
文本到图像的 Diffusion 模型已经被建立为基于给定文本的高保真图像生成的强大方法。然而, Diffusion 模型并不总是在给定的输入文本和生成的图像之间实现所需的对齐,尤其是对于现实生活中没有遇到的复杂的特殊提示。因此,人们对有效地微调 Diffusion 文本到图像模型以实现即时对齐并最大化文本到图像评分模型越来越感兴趣。
直接奖励微调(DRaFT)是一种简单而有效的方法,旨在微调 Diffusion 模型,以最大化可微分的奖励函数,如可微分报酬的直接微调 Diffusion 模型所示。
这篇文章解释了 Diffusion 模型的 DRaFT 方法,以更好地与不同和复杂的提示保持一致。我们还介绍了 DRaFT+,它增强了 DRaFT 方法的能力,并解决了它们的主要缺点。
现在,您可以通过访问 DRaFT+ 算法和示例代码 NeMo Aligner 库 在 GitHub 上。NVIDIA NeMo 是一个端到端的平台,用于在任何地方开发自定义生成人工智能。它包括用于训练、微调、检索增强生成、防护、数据管理工具和预训练模型的工具,为企业提供了一种简单、经济高效、快速的方式来采用生成人工智能。未来,我们计划将 DRaFT+ 算法集成到 NeMo 框架容器 中。
直接奖励微调(DRaFT)
以下部分详细探讨了 DraFT 算法及其局限性,并深入探讨了我们如何增强和开发 DraFT+算法。
鉴于人类反馈强化学习(RLHF)方法在大语言模型(LLM)微调中取得了显著成功,生成文本到图像社区已经测试了类似的想法,以提高图像生成的保真度。这些方法将 Diffusion 过程视为完整的 RL 轨迹,并使用文本到图像的评分模型进行引导。有关更多信息,请参阅 DPOK:用于微调文本到图像 Diffusion 模型的强化学习 和用强化学习训练 Diffusion 模型。
然而,这些方法有两个缺点。首先,强化学习(RL)样本是低效且计算昂贵的训练过程。其次,它们只在狭窄的提示领域取得了成功,并且在不同的提示中缺乏可推广性。
为了解决这些问题,作为 RL 的替代方案,DRaFT 方法建议通过 Diffusion 过程直接反向传播可微分奖励。尽管该方法比 RL 过程更简单,但它在更大的范围内(数十万个提示)实现了文本和输入提示之间明显更好的对齐,计算时间快了几个数量级。
然而,对于相同的提示,原始的 DRaFT 方法容易出现奖励过度优化、模式崩溃和缺乏多样性的问题。为了解决这些缺点,我们引入了 DRaFT+,它添加了一个正则化项来增强生成多样性,控制优化的回报,并防止模式崩溃。
DRaFT 方法微调了 Stable Diffusion v1.5 模型(来自 具有潜在 Diffusion 模型的高分辨率图像合成),参数化方式为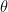

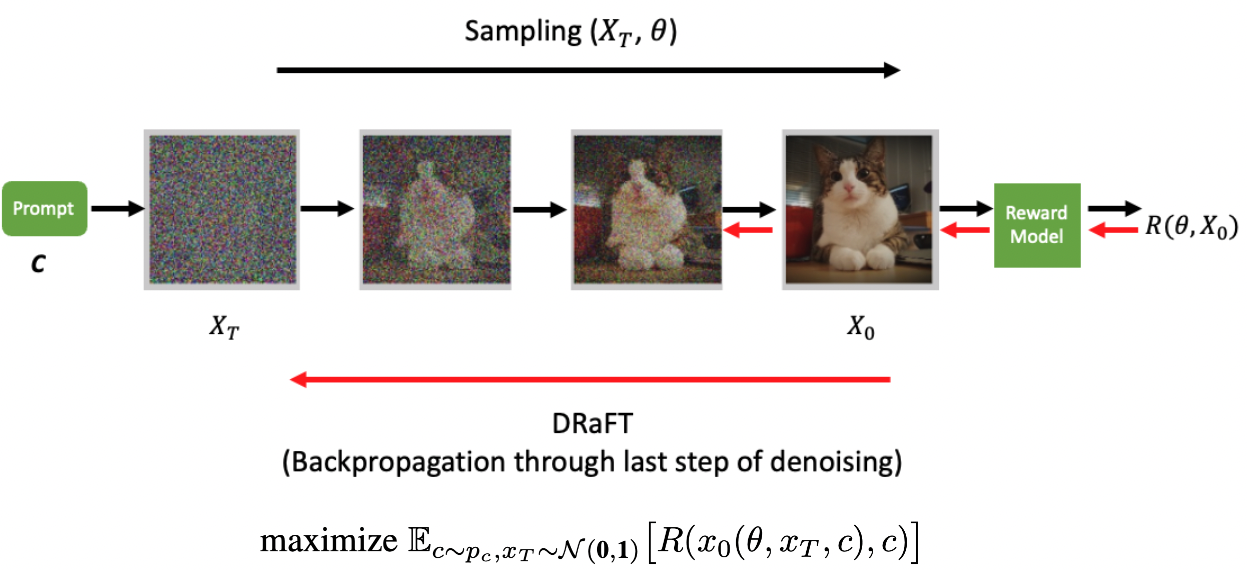
![{maximize}\;\mathbb{E}_{c\sim p_{c}, x_{T}\sim\mathcal{N}(\textbf{0},\textbf{1})}\big[R(x_{0}(\theta, x_{T}, c), c)\big]](https://s0.wp.com/latex.php?latex=%7Bmaximize%7D%5C%3B%5Cmathbb%7BE%7D_%7Bc%5Csim+p_%7Bc%7D%2C+x_%7BT%7D%5Csim%5Cmathcal%7BN%7D%28%5Ctextbf%7B0%7D%2C%5Ctextbf%7B1%7D%29%7D%5Cbig%5BR%28x_%7B0%7D%28%5Ctheta%2C+x_%7BT%7D%2C+c%29%2C+c%29%5Cbig%5D&bg=transparent&fg=000&s=0&c=20201002)
