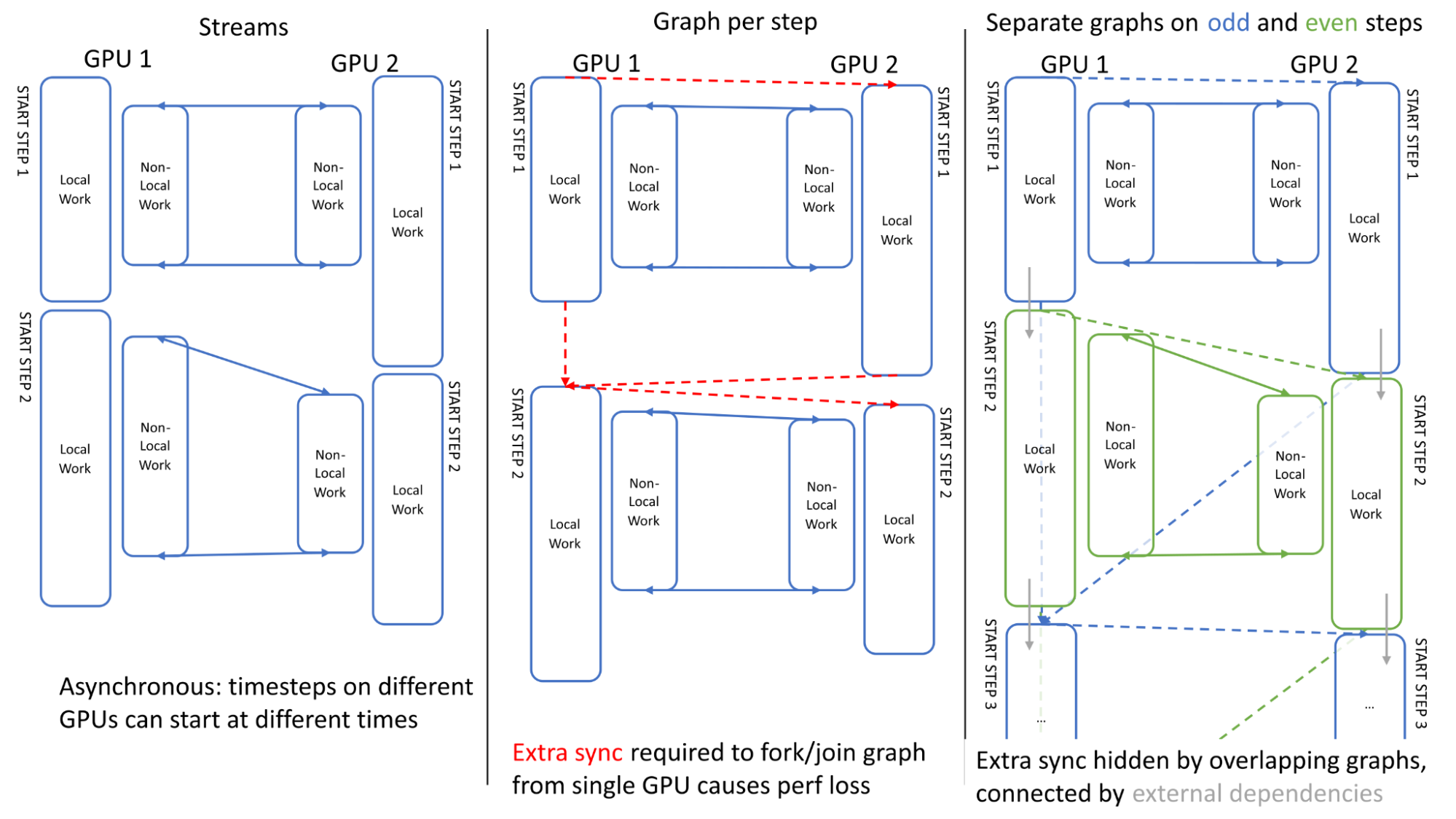
为了最大限度地提高多个 GPU 的性能,在链接多个模拟时间步长时,确保GPU之间的异步是很重要的。图5展示了两个步骤中的 GPU 活动。可以看出,当使用传统流时, GPU 之间的执行是异步的: GPU 1可以在 GPU 2完成其第一步之前开始第二步(左)
我们第一次尝试使用单个图进行调度时遇到了一个问题:定义图所需的额外同步(在单个 GPU 上分叉/连接到起点/终点)失去了这种异步性,导致了开销(中心)
我们通过在奇数和偶数步骤上使用单独的图(右)来克服这个问题,其中这些步骤使用“外部” CUDA 事件进行链接,这些事件可以记录在一个图中,并在另一个图内排队(用灰色箭头表示),有效地重叠了额外的同步。
图 6 显示了典型 4- GPU 配置的规则时间步长产生的真实图形。我们不打算描述细节,但包括这张图,以提供所涉及的许多活动和依赖关系的可视化,以及 CUDA Graphs 如何能够如此有效地处理这种复杂性。
CUDA Graphs 技术本身的开发受到 GROMACS 要求的指导,包括支持与多线程图形捕获相结合的图形更新,以及图形中的流优先级支持。这些增强功能最终也将使其他应用程序受益。
性能结果
我们使用了Water Box一组基准测试来展示 GROMACS 中 CUDA 图的优势。这组基准可在gromacs.org benchmark repository它具有提供多个原子计数的优点,能够评估性能行为如何随系统大小而扩展
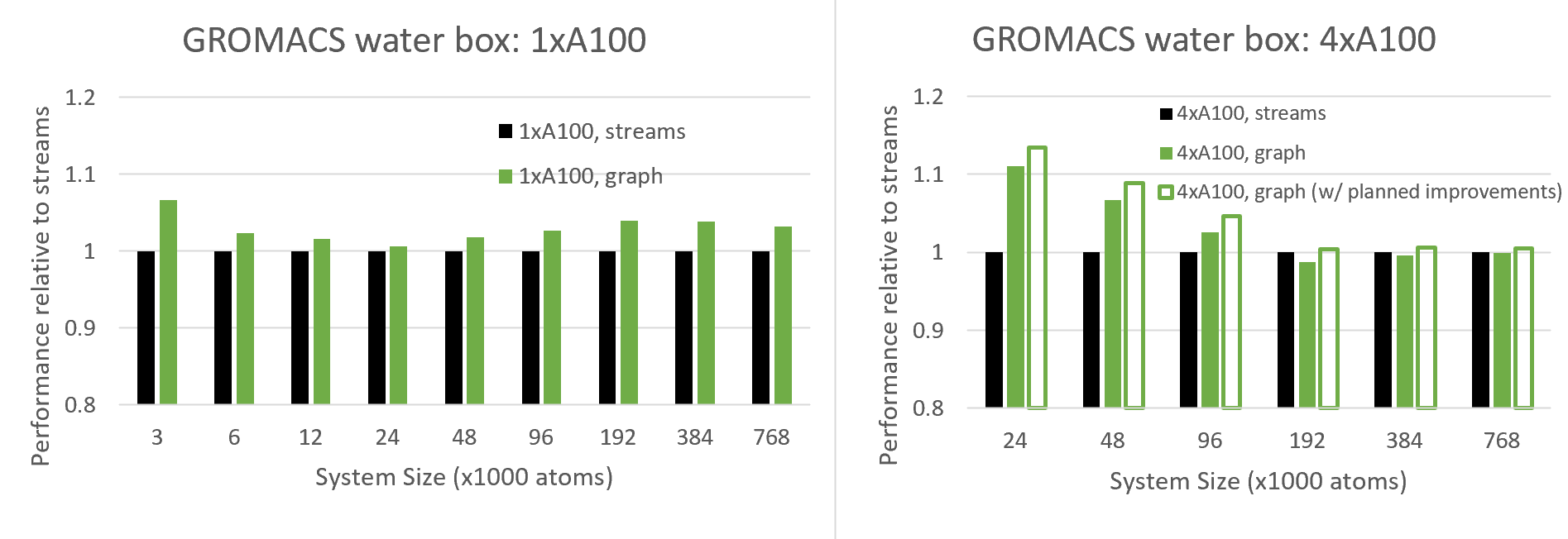
图7比较了新的 CUDA Graphs功能与传统流在不同系统大小下的性能,包括单次- GPU 和4-GPU运行
由于 CUDA 图旨在减少 CPU API 开销,这在小情况下最为显著,我们预计在小系统规模下会看到越来越多的好处,我们确实在多 GPU 情况下看到了这种行为,在单 GPU 24K 原子及以下情况下也看到了这种行为
有趣的是,对于 24K 原子以上的单 – CUDA 情况,随着系统尺寸达到 100K 原子左右,其益处实际上会增加。可以看出,与各种系统尺寸相比,图形提供了显著的性能优势。这种行为需要更多的研究,但我们预计这是由于 GPU 图增加了 GPU 方面的好处,其中当使用图时, CUDA 可以更有效地跨多个内核调度线程块。
