从制造汽车到帮助外科医生和送披萨,机器人不仅自动化,而且将人类任务的速度提高了许多倍。随着人工智能的出现,你可以建造更智能的机器人,它们可以更好地感知周围环境,并在最少的人工干预下做出决策。
例如,一个用于仓库的自动机器人将有效载荷从一个地方移动到另一个地方。它必须感知周围的自由空间,检测并避免路径中的任何障碍,并做出“即时”决定,毫不拖延地选择新路径。
这就是挑战所在。这意味着构建一个由人工智能模型支持的应用程序,该模型经过训练和优化,可以在这种环境下工作。它需要收集大量高质量的数据,并开发一个高度精确的人工智能模型来驱动应用程序。这些是将应用程序从实验室转移到生产环境的关键障碍。
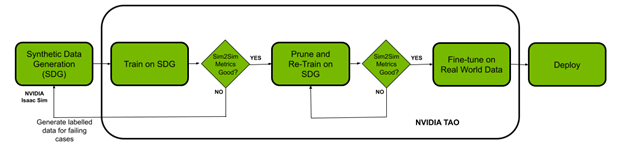
在这篇文章中,我们将展示如何使用 NVIDIA ISAAC 平台和 TAO 框架解决数据挑战和模型创建挑战。你使用 NVIDIA ISAAC Sim ,一个机器人模拟应用程序,用于创建虚拟环境和生成合成数据。这个 NVIDIA TAO 工具包 是一种低代码人工智能模型开发解决方案,与从头开始的训练相比,它具有内置的转移学习功能,可以用一小部分数据微调预训练模型。最后,使用 NVIDIA ISAAC ROS 将优化模型部署到机器人上,并将其应用于现实世界。
先决条件
开始之前,您必须拥有以下用于培训和部署的资源:
- NVIDIA GPU 驱动程序版本:> 470
- NVIDIA Docker: 2.5.0-1
- NVIDIA GPU 云端或内部:
- NVIDIA A100
- NVIDIA V100
- NVIDIA T4
- NVIDIA RTX 30 × 0 ( NVIDIA ISAAC 是也支持 NVIDIA RTX 20 系列)
- NVIDIA Jetson Xavier 或 Jetson Xavier NX
- NVIDIA TAO 工具包: 4.22 。有关更多信息,请参阅 TAO 工具包快速入门指南
- NVIDIA ISAAC Sim 和 ISAAC ROS
使用 NVIDIA ISAAC Sim 生成合成数据
在本节中,我们将概述在 NVIDIA ISAAC Sim 中生成合成数据的步骤。 Synthetic data 是计算机模拟或算法生成的注释信息。当真实数据难以获取或成本高昂时,合成数据可以帮助解决数据难题。
NVIDIA ISAAC Sim 提供三种生成合成数据的方法:
- 复制器作曲家
- Python 脚本
- GUI
在这个实验中,我们选择使用 Python 脚本生成具有领域随机化的数据。 Domain randomization 改变在模拟环境中定义场景的参数,包括场景中各种对象的位置、比例、模拟环境的照明、对象的颜色和纹理等。
添加域随机化以同时改变场景的多个参数,通过将其暴露于现实世界中看到的各种域参数,提高了数据集质量并增强了模型的性能。
在本例中,您使用两个环境来培训数据:一个仓库和一个小房间。接下来的步骤包括向场景中添加符合物理定律的对象。我们使用了 NVIDIA ISAAC Sim 卡中的示例对象,其中还包括 YCB dataset 中的日常对象。

安装 NVIDIA ISAAC Sim 卡后 ISAAC Sim 卡应用程序选择器 为包含python.sh脚本的 在文件夹中打开 提供一个选项。这用于运行用于生成数据的脚本。
按照列出的步骤生成数据。
选择环境并将摄影机添加到场景中
def add_camera_to_viewport(self): # Add a camera to the scene and attach it to the viewport self.camera_rig = UsdGeom.Xformable(create_prim("/Root/CameraRig", "Xform")) self.camera = create_prim("/Root/CameraRig/Camera", "Camera")
将语义 ID 添加到楼层:
def add_floor_semantics(self): # Get the floor from the stage and update its semantics stage = kit.context.get_stage() floor_prim = stage.GetPrimAtPath("/Root/Towel_Room01_floor_bottom_218") add_update_semantics(floor_prim, "floor")
在具有物理特性的场景中添加对象:
