Accuracy is one of the most important metrics for deep learning models. Greater accuracy is a prerequisite for deploying the trained models to production to solve real-world problems reliably and effectively. Creating highly accurate models from scratch is time-consuming and capital-intensive. As a result, companies with limited data and resources struggle to get their AI solutions to market.

Applying transfer learning techniques helps you create new AI models faster by fine-tuning previously trained neural networks. NVIDIA TAO Toolkit lets you take your own custom dataset and fine-tune it with one of the many popular network architectures to produce a task-specific model. Or you can get on the fast track with readily available, production-quality models for use cases in smart city, retail, robotics, and more. TAO Toolkit simplifies the process of training accurate AI models and optimizing it for inference performance, using techniques like model pruning and quantization.
With TAO Toolkit, you can achieve state-of-the-art accuracy using public datasets while maintaining high inference throughput for deployment. This post shows you how to train object detection and image classification models using TAO Toolkit to achieve the same accuracy as in the literature and open-sourced implementations. We trained on public datasets such as ImageNet, PASCAL VOC, and MS COCO as a comparison with published results in the literature or open-source community. This post discusses the complete workflow to reach state-of-the-art accuracy on several popular model architectures.
This post has three main sections. First, we show you how to prepare the required datasets for classification and object detection. Then, you train classification models on the ImageNet dataset using the VGG16, ResNet50, ResNet101, and EfficientNet B0 networks. TAO Toolkit supports over 15 classification models or backbones and you can use the technique from this post to train other models as well. After you have the ImageNet-based classification model, you then use the pretrained weights from the ImageNet-trained models to train Faster R-CNN, SSD, RetinaNet, and YoloV3 object detection models. The scripts and TAO Toolkit training spec files are available in the tao3.0/misc/dev_blog/SOTA GitHub repo.
Pretrained weights trained on the ImageNet dataset tend to provide good accuracy for object detection. The following graph shows the state-of-the-art accuracy of several top models. In this post, we show the steps to achieve this accuracy with TAO Toolkit. After you achieve the desired accuracy, you can use the model pruning and INT8 quantization features in TAO Toolkit to improve inference performance.
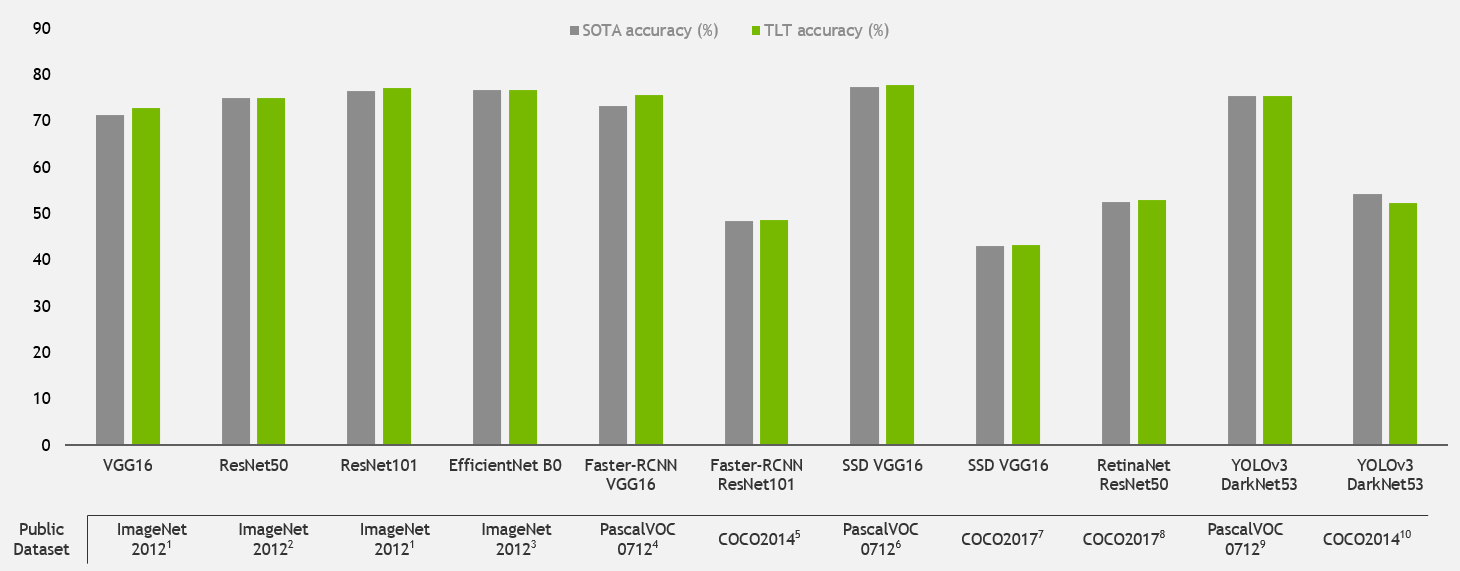
Sources:
- https://keras.io/api/applications
- https://keras.io/api/applications. The ResNet backbones used in TAO Toolkit RetinaNet are slightly different from the Keras model. To train a ResNet model compatible with RetinaNet,
all_projectionsshould be set toTrueanduse_poolingtoFalse(example). - https://github.com/tensorflow/tpu/tree/r2.4/models/official/efficientnet
