在本文中,我们将深入探讨推理优化过程,以在推理阶段提高机器学习模型的性能和效率。我们将讨论所采用的技术,例如推理计算图形简化、量化和降低精度。我们还展示了场景文本检测和识别模型的基准测试结果,其中比较了 ONNX 运行时 和 NVIDIA TensorRT 使用 NVIDIA Triton 推理服务器。
最后,我们总结了优化深度学习模型对于推理的重要性,以及使用端到端 NVIDIA 软件解决方案的优势,NVIDIA AI Enterprise 用于构建高效可靠的场景文本 OCR 系统。
在本系列的第一篇文章中,强大的场景文本检测和识别:简介 讨论了稳健场景文本检测和识别(STDR)在各行各业中的重要性以及所面临的挑战。第二篇博文 强大的场景文本检测和识别:实施 并讨论了如何使用先进的深度学习算法和技术(如增量学习和微调)实现 STDR 工作流。
推理优化
推理优化旨在提高推理阶段机器学习模型的性能和效率。它有助于减少作出预测所需的时间、计算资源和成本,在某些情况下还可以提高准确性。
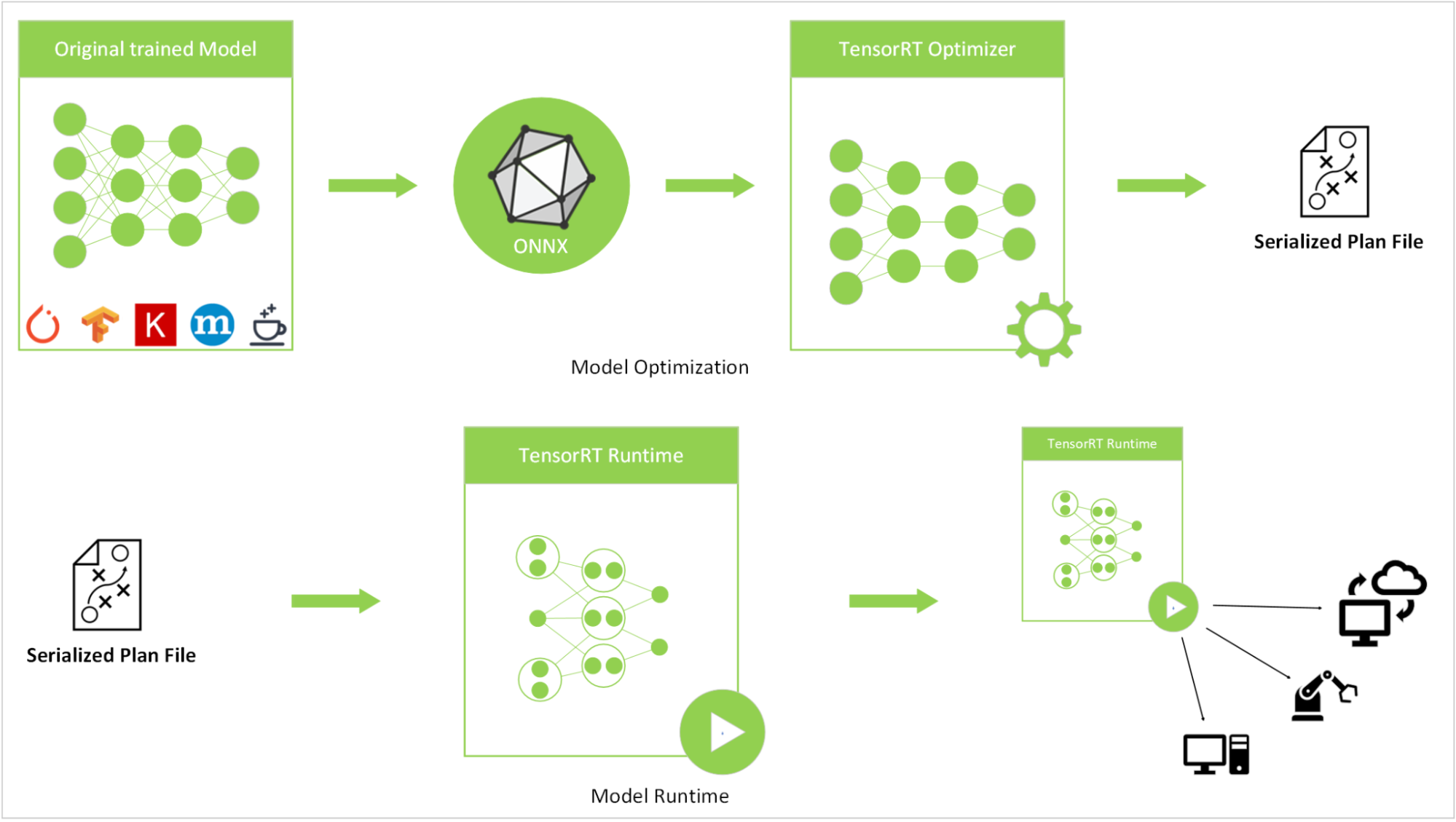
我们通过使用推理计算图形简化、量化和降低精度等技术来优化推理性能。这些模型最初使用 PyTorch 库进行训练,随后导出为 torchScript 格式,再转换为ONNX格式,最终转换为NVIDIA TensorRT引擎。
为了执行 ONNX 到 TensorRT 的转换,我们使用了 TensorRT 版本 22.07 的 NGC 容器镜像。转换过程结束后,我们使用 NVIDIA Triton 推理服务器版本 22.07 部署了推理模型。系统性能在具有 16 GB GPU 显存的 NVIDIA A5000 笔记本电脑 GPU 上进行了基准测试。