def load_single_asset(self, object_transform_path, object_path, usd_object): # Random x, y points for the position of the USD object translate_x , translate_y = 150 * random.random(), 150 * random.random() # Load the USD Object try: asset = create_prim(object_transform_path, "Xform", position=np.array([150 + translate_x, 175 + translate_y, -55]), orientation=euler_angles_to_quat(np.array([0, 0.0, 0]), usd_path=object_path) # Set the object with correct physics utils.setRigidBody(asset, "convexHull", False)
初始化域随机化组件:
def create_camera_randomization(self): # A range of values to move and rotate the camera camera_tranlsate_min_range, camera_translate_max_range = (100, 100, -58), (220, 220, -52) camera_rotate_min_range, camera_rotate_max_range = (80, 0, 0), (85, 0 ,360) # Create a Transformation DR Component for the Camera self.camera_transform = self.dr.commands.CreateTransformComponentCommand( prim_paths=[self.camera.GetPath()], translate_min_range=camera_tranlsate_min_range, translate_max_range=camera_translate_max_range, rotate_min_range=camera_rotate_min_range, rotate_max_range=camera_rotate_max_range, duration=0,5).do()
确保模拟中的摄影机位置和属性与真实世界的属性相似。为生成正确的自由空间分段掩码,需要向地板添加语义 ID 。如前所述,应用领域随机化来帮助提高模型的 sim2real 性能。
NVIDIA ISAAC Sim 文档中提供的 离线数据生成 示例是我们脚本的起点。对这个用例进行了更改,包括使用物理向场景添加对象、更新域随机化,以及向地板添加语义。我们已经为数据集生成了近 30000 张带有相应分割模板的图像。
使用 TAO 工具包进行培训、调整和优化
在本节中,您将使用 TAO 工具包使用生成的合成数据对模型进行微调。为了完成这项任务,我们选择了 NGC 提供的 UNET 模型进行实验。
!ngc registry model list nvidia/tao/pretrained_semantic_segmentation:*
设置数据、规格文件( TAO 规格)和实验目录:
%set_env KEY=tlt_encode %set_env GPU_INDEX=0 %set_env USER_EXPERIMENT_DIR=/workspace/experiments %set_env DATA_DOWNLOAD_DIR=/workspace/freespace_data %set_env SPECS_DIR=/workspace/specs
下一步是选择模型。
选择正确的预训练模型
预训练人工智能和深度学习模型是在代表性数据集上进行训练并使用权重和偏差进行微调的模型。与从头开始的训练相比,只需使用一小部分数据就可以应用迁移学习,您可以快速轻松地微调预训练模型。
在预训练模型领域中,有一些模型执行特定任务,比如检测人、汽车、车牌等。
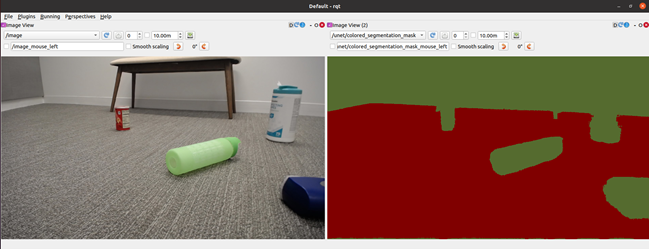
我们首先选择了一个带有 ResNet10 和 ResNet18 主干的 U-Net 型号。从模型中获得的结果显示,在真实数据中,墙和地板合并为一个实体,而不是两个单独的实体。即使模型在模拟图像上的性能显示出较高的精度,这也是事实。
| BackBone | Pruned | Dataset Size | Image Size | Training Evaluations | ||||
| Train | Val | F1 Score | mIoU (%) | Epochs | ||||
| RN10 | NO | 25K | 4.5K | 512×512 | 89.2 | 80.1 | 50 | |
| RN18 | NO | 25K | 4.5K | 512×512 | 91.1 | 83.0 | 50 | |
我们用不同的主干和图像大小进行实验,观察延迟( FPS )与准确性之间的权衡。表中所有型号均相同( UNET );只有脊柱不同。