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (table 6).
- Deep Residual Learning for Image Recognition (table 9).
- SSD: Single Shot MultiBox Detector.
- GLUON Model Zoo Detection: SSD.
- Focal Loss for Dense Object Detection (Table 1(b) (c)).
- YOLO: Real-Time Object Detection; Darknet (codebase).
- yolov3.weights (evaluation mode is AP50 using 11-points sample, evaluation dataset is the COCO14 validation split previously mentioned)
Preparing the datasets
Here’s how to prepare the required datasets for classification and detection.
Prepare the ImageNet 2012 dataset
Start by downloading the ImageNet classification dataset (choose Download Original Images), which contains more than 140 GB of images. There are two tarballs to download and save to the same directory:
ILSVRC2012_img_train.tar(138 GB)—Used for training.ILSVRC2012_img_val.tar(6.3 GB) —Used for validation.
After the dataset has been downloaded, use the imagenet.py Python script and the imagenet_val_maps.pklz validation map file to unzip the two tarballs and restructure the validation dataset. Due to copyright issues, we can’t provide the ImageNet dataset or any ImageNet-pretrained models in TAO Toolkit. Use the following command to unzip and restructure the dataset:
python3.6 imagenet.py --download-dir <tarballs_download_directory> --target_dir <unzip_target_dir>
Assume that the paths from inside the TAO Toolkit container to the dataset are as follows:
/home/<username>/tao-experiments/data/imagenet2012/train /home/<username>/tao-experiments/data/imagenet2012/val
The first path is a directory that contains all the training images, where each of the 1K classes has its own subdirectory. The same is assumed for the validation split as well. The structure of the classification dataset follows the TAO Toolkit classification model training requirements. For more information, see the TAO Toolkit User Guide.
Prepare the PASCAL VOC dataset
PASCAL VOC is a public dataset. Download the VOC2007 and VOC2012 datasets from the official website. Use the download_pascal_voc.sh bash script to download and split the PASCAL VOC dataset.
Finally, convert the XML labels to KITTI because XML is not supported by TAO Toolkit. The xml_to_kitti.py Python script handles this conversion.
# convert labels to KITTI format mkdir -p /home/<username>/tao-experiments/data/voc0712trainval/labels_kitti mkdir -p /home/<username>/tao-experiments/data/voc07test/labels_kitti python ./xml_to_kitti.py -i /home/<username>/tao-experiments/data/voc0712trainval/labels -o /home/<username>/tao-experiments/data/voc0712trainval/labels_kitti python ./xml_to_kitti.py -i /home/<username>/tao-experiments/data/voc07test/labels -o /home/<username>/tao-experiments/data/voc07test/labels_kitti -d
Now that the dataset is ready, run TAO Toolkit. You are using TAO Toolkit through the tao-launcher interface. When running the tao-launcher, map the ~/tao-experiments directory on the local machine to the Docker container using the ~/.tao_mounts.json file. For more information, see TAO Toolkit Launcher.