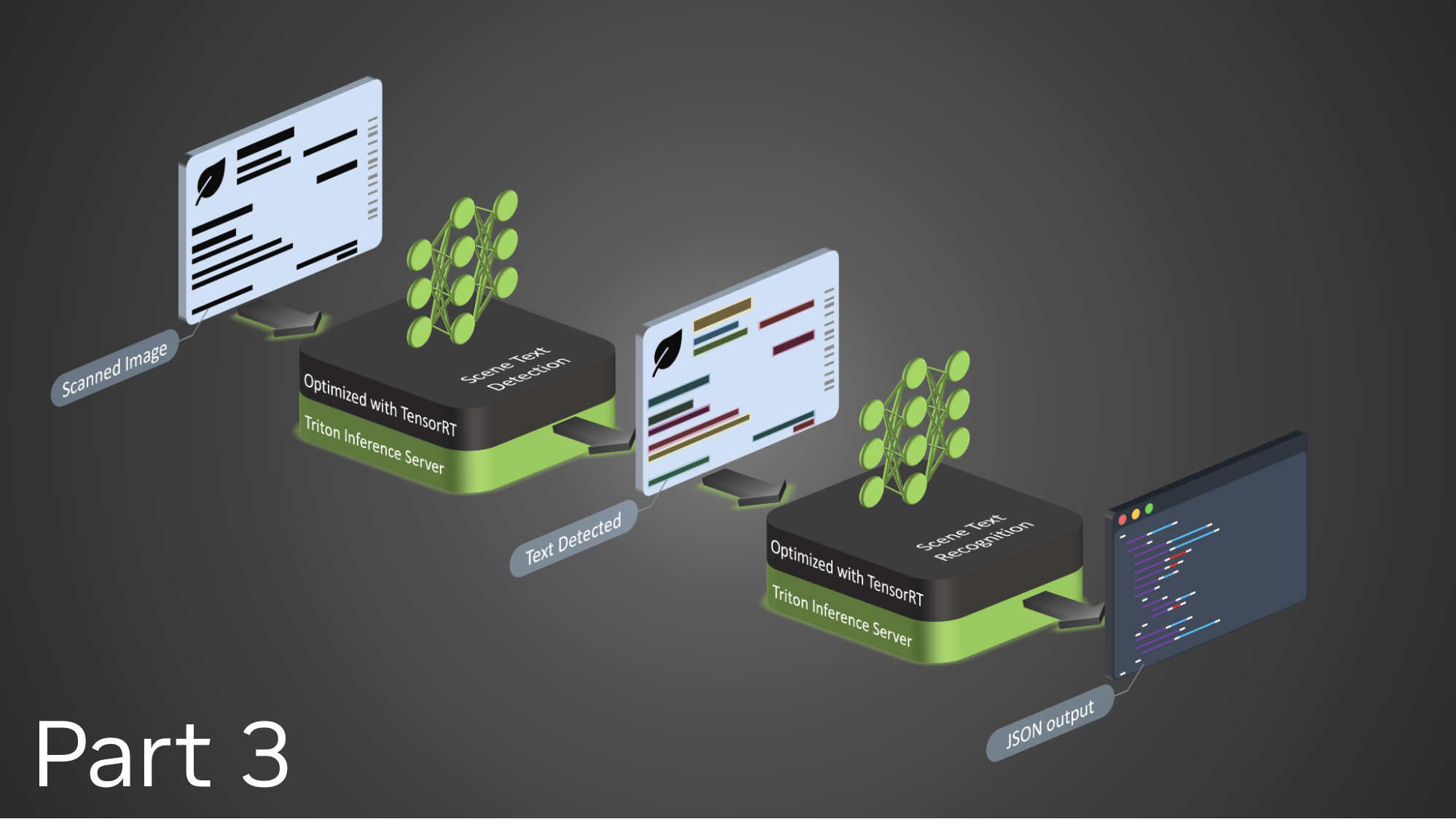
我们稍后将讨论场景文本检测和识别 (STDR) 每个构建块的优化细节。
场景文本检测
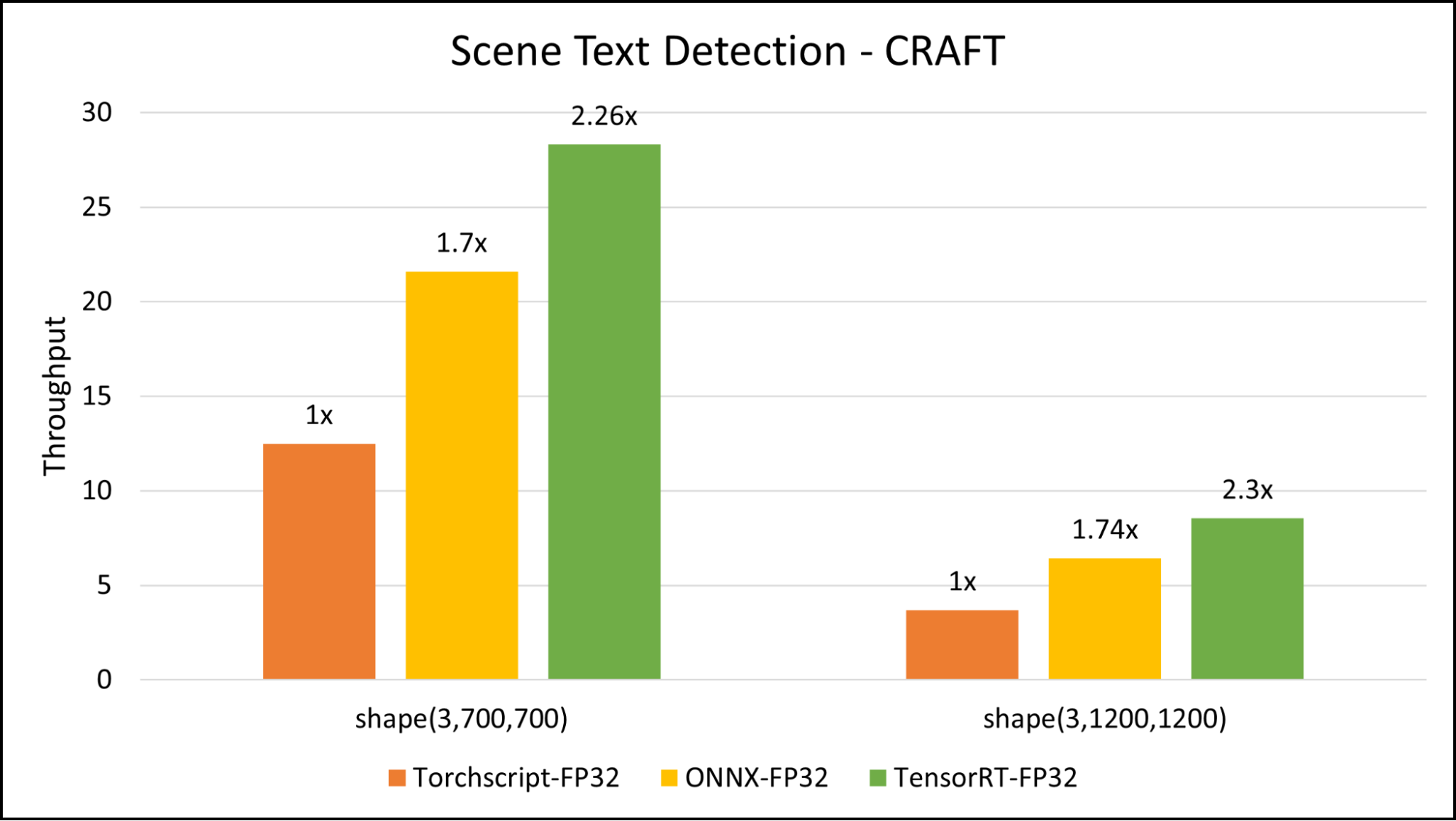
场景文本检测是场景文本 OCR 系统的一个重要组件。此组件将场景图像作为输入,并输出图像中文本字段位置。在本文中,我们将预训练的 CRAFT 模型用于常规场景文本检测任务。该模型基于一组不同的图像进行训练,能够处理动态输入图像并准确定位文本字段。在我们的部署中,用作输入的图像的平均宽度约为 720 点。在此处,我们对两种图像输入大小进行了基准测试:(3720,720) 和 (31200,1200).
我们的基准测试表明,与用于推理的 TorchScript 相比,TensorRT 的速度提高了大约 2.3 倍。
部署的 CRAFT 模型是具有 FP32 精度的 TensorRT 引擎。以下代码示例是快速转换指南。
创建 conda 环境:
$ conda create –n <your_env_name> python=3.8$ conda activate <your_env_name> |
克隆 CRAFT 库并安装 requirement.txt:
$ git clone https://github.com/clovaai/CRAFT-pytorch.git$ cd CRAFT-pytorch$ pip install –r requirement.txt |
加载模型并将其转换为可呈现动态形状的 .onnx 格式:
input_tensor_detec = torch.randn((1, 3, 768, 768), requires_grad=False)input_tensor_detec=input_tensor_detec.to(device="cuda”)# Load netnet = CRAFT()net.load_state_dict(copyStateDict(torch.load(model_path)))net = net.cuda()net.eval()# Convert the model into ONNXtorch.onnx.export(net, input_tensor_detec, output_dir, verbose=False, opset_version=11, do_constant_folding= True, export_params=True, input_names=["input"], output_names=["output", "output1"], dynamic_axes={"input": {0: "batch", 2: "height", 3: "width"}}) |
简化 ONNX 计算图。通过ONNX Simplifier来简化 ONNX 模型。它能够推理整个计算图,并将多余的运算符替换为它们的常量输出(这一过程也被称为常量折叠)。以下代码示例展示了如何使用操作折叠来简化 CRAFT 模型的计算图:
$ onnxsim <path to non_simplified onnx model> <path to simplified onnx model> |
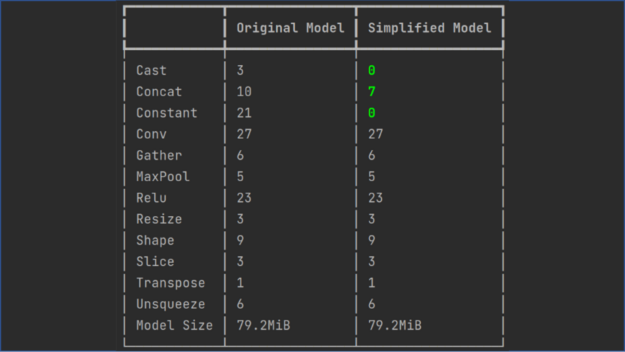
在本文中,使用 NVIDIA TensorRT 预配置的 Docker 容器将 ONNX 模型转换为 TensorRT 序列化计划文件。以下代码示例适用于 tensorrt:22.07-py3 NGC 容器:
~$ docker run -it --gpus all -v <path to onnx model>:/models \nvcr.io/nvidia/tensorrt:22.07-py3root@576df0ec3a49:/workspace#$ trtexec --onnx=/models/craft.onnx \--explicitBatch --workspace=5000 --minShapes=input:1x3x256x256 \--optShapes=input:1x3x700x700 --maxShapes=input:1x3x1200x1200 \--buildOnly –saveEngine=/models/craft.engine |
以下代码示例显示了场景文本检测模型的 config.pbtxt 文件:
name: "craft"default_model_filename: "detec_trt.engine"platform: "tensorrt_plan"max_batch_size : 1input [ { name: "input" data_type: TYPE_FP32 dims: [ 3, -1, -1 ] }]output [ { name: "output" data_type: TYPE_FP32 dims: [ -1, -1, 2 ] }, { name: "output1" data_type: TYPE_FP32 dims: [ 32, -1, -1 ] }] |