根据结果,我们显然需要一个更适合用例的不同模型。我们选择了 NGC 目录中提供的 PeopleSemSeg 型号。该模型在“ person ”类的 500 万个对象上进行了预训练,数据集由相机高度、人群密度和视野( FOV )组成。该模型还可以将背景和自由空间分割为两个独立的实体。
在使用相同的数据集对该模型进行训练后,平均 IOU 增加了 10% 以上,得到的图像清楚地显示了地板和墙壁之间更好的分割。
| BackBone | Pruned | Dataset Size | Image Size | Training Evaluations | |||
| Train | Val | F1 Score | mIoU (%) | Epochs | |||
| PeopleSemSegNet | NO | 25K | 4.5K | 512×512 | 98.1 | 96.4 | 50 |
| PeopleSemSegNet | NO | 25K | 4.5K | 960×544 | 99.0 | 98.1 | 50 |

图 4 显示了在使用真实数据对 PeopleSeg 模型进行微调之前,从机器人的角度在模拟图像和真实图像上识别自由空间。也就是说,使用纯 NVIDIA ISAAC Sim 卡数据训练的模型。
关键的一点是,虽然可能有许多经过预训练的模型可以完成这项任务,但选择一个最接近当前应用程序的模型是很重要的。这就是陶的特制模型有用的地方。
!tao unet train --gpus=1 --gpu_index=$GPU_INDEX \ -e $SPECS_DIR/spec_vanilla_unet.txt \ -r $USER_EXPERIMENT_DIR/semseg_experiment_unpruned \ -m $USER_EXPERIMENT_DIR/peoplesemsegnet.tlt \ -n model_freespace \ -k $KEY
培训模型后,根据验证数据评估模型性能:
!tao unet evaluate --gpu_index=$GPU_INDEX -e$SPECS_DIR/spec_vanilla_unet.txt \ -m $USER_EXPERIMENT_DIR/semseg_experiment_unpruned/weights/model_freespace.tlt \ -o $USER_EXPERIMENT_DIR/semseg_experiment_unpruned/ \ -k $KEY
当您对 NVIDIA ISAAC Sim 数据的模型性能和 Sim2Sim 验证性能感到满意时,请删减模型。
要以最小的延迟运行此模型,请将其优化为在目标 GPU 上运行。有两种方法可以实现这一点:
- Pruning : TAO 工具包中的修剪功能会自动删除不需要的层和神经元,有效地减小模型的大小。必须重新训练模型,以恢复修剪过程中丢失的精度。
- Post-training quantization : TAO 工具包中的另一项功能可以进一步缩小模型尺寸。这将其精度从 FP32 更改为 INT8 ,在不牺牲精度的情况下提高了性能。
首先,删减模型:
!tao unet prune \ -e $SPECS_DIR/spec_vanilla_unet.txt \ -m $USER_EXPERIMENT_DIR/semseg_experiment_unpruned/weights/model_freespace.tlt \ -o $USER_EXPERIMENT_DIR/unet_experiment_pruned/model_unet_pruned.tlt \ -eq union \ -pth 0.1 \ -k $KEY
重新训练并修剪模型:
!tao unet train --gpus=1 --gpu_index=$GPU_INDEX \ -e $SPECS_DIR/spec_vanilla_unet_retrain.txt \ -r $USER_EXPERIMENT_DIR/unet_experiment_retrain \ -m $USER_EXPERIMENT_DIR/unet_experiment_pruned/model_unet_pruned.tlt \ -n model_unet_retrained \ -k $KEY
当您对修剪模型的 Sim2Sim 验证性能感到满意时,请转至下一步,对真实数据进行微调。
!tao unet train --gpus=1 --gpu_index=$GPU_INDEX \ -e $SPECS_DIR/spec_vanilla_unet_domain_adpt.txt \ -r $USER_EXPERIMENT_DIR/semseg_experiment_domain_adpt \ -m $USER_EXPERIMENT_DIR/semseg_experiment_retrain/model_unet_pruned.tlt\ -n model_domain_adapt \ -k $KEY