Install tao-launcher:
!pip3 install nvidia-pyindex !pip3 install nvidia-tao
Create ~/.tao_mounts.json and add the following content:
{
"Mounts": [
{
"source": "/home/<username>/tao-experiments",
"destination": "/workspace/tao-experiments"
},
]
}
Mount the path /home/<username>/tao-experiments on the host machine to be the path /workspace/tao-experiments inside the container.
Prepare the COCO 2014 and COCO 2017 datasets
Download the COCO 2014 and 2017 datasets from the COCO website. For COCO 2014, download the following files:
train2014.zipval2014.zipannotations_trainval2014.zip
For COCO 2017, download the following files:
train2017.zipval2017.zipannotations_trainval2017.zip
The COCO 2014 dataset contains 80 different classes, with roughly 80K images for training and 40K images for validation. The COCO 2017 dataset also contains 80 different classes from COCO 2014, but the dataset split is different. In the COCO 2017, you have around 118K images for training and 5K images for validation. Download the COCO 2014 or 2017 dataset with the following commands.
# create a directory to place the dataset
mkdir -p /home/<username>/tao-experiments/data/coco{$year}
cd /home/<username>/tao-experiments/data/coco{$year}
# training images
wget http://images.cocodataset.org/zips/train{$year}.zip
# validation images
wget http://images.cocodataset.org/zips/val{$year}.zip
# train/val annotations
wget http://images.cocodataset.org/annotations/annotations_trainval{$year}.zip
After downloading, you must do some processing for the COCO 2014 and COCO 2017 datasets to convert the original JSON format to KITTI format.
Unzip the dataset:
cd /home/<username>/tao-experiments/data/coco{$year}
# unzip images
unzip train{$year}.zip
unzip val{$year}.zip
# create a directory for the images
mkdir images
mv train{$year} images
mv val{$year} images
# unzip annotations
unzip annotations_trainval{$year}.zip
To convert the JSON labels to the KITTI format, use the coco2kitti.py Python script. This script depends on the pycocotools package. Check the GitHub repository and install it properly. Run the following commands:
cd /home/<username>/tao-experiments/data/coco{$year}
# the script is named coco2kitti.py
# convert the instances_train{$year}.json to KITTI text
python3 ./coco2kitti.py /home/<username>/tao-experiments/data/coco{$year} train{$year}
# move the output ./labels to a safe place to avoid overwriting
mkdir -p ./KITTI
mv ./labels KITTI/train{$year}
# continue to convert the instances_val{$year}.json to KITTI text
python3 ./coco2kitti.py /home/<username>/tao-experiments/data/coco{$year} val{$year}
# move and rename the output
mkdir -p ./KITTI
mv ./labels KITTI/val{$year}
The KITTI dataset is not perfect, as there are some unpaired images and labels. Fortunately, there are just a few of these problematic images and labels so you can remove them. Use the clean_dataset.sh bash script to clean the dataset.
Copy the script to the /home/<username>/tao-experiments/data/coco{$year} directory:
cd /home/<username>/tao-experiments/data/coco{$year}
./clean_dataset.sh ./images/train{$year} ./KITTI/train{$year}
./clean_dataset.sh ./images/val{$year} ./KITTI/val{$year}
Training classification models on ImageNet 2012
In this section, you train three classification models (VGG16, ResNet101, and EfficientNet B0) on the ImageNet 2012 classification dataset. The ImageNet classification dataset contains more than 1.1 million images over 1000 classes. By pretraining weights on ImageNet, you can get high accuracy on object detection tasks by using this pretrained classification model to initialize the detection models.
Configure the classification training with a spec file
For every TAO Toolkit model training, you have a configuration file (spec file) to configure some necessary parameters used to customize the model and the training process. For more information, see the TAO Toolkit User Guide.