在这里 
在反向过程中,我们计算生成的奖励相对于 Diffusion 模型权重的梯度。然而,仅通过奖励模型进行反向传播,并且仅通过 Diffusion 模型的最后一个去噪步骤。令人惊讶的是,如可微分报酬的直接微调 Diffusion 模型所示,在 Diffusion 过程中反向传播一个以上的步骤会导致算法的奖励降低。
图 1 展示了使用 vanilla DRaFT 的前后传球。从正态分布采样的初始噪声通过 Diffusion 模型以获得以输入文本(c)为条件的去噪图像。去噪后的图像被传递到(冻结的)可微分奖励模型。
草稿
普通 DRaFT 算法的主要缺点是模式崩溃、奖励黑客攻击和缺乏多样性。换言之,随着 Diffusion 模型相对于奖励模型进行训练,它逐渐学会增加奖励,同时对于输入到 Diffusion 模型中的不同初始纯噪声,它会塌陷到相同的图像 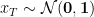
DRaFT 的作者提到了两种解决此类问题的尝试:在奖励函数中添加辍学者,并在奖励中添加一个术语,以促进微批量中图像对之间的差异。然而,他们也提到,这些方法并不能完全缓解这一问题。
相反,我们的方法使用了两个版本的稳定 Diffusion 模型,一个是针对奖励模型进行训练,另一个是使用冻结权重进行训练。根据 RLHF 实践,我们建议在训练目标中添加一个正则化项,以惩罚冻结模型和正在训练的模型之间的差异。
我们通过添加两个模型预测的噪声高斯之间的 Kullback-Leibler(KL)散度(此处等效于 L2 距离),将这样的术语纳入以下训练目标中引入的目标中。
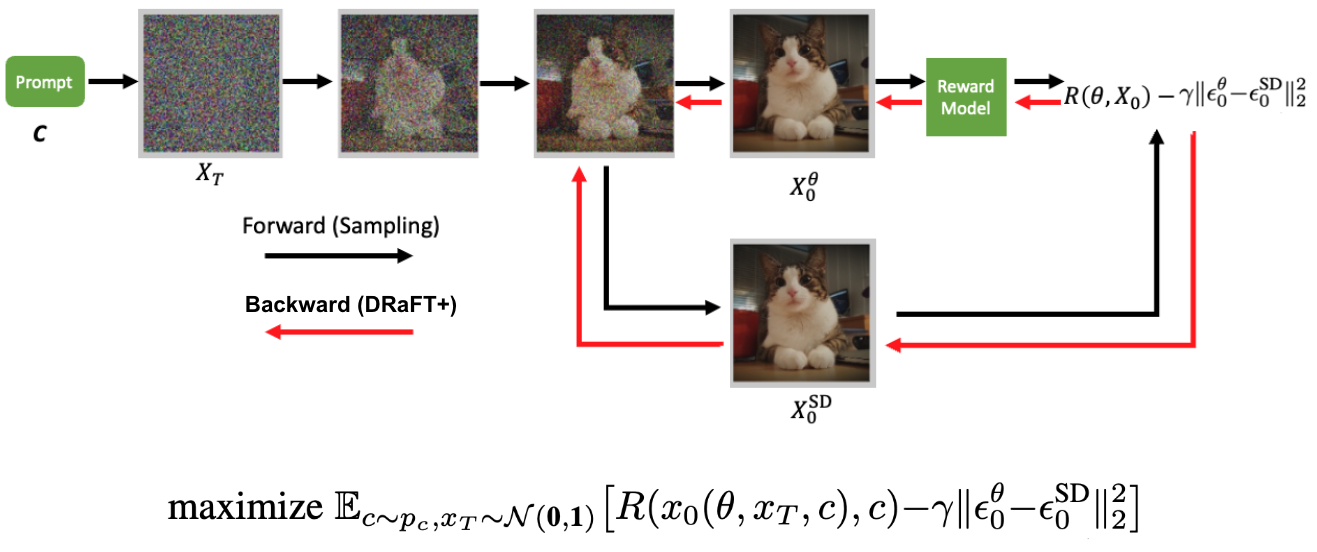
在这种情况下,

图 2 展示了 DRaFT+算法的前向-后向传递。从正态分布采样的初始噪声通过可训练 Diffusion 模型,但去噪的最后一步也通过冻结 Diffusion 模型来完成。这导致以输入文本(c)为条件的两个去噪图像。将来自可训练模型的去噪图像传递到可微分奖励模型。奖励减去由可训练和冻结模型生成的去噪图像之间的距离,通过 Diffusion 模型进行反向传播以更新其参数。
使用训练 DRaFT+NeMo Aligner 库 非常简单,只需指定数据集和检查点,然后运行以下脚本。
GPFS="/path/to/nemo-aligner-repo"
TRAIN_DATA_PATH="/path/to/train_dataset.tar"
UNET_CKPT="/path/to/unet_weights.ckpt"
VAE_CKPT="/path/to/vae_weights.bin"
RM_CKPT="/path/to/reward_model.nemo"
NUM_DEVICES=#number of gpus
torchrun --nproc_per_node=${NUM_DEVICES} ${GPFS}/examples/mm/stable_diffusion/train_sd_draftp.py \
trainer.num_nodes=1 \
trainer.devices=${NUM_DEVICES} \
model.micro_batch_size= \