对于多 GPU 情况,图的好处更为深刻,因为(如上所述)由于其复杂的调度,该配置对 CPU API 开销更为敏感。在目前的版本中,我们看到了高达 100K 原子的好处(在这种情况下),超过这个数字我们会看到轻微的退化
然而,我们也显示了计划改进的预期结果,这减少了与重复重新构建图相关的开销。这种改进需要在 CUDA 驱动程序的未来版本中提供支持,该驱动程序目前正在与 GROMACS 共同设计中进行改进。通常,我们建议用户针对自己的情况尝试 CUDA Graphs ,并在有利的情况下启用该功能(请参阅下一节)。
如何在 GROMACS 中使用 CUDA 图
如上所述,这种新的 CUDA Graphs功能可用于 GPU 驻留步骤,当所有力和更新计算通过以下方式卸载到GPU 时,通常会调用这些步骤mdrun选项:
-nb gpu -bonded gpu -pme gpu -update gpu当与多个任务一起运行以并行启用多个 GPU 时, GROMACS 应该使用其内部线程 MPI 库而不是外部 MPI 来构建 (-DGMX_MPI=OFF) ; GPU 应通过设置以下环境变量来指定直接通信:
export GMX_ENABLE_DIRECT_GPU_COMM=1单个 PME GPU 应指定-npme 1.
然后,可以使用以下内容触发 CUDA 图:
export GMX_CUDA_GRAPH=1我们建议在任何特定情况下进行实验,如果可以提供性能优势,则选择使用图形。请注意,这仍然是一个实验性特征,测试有限,因此应注意确保结果如预期(例如,通过比较有图和无图的科学结果子集)。我们欢迎在GROMACS GitLab地点
总结
这篇文章描述了我们如何将 CUDA 图集成到 GROMACS 中。这使得 CPU 能够在单个计算图中调度多个 GPU 活动,这比传统的流编程模型更优化。我们展示了这些好处,包括在并行运行多个 GPU 时。这项工作是我们不断努力的重要组成部分,旨在通过基于图形的任务调度使 GROMACS 现代化,以帮助开发日益复杂的硬件来解决日益复杂的科学问题
要开始,请按照本文中提供的说明,尝试为您自己的 GROMACS 案例激活 CUDA Graphs
想了解更多信息吗?加入GROMACS forum.