Download the spec files:
Perform image classification and train with TAO Toolkit
After you have the spec files, start the training. Because ImageNet is a big dataset, we recommend using multiple GPUs to reduce training time. For this post, we used a DGX-1v workstation with eight V100 GPUs, where each GPU has 32 GB memory. However, you can also use a single GPU. In the following commands, change the --gpus option value from 8 to the number of GPUs being used.
Run the following command for VGG16 training:
$tao classification train -e /workspace/tao-experiments/classification/vgg16/spec.txt -r /workspace/tao-experiments/classification/vgg16 -k nvidia_tao --gpus 8
Run the following command for ResNet50 training:
$tao classification train -e /workspace/tao-experiments/classification/resnet50/spec.txt -r /workspace/tao-experiments/classification/resnet50 -k nvidia_tao --gpus 8
Run the following command for ResNet101 training:
$tao classification train -e /workspace/tao-experiments/classification/resnet101/spec.txt -r /workspace/tao-experiments/classification/resnet101 -k nvidia_tao --gpus 8
Run the following command for EfficientNet B0 training:
$tao classification train -e /workspace/tao-experiments/classification/efficientnet_b0/spec.txt -r /workspace/tao-experiments/classification/efficientnet_b0 -k nvidia_tao --gpus 8 --use_amp
Run the following command for DarkNet53 training:
$tao classification train -e /workspace/tao-experiments/classification/darknet53/spec.txt -r /workspace/tao-experiments/classification/darknet53 -k nvidia_tao --gpus 8 --use_amp
Perform the post-training accuracy check
After the training is finished, check the log to see the accuracy. You trained VGG16 for 80 epochs, ResNet50 for 120 epochs, ResNet101 for 150 epochs, and EfficientNetB0 for 500 epochs.
Compare the validation accuracy from the model with the open-source networks from Keras Applications, TensorFlow EfficientNet GitHub pages, and the DarkNet ImageNet Classification page. The accuracy results are summarized in the following table. With TAO Toolkit, you can get an even better top-1 accuracy than Keras Applications. You can export the trained model and use it for image classification tasks or use the pretrained weights to train object detection models.
| Model | SOTA accuracy | TAO Toolkit accuracy |
| VGG16 | 71.3 | 72.8 |
| ResNet50 | 74.9 | 74.9 |
| ResNet101 | 76.4 | 76.98 |
| EfficientNet B0 | 76.7 | 76.64 |
| DarkNet53 | 77.2 | 77.1 |
Train object detection models on PASCAL VOC and COCO datasets
In this post, you use ImageNet-pretrained weights trained in the prior section as a starting point to train popular object detection models such as Faster R-CNN, SSD, YoloV4, and RetinaNet. We show you how to train the models on the PASCAL VOC and COCO datasets. For each model, we summarize with the TAO Toolkit model accuracy compared to results from the leading literature.
Training Faster R-CNN models
After you have the pretrained models from the first section, use the weights as starting points to train your Faster R-CNN models. In this section, we show how to train a Faster R-CNN model with VGG16 and ResNet101 backbones. You train on the PASCAL VOC dataset for Faster R-CNN – VGG16 model and COCO 2014 for the Faster R-CNN – ResNet101 model.
Train on PASCAL VOC2007 and VOC2012
In this section, you use the PASCAL VOC2007 and VOC2012 datasets and test on the VOC2007 test dataset. Because you are using the VOC07 test set, stick to the convention of using 11-point metric and ignoring difficult objects when you calculate the average precision (AP) metric. For this PASCAL VOC training, you use VGG16 as backbone and use the ImageNet-pretrained VGG16 classification model from the previous section as the pretrained weights.
Convert KITTI text labels to TFRecords
Before the training, you must convert the KITTI text labels to TFRecords using the dataset-convert tool provided by TAO Toolkit. You use a spec file to configure parameters. Download two versions of the dataset_spec file for training/validation and testing. This command takes the KITTI text labels and a dataset spec file as input and produces TFRecords as output. Use the TFRecords as the label files for training the Faster R-CNN model.