model.global_batch_size= \
model.kl_coeff= \
model.optim.lr= \
model.unet_config.from_pretrained=${UNET_CKPT} \
model.first_stage_config.from_pretrained=${VAE_CKPT} \
rm.model.restore_from_path=${RM_CKPT} \
model.data.train.webdataset.local_root_path=${TRAIN_DATA_PATH} \
exp_manager.explicit_log_dir=/results
欲了解更多关于运行脚本和设置的信息,请参阅 DRaFT+ 用户指南。
DRaFT+训练的结果
本节介绍了使用 DRaFT+目标函数训练稳定 Diffusion 模型的结果。正则化提高了生成的微调图像的多样性。对于这个问题,我们改变目标函数中正则化项的系数,并绘制多样性度量与奖励的关系图。
在这里,我们使用的多样性度量来自 深层特征作为感知度量的不合理有效性,该方法基本上基于来自预定义网络(Alexnet)的两个图像补丁的激活来计算两个给定图像的感知相似性。更高的 LPIPS 分数转化为更多样的图像。
我们比较了稳定 Diffusion v1.5、香草 DRaFT、具有不同正则化系数的 DRaFT+和 DDPO 的 LPIPS 得分测量。对于奖励模型,我们使用中介绍的 PickScore 奖励模型Pick-a-Pic:一个开放的文本到图像生成用户偏好数据集,请注意,对于相同的奖励,我们的模型获得了更好的多样性得分。
图 3 显示了多样性和回报之间的权衡。左边的图表显示,较低的 KL 导致较低的 LPIPS 分数(较少的多样性和更容易发生模式崩溃)。中间的图表显示 KL 越低,奖励越高。右图显示,对于相同的奖励,与香草 DRaFT 相比,DRaFT+获得了更好的多样性得分(相当于 KL 为 0 的 DRaFT+)。换言之,在奖励阈值的情况下,引入正则化项将导致模型在实现该奖励的同时具有更好的多样性得分。
所有模型都在动物数据集上训练了 200 个时期。多样性得分是在来自相同提示的 100 个生成图像的固定数据集上训练期间测量的,并且总得分是 100 个图像之间的平均成对 LPIPS 得分。
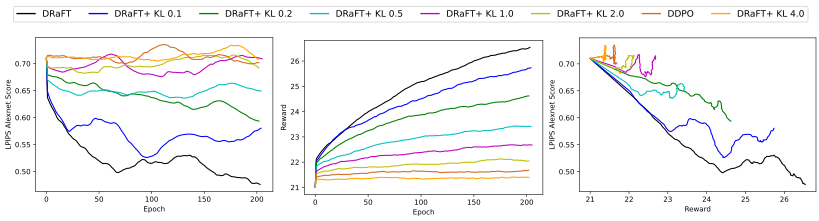
图 4 显示了在动物数据集上训练 200 个时期后,针对不同模型的相同提示生成的图像。图中的每一行都包含来自模型不同变体的具有相同初始随机种子的生成图像。该图显示,对于较低的 KL,模式坍塌更严重,而具有较高 KL 的模型更接近稳定 Diffusion 模型。请注意,正则化项的添加对于防止发生在最右侧列中的模式崩溃至关重要。

最后,图 5 显示了与基本稳定 Diffusion 模型相比,使用我们的 DRaFT+算法微调稳定 Diffusion 模型的几个例子。两个模型都使用相同的提示和初始种子来生成图像。使用 PickScore 奖励对 Pic-a-Pic 数据集提示进行微调。

总结
本文介绍了用于微调生成文本到图像 Diffusion 模型的 DRaFT+算法。该算法通过最大化从给定的可微分奖励模型产生的奖励来微调 Diffusion 过程。通过正则化项,我们的算法通过防止模式崩溃和增强图像生成的多样性来改进以前的方法。
要尝试 DRaFT+ 算法,请访问 NeMo Aligner 库,位于 GitHub 上的开源仓库。