后果
表 1 显示了未运行和修剪模型之间的结果摘要。最终选择用于部署的经过修剪和量化的模型比在 NVIDIA Jetson Xavier NX 上测量的原始模型小 17 倍,推理性能快 5 倍。
| Model | Dataset | Training Evaluations | Inference Performance | ||||
| Pruned | Fine-Tune on Real World Data |
Training Set | Validation Set | F1 Score (%) | mIoU (%) | Precision | FPS |
| NO | NO | Sim | Sim | 0.990 | 0.981 | FP16 | 3.9 |
| YES | NO | Sim | Sim | 0.991 | 0.982 | FP16 | 15.29 |
| YES | NO | Sim | Real | 0.680 | 0.515 | FP16 | 15.29 |
| YES | YES | Real | Real | 0.979 | 0.960 | FP16 | 15.29 |
| YES | YES | Real | Real | 0.974 | 0.959 | INT8 | 20.25 |
sim 数据的训练数据集由 25K 个图像组成,而用于微调的真实图像的训练数据仅由 44 个图像组成。真实图像的验证数据集仅包含 56 幅图像。对于真实世界的数据,我们收集了三种不同室内场景的数据集。模型的输入图像大小为 960 × 544 。推理性能是使用 NVIDIA TensorRT trtexec 工具 .

部署 NVIDIA ISAAC ROS
在本节中,我们展示了采用经过训练和优化的模型并使用 NVIDIA ISAAC ROS 在 Xavier Jetson NX 驱动的 iRobot 的 Create 3 机器人上进行部署的步骤。 Create 3 和 NVIDIA ISAAC ROS 图像分割节点均在 ROS2 上运行。
本例使用 /isaac_ros_image_segmentation/isaac_ros_unet GitHub repo 部署空闲空间分段。
要使用自由空间分段模型,请从 /NVIDIA-ISAAC-ROS/isaac_ros_image_segmentation GitHub repo 执行以下步骤。
创建 Docker 交互式工作区:
$isaac_ros_common/scripts/run_dev.sh your_ws
克隆所有包依赖项:
isaac_ros_dnn_encodersisaac_ros_nvengine_interfaces- 推理包(您可以选择其中一个)
isaac_ros_tensor_rtisaac_ros_triton
构建并获取工作区的源代码:
$cd /workspaces/isaac_ros-dev $colcon build && . install/setup.bash
从您的工作机器下载经过培训的自由空间标识(. etlt )模型:
$scp <your_machine_ip>:<etlt_model_file_path> <ros2_ws_path>
将加密的 TLT 模型(. etlt )和格式转换为 TensorRT 引擎计划。对 INT8 模型运行以下命令:
tao converter -k tlt_encode \ -e trt.fp16.freespace.engine \ -p input_1,1x3x544x960,1x3x544x960,1x3x544x960 \ unet_freespace.etlt
按照以下步骤进行演练: ISAAC ROS 图像分割 :
- 将 TensorRT 模型引擎文件保存在正确的目录中。
- 创建
config.pbtxt. - 更新
isaac_ros_unet启动文件中的模型引擎路径和名称。 - 重新生成并运行以下命令:
$ colcon build --packages-up-to isaac_ros_unet && . install/setup.bash $ ros2 launch isaac_ros_unet isaac_ros_unet_triton.launch.py
总结
在本文中,我们向您展示了一个端到端的工作流程,首先是在 NVIDIA ISAAC Sim 中生成合成数据,使用 TAO 工具包进行微调,然后使用 NVIDIA ISAAC ROS 部署模型。
NVIDIA ISAAC Sim 和 TAO Toolkit 都是抽象出人工智能框架复杂性的解决方案,使您能够在生产中构建和部署人工智能驱动的机器人应用程序,而无需任何人工智能专业知识。
通过拉动 /NVIDIA-AI-IOT/robot_freespace_seg_Isaac_TAO GitHub 项目开始这个实验。