Run the following command to generate TFRecords from KITTI text labels:
# trainval0712 tao faster_rcnn dataset_convert --gpu_index 0 -d /workspace/tao-experiments/data/voc0712trainval/dataset_spec.txt -o /workspace/tao-experiments/data/voc0712trainval/tfrecords # test07 tao faster_rcnn dataset_convert --gpu_index 0 -d /workspace/tao-experiments/data/voc07test/dataset_spec.txt -o /workspace/tao-experiments/data/voc07test/tfrecords
Train
After you produce the TFRecords format, use TAO Toolkit commands to launch a Faster R-CNN training job. Like the classification models, we need a training spec file for Faster R-CNN too. We provided the training spec file.
After you have the training spec file, you are ready to run TAO Toolkit training with a single GPU (we used a V100 32-GB in our experiment).
tao faster_rcnn train --gpu_index 0 -e /workspace/tao-experiments/faster_rcnn/pascal_voc/spec.txt
Validate
After the training is finished, check the screen log to see the validation mAP.
========================================================================================== Class AP precision recall RPN_recall ------------------------------------------------------------------------------------------ aeroplane 0.7521 0.0229 0.9228 0.8907 ... tvmonitor 0.7655 0.0143 0.9156 0.8809 ------------------------------------------------------------------------------------------ mAP@0.5 = 0.7560
Prune and retrain
TAO Toolkit also features pruning functionality that can prune a model to reduce the number of parameters. Reducing the number of parameters leads to reduction in memory consumption of the model and increase in inference throughput; both extremely important for model deployment. The goal of pruning is not to only reduce the number of parameters but also to retain comparable accuracy as an unpruned network. In our experiment, we pruned the Faster R-CNN model trained on Pascal VOC dataset. The following table compares the accuracy and performance of pruned versus unpruned network on the PASCAL VOC dataset.
| Unpruned Network | Pruned Network | |
| Pruning threshold | 0.0(unpruned) | 0.5 |
| Pruning ratio | 1.0 | 0.2785 |
| mAP | 75.6 | 74.63 |
| FPS on T4(FP32/FP16/INT8) | 12/46/70 | 19/64/98 |
- Pruning ratio = (# parameters in pruned model) / (# parameters in unpruned model).
- FPS tested on NVIDIA T4 GPU with batch size 1, at 600 x 1000 input resolution.
From the table, you can see that you can prune the Faster R-CNN model to about one fourth the model size (in terms of number of parameters) which results in about 40% increase in frames per second (FPS), while still maintaining accuracy (mAP) within a single point. You should typically experiment with few pruning threshold parameters to see which settings provide the best accuracy and performance tradeoffs.
Train on COCO 2014
You also do training on the COCO 2014 dataset with Faster R-CNN. For this training, use ResNet101 as its backbone and use the previously trained ImageNet-based ResNet101 model as pretrained weights for Faster R-CNN training.
Convert KITTI text labels to TFRecords
As in PASCAL VOC training, you must convert the KITTI text files to TFRecords. You use a dataset spec file to convert the training KITTI text files to TFRecords. Name this dataset spec file as coco14_dataset_spec_train.txt. Similarly, you also need the dataset spec to convert the validation set. Name the latter as coco14_dataset_spec_val.txt. Use the dataset_convert tool to generate TFRecords. Some of the COCO images cannot be loaded by TensorFlow image loader during training. In that case, delete those image/label pairs and regenerate TFRecords.