场景文本识别
场景文本识别是 STDR 流程的一个不可或缺的模块。我们使用了 PARseq 算法,这是一种先进的技术,可实现高效且可定制的文本识别,以获得准确的结果。
为了更大限度地提高流程性能,我们将 PARseq TorchScript 模型转换为 ONNX,然后进一步将其转换为 TensorRT 引擎,确保文本识别的低延迟,因为每个图像可能包含多个文本字段。
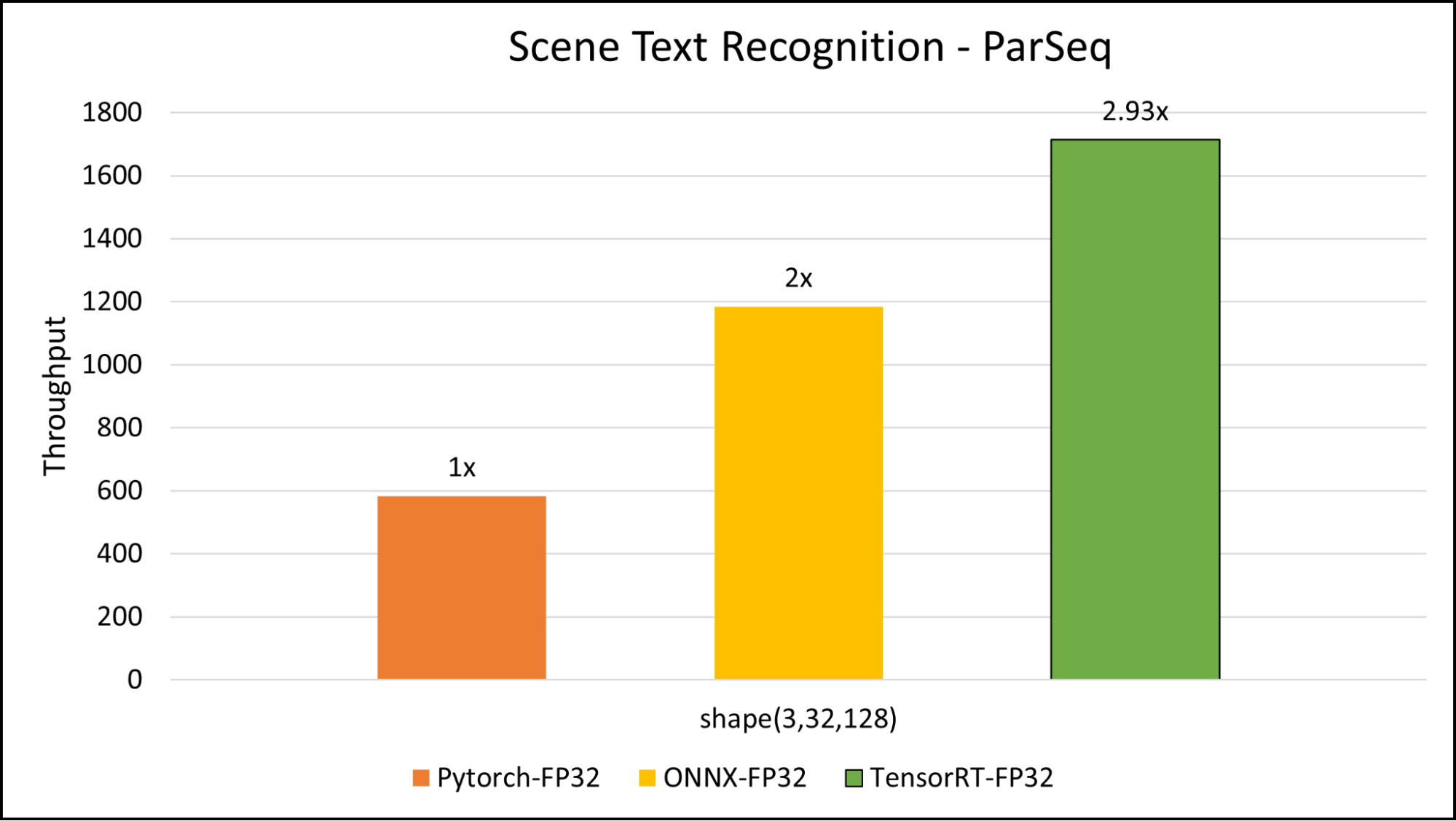
我们发现,事实证明,为模型使用 3x32x128 的输入大小是推理时间和准确性之间的最佳平衡。图 4 显示了 PARseq 模型的基准测试结果。与 TorchScript 推理相比,我们的基准测试加速约为原来的 3 倍。
我们发现预训练模型的作者发布的大多数案例都能很好地处理。如果您希望在自定义数据集上获得更准确的输出,您也可以对模型进行微调。以下代码示例展示了进行这些重要转换步骤的方法。
安装 PARSeq:
$ git clone https://github.com/baudm/parseq.git$ pip install -r requirements.txt$ pip install -e . |
您可以使用自己的微调模型或预训练模型,从 模型库 中获取,并将其转换为 .onnx 格式。请使用 ONNX 1.12.0 以下的版本。