# training set mkdir -p /home/<username>/tao-experiments/data/coco2014/tfrecords/train2014 tao faster_rcnn dataset_convert --gpu_index 0 -d /workspace/tao-experiments/data/coco2014/coco14_dataset_spec_train.txt -o /workspace/tao-experiments/data/coco2014/tfrecords/train2014/train # validation set mkdir -p /home/<username>/tao-experiments/data/coco2014/tfrecords/val2014 tao faster_rcnn dataset_convert --gpu_index 0 -d /workspace/tao-experiments/data/coco2014/coco14_dataset_spec_val.txt -o /workspace/tao-experiments/data/coco2014/tfrecords/val2014/val
Train
When the dataset is ready, you need a spec file to configure our COCO training, same as in PASCAL VOC training. Download the spec file for COCO 2014 training: spec.txt. Start the TAO Toolkit training with a single GPU (we used a V100 32-GB GPU).
tao faster_rcnn train --gpu_index 0 -e /workspace/tao-experiments/coco2014/spec.txt
Validate
When training is complete, check the screen log to see its accuracy on the COCO 2014 validation set. There are two metrics commonly used in COCO, the first one is the ordinary mAP with IoU=0.5, while the other one is the average of mAP when IoU changes from 0.5 to 0.95, with a step size of 0.05. The first metric is called mAP@0.5 and the other one is mAP@[0.5:0.95]. TAO Toolkit prints both metrics, along with each mAP value at any IoU in [0.5, 0.95].
The mAP results look like the following:
========================================================================================== Class AP precision recall RPN_recall ------------------------------------------------------------------------------------------ airplane 0.6976 0.0655 0.8394 0.8055 ... mAP@0.5 = 0.4857 ... mAP@[0.5:0.9500000067055225] = 0.2700
The TAO Toolkit Faster R-CNN model on COCO 2014 can reach mAP@0.5 of 0.4857 and mAP@[0.5:0.95] of 0.27.
Summary of Faster R-CNN mAP
Table 4 summarizes the TAO Toolkit-based Faster R-CNN mAP on PASCAL VOC and COCO 2014 dataset and compares them with numbers from the literature. You can see that the TAO Toolkit-based Faster R-CNN model can reach or even exceed SOTA accuracy on both PASCAL VOC and COCO2014 datasets.
| Model | Dataset | SOTA accuracy | TAO Toolkit accuracy |
| Faster R-CNN VGG16 | PASCAL VOC 0712 | 73.2 | 75.6 |
| Faster R-CNN ResNet101 | COCO 2014 | 48.4/27.2 | 48.57/27.0 |
Training SSD models
In this section, we walk you through the steps to train the SSD object detection model to achieve highest accuracy on Pascal VOC 07 test dataset and COCO 2017 validation dataset using the ImageNet-pretrained VGG16 backbone.
Train on PASCAL VOC2007 and VOC2012
Follow the steps in Prepare the datasets to get KITTI format labels. After you have the PASCAL VOC dataset in KITTI format, you use images and its corresponding labels directly for SSD training.
Prepare the training spec file
We provided a spec file for training SSD models with input size 300×300 on PASCAL VOC dataset. The model’s backbone is ImageNet-pretrained VGG16. Name this model as SSD_VGG16_300X300. You train the SSD_VGG16_300X300 for 240 epochs with batch_size=32. The optimizer is SGD with 0.9 momentum with a sophisticated learning rate scheduler. You also apply L2 regularization to the training with 0.0005 regularizing weights.
Train
Run the following command to trigger the training:
tao ssd train --gpu_index 0 -e /workspace/tao-experiments/ssd/ssd_vgg16_voc.txt -m /workspace/tao-experiments/classification/vgg16/weights/vgg_080.tao -k nvidia_tao -r /workspace/tao-experiments/ssd/voc/
It takes around 21 hours to finish the whole training on Pascal VOC dataset with a single V100 GPU.
Validate
After training, check the screen log to see the mAP on the validation set. The evaluation metric is VOC2007 11-point sampled mAP with a matching IoU threshold of 0.5. Evaluate the model on the VOC07 test dataset. The following is a sample evaluation log of an SSD_VGG16_300X300 model:
******************************* aeroplane AP 0.778 ... tvmonitor AP 0.774 mAP 0.776 *******************************
The model’s mAP based on the log is 77.6% with a matching IoU threshold of 0.5. Because the training dataset is shuffled every epoch with SSD-style augmentation during the training, the final mAP number is not the same as what’s shown. However, the gap should be within 1%.
Train on COCO 2017
You can also do training on the COCO 2014 dataset with Faster R-CNN. For this training, use ResNet101 as the backbone and use the previously trained ImageNet-based ResNet101 model as pretrained weights.
Prepare the training spec file
You also use SSD_VGG16_300x300 to train on the COCO 2017 dataset. The anchor scales range in SSD config for COCO 2017 is wider than that in config for Pascal VOC because the range of objects spatial sizes is larger. You train the SSD_VGG16_300X300 for 95 epochs with batch_size=32. The optimizer is SGD with 0.9 momentum with a sophisticated learning rate scheduler. You also apply L2 regularization to the training with 0.0005 regularizing weights. Download the spec file: ssd_vgg16_coco17.txt.
Train
Run the following command to trigger the training:
tao ssd train --gpu_index 0 -e /workspace/tao-experiments/ssd/ssd_vgg16_coco17.txt -m /workspace/tao-experiments/classification/vgg16/weights/vgg_080.tao -k nvidia_tao -r /workspace/tao-experiments/ssd/coco17
It takes around 90 hours to finish the whole training on COCO17 dataset with a single V100 GPU.
Validate
After training, check the screen log to see the mAP on the validation set. The evaluation metric is integration mAP with a matching IoU threshold of 0.5. Evaluate the model on the COCO2017 validation dataset. The following is a sample evaluation log of an SSD_VGG16_300X300 model:
******************************* airplane AP 0.759 ... zebra AP 0.807 mAP 0.431 *******************************
To get the mAP@[0.5:0.95], evaluate the model with different matching IoU threshold by changing matching_iou_threshold in evaluation_config then average the mAP.
Summary of SSD mAP
Table 5 summarizes the TAO Toolkit SSD mAP on PASCAL VOC and COCO2017 and compares them with state-of-the-art results. You can see that the TAO Toolkit-based SSD model can reach or even exceed SOTA accuracy on both PASCAL VOC and COCO2017 datasets.
| Model | Dataset | SOTA accuracy | TAO Toolkit accuracy |
| SSD_VGG16_300X300 | PASCAL VOC 0712 | 77.2 | 77.6 |
| SSD_VGG16_300X300 | COCO2017 | 42.9/25.1 | 43.1/26.1 |
Like Faster R-CNN model in the previous section, TAO Toolkit can also prune the SSD models to smaller sizes without sacrificing the accuracy. Tables 6 and 7 show the pruned model’s accuracy and inference throughput compared to the unpruned models. We used the pruning threshold 0.625 and 0.6 on Pascal VOC and on the COCO dataset, respectively. Retraining is conducted after pruning with the same config file as training.
| Unpruned Network | Pruned Network | |
| Pruning threshold | 0.0(unpruned) | 0.625 |
| Pruning ratio | 1.0 | 0.79 |
| mAP | 77.6 | 77.5 |
| FPS on T4 (FP32) | 91 | 115 |
| Unpruned Network | Pruned Network | |
| Pruning threshold | 0.0(unpruned) | 0.6 |
| Pruning ratio | 1.0 | 0.74 |
| mAP | 43.1 | 43.2 |
| FPS on T4 (FP32) | 67 | 91 |
With pruning, you can reduce the overall size of the model by 20% to 25% which provides a 25% to 35% increase in inference throughput on T4 GPU at FP32 precision. The FPS (frames/sec) number was generated using trtexec with TensorRT 7.2 with batch size 1.
Training a RetinaNet model
In this section, we walk you through the steps to reach RetinaNet’s state-of-the-art mAP on the COCO2017 validation dataset with the ImageNet-pretrained ResNet50 backbone.
Train on COCO 2017
Follow the steps in Prepare the datasets to get KITTI format labels. After you have the COCO2017 dataset in KITTI format, use images and its corresponding labels directly for RetinaNet training.