from strhub.models.utils import load_from_checkpoint# To ONNXdevice = "cuda"ckpt_path = "..."onnx_path = "..."img = ...parseq = load_from_checkpoint(ckpt_path)parseq.refine_iters = 0parseq.decode_ar = Falseparseq = parseq.to(device).eval()parseq.to_onnx(onnx_path, img, do_constant_folding=True, opset_version=14) # opset v14 or newer is required# checkonnx_model = onnx.load(onnx_path)onnx.checker.check_model(onnx_model, full_check=True) ==> pass |
要转换为 TensorRT 格式,请使用ONNX Simplifier:
$ onnxsim <path to non_simplified onnx model> <path to simplified onnx model> |
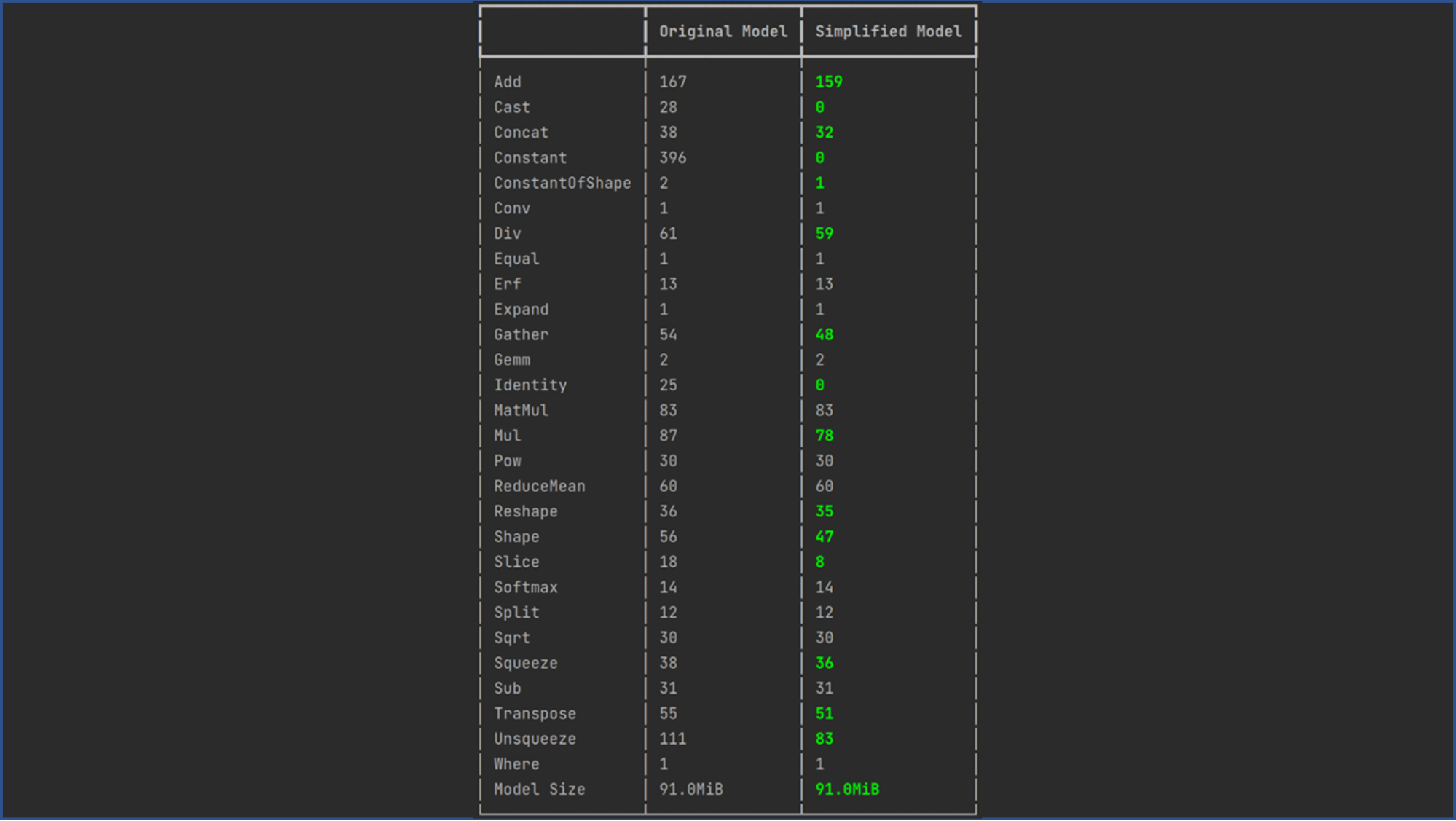
在将模型转换为简化的 ONNX 格式后,可以使用 trtexec 转换工具进行进一步处理。此转换过程可在 TensorRT 容器版本 22.07 中完成。
~$ docker run -it --gpus all -v <path to onnx model repository>:/models nvcr.io/nvidia/tensorrt:22.07-py3root@576df0ec3a49:/workspace# trtexec --onnx=/models/parseq_simple.onnx --fp16 \--workspace=1024 --saveEngine=/models/parseq_fp16.trt --minShapes=input:1x3x32x128 \--optShapes=input:4x3x32x128 --maxShapes=input:16x3x32x128 |
以下代码示例展示了config.pbtxt场景文本识别模型的文件:
name: "parseq"max_batch_size: 16platform: "tensorrt_plan"default_model_filename: "parseq_exp_fp32.trt" input { name: "input" data_type: TYPE_FP32 dims: [3, 32, 128]} output { name: "output" data_type: TYPE_FP32 dims: [26, 95]} instance_group [ { count: 1 kind: KIND_GPU }] |
编排师
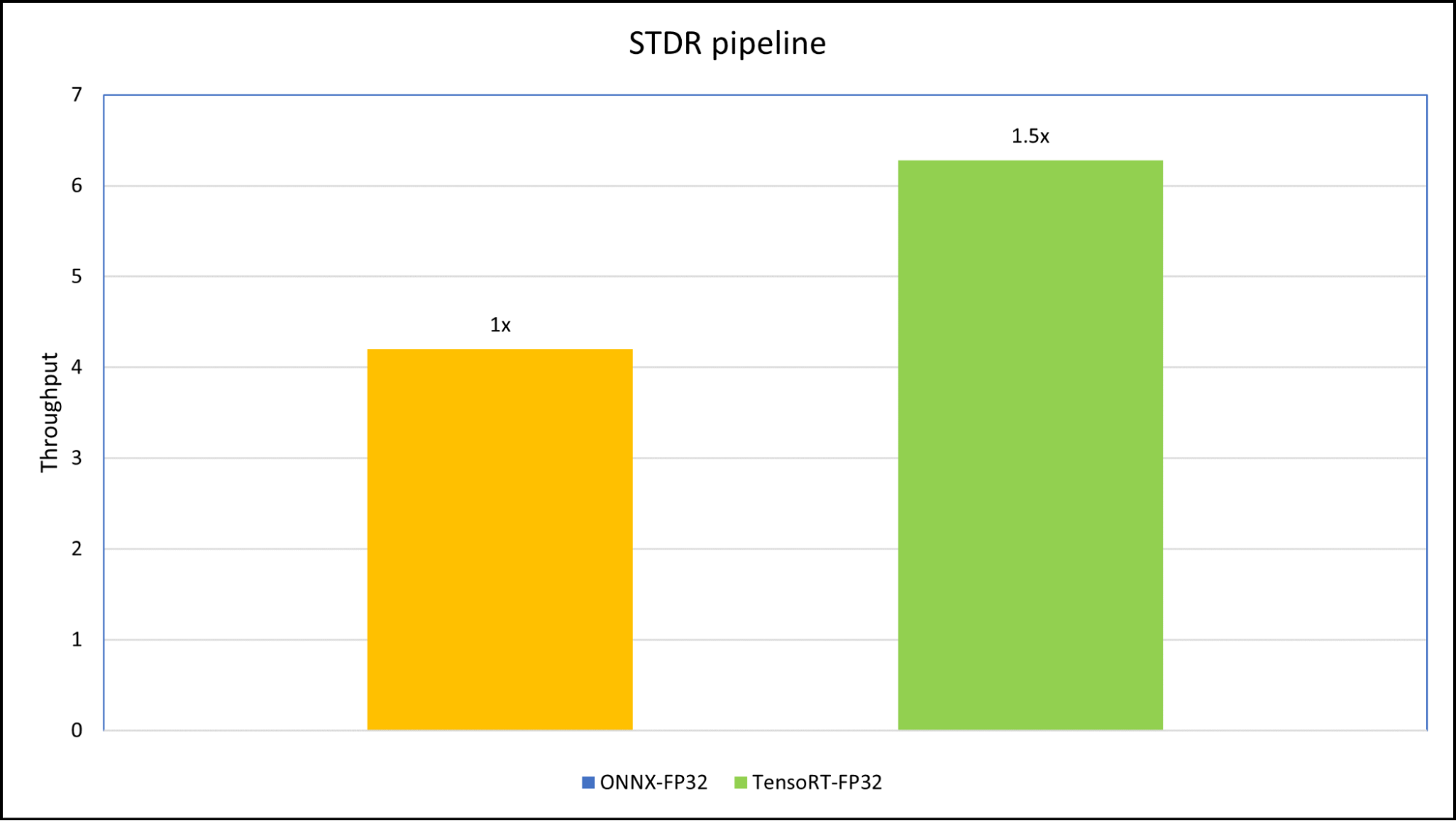
编排器模块是一个用于维护流程并对 STDR 管线执行预处理的Python 后端。为了进行管线基准测试,我们使用了 4 张具有不同图像尺寸的图像,以便于perf_analyzer的使用。
我们创建了两个版本的工作流,一个使用 ONNX 运行时 CPU/GPU 后端的工作流,另一个使用 TensorRT 计划,以便工作流可在 GPU 和非 GPU 环境中运行。我们对工作流进行了基准测试,onnx_backend管道和tensorrt_plan使用 NVIDIA Triton 推理服务器的 NVIDIA RTX A5000 笔记本电脑 GPU (16 GB) 上的工作流。
基准测试的输入样本具有四种不同的图像,大小为 (3x472x338)、(3x3280x2625)、(3x512x413) 和 (3x1600x1200).
编排器是一个 Python 后端模块,用于协调场景文本检测和场景文本识别模型。编排器的配置文件如下所示:
name: "pipeline"backend: "python"max_batch_size: 1input [ { name: "input" data_type: TYPE_UINT8 dims: [ -1, -1, 3 ] }]output [ { name: "output" data_type: TYPE_STRING dims: [ -1 ] }] instance_group [ { count: 1 kind: KIND_GPU }] |
总结
总而言之,部署场景文本检测和识别系统需要仔细考虑真实场景,优化深度学习模型以进行推理至关重要。
为确保生产就绪型优化和性能, NVIDIA 提供了端到端软件解决方案 NVIDIA AI Enterprise,该解决方案由一流的 AI 软件和工具(包括 TensorRT 和 Triton 推理服务器)组成,可轻松访问构建企业 AI 应用程序。该解决方案有助于在各种设备上实现低延迟和高性能推理。
通过使用这些技术,您可以为各种应用构建高效可靠的场景文本 OCR 系统。