Prepare the training spec file
In this example, follow the same gamma (2), alpha (0.25), scales (3) and aspect ratio (1, 2, 0.5) settings as shown in Table 1(b)(c) of the RetinaNet paper, Focal Loss for Dense Object Detection. The input size is set to 608 * 608, as width and height should be a multiplier of 32. Download the full spec file for RetinaNet model training.
Train
Run the following command to trigger the training:
tao retinanet train --gpu_index 0 -e /workspace/tao-experiments/retinanet/coco/spec.txt -k <pretrained_model_key> -r /workspace/tao-experiments/retinanet/coco
Validate
After training, check the screen log to see the mAP on the validation set.
The evaluation metric is integration mAP with a matching IoU threshold of 0.5. Evaluate the model on the COCO2017 validation dataset. The following is a sample evaluation log of a RetinaNet ResNet50 model:
******************************* airplane AP 0.83 ... zebra AP 0.868 mAP 0.529 *******************************
To get the mAP@[0.5:0.95], evaluate the model with a different matching IoU threshold by changing matching_iou_threshold in evaluation_config then average the mAP.
Summary of RetinaNet mAP
The following table summarizes the TAO Toolkit RetinaNet mAP on COCO2017 and compares it with state-of-the-art results.
| Model | Dataset | SOTA accuracy | TAO Toolkit accuracy |
| RetinaNet ResNet50 | COCO2017 | 52.5 | 52.9 |
Training YOLOv3 models
In this section, we walk you through the steps to reach YOLOv3’s state-of-the-art mAP on the Pascal VOC2007 test dataset and COCO2014 validation dataset with the ImageNet-pretrained DarkNet53 backbone.
Train on PASCAL VOC2007 and VOC2012
First, convert the dataset to KITTI format labels from the Prepare the dataset section. After you have the PASCAL VOC dataset in KITTI format, instead of generating TFrecord, use the images and its corresponding labels directly for YOLOv3 training. To compare with the SOTA model, exclude all difficult boxes from labels. The SOTA label is generated with the voc_label.py Python script, which excludes difficult boxes. To exclude difficult boxes, after you prepare the dataset, remove all bounding boxes, both in the training and validation set, that are difficult from the KITTI labels. If you use the xml_to_kitti.py script that we provided and set argument -d , that puts the occlusion parameter over difficult boxes. You can write a script to remove all such boxes.
Prepare the training spec file
We provided a spec for training YOLOv3 models with input size 416*416 on PASCAL VOC dataset. The model’s backbone is ImageNet-pretrained DarkNet53. Download the full spec file for YOLOv3 Pascal VOC: yolov3/v3_voc.txt. After you download this spec file, be sure to replace the pretrain_model_path value with the path to DarkNet53 ImageNet classification model that you trained with the highest validation accuracy.
Train
Run the following command to trigger the training:
tao yolo_v3 train --gpu_index 0 -e /workspace/tao-experiments/yolo_v3/coco/spec.txt -k nvidia_tao -r /workspace/tao-experiments/yolo_v3/coco
Validate
After training, check the screen log to see the mAP on the validation set. The evaluation metric is VOC07 11-point sampled mAP with a matching IoU threshold of 0.5. Evaluate the model on the VOC07 test dataset. The following is a sample evaluation log of a YOLOv3 model:
******************************* aeroplane AP 0.830 ... tvmonitor AP 0.747 mAP 0.753 *******************************
Based on the log, the model mAP is 75.3% with a matching IoU threshold of 0.5. Because the training dataset is shuffled every epoch during the training, SSD-style augmentation introduces the random pattern of the images. The final mAP number is not the same with the spec file provided. However, the gap should be within 1%.
Training on the COCO 2014 dataset
In this section, we walk you through the steps to reach YOLOv3’s state-of-the-art mAP on the COCO 2014 validation dataset with the ImageNet-pretrained DarkNet53 backbone.
Preparing COCO 2014 dataset
Download the COCO 2014 dataset from the COCO website. To compare with the SOTA model, do the training/testing split the same way as the original author. Also, the author’s training/validation split is different from the COCO 2014 official training/validation split and can be reproduced by the get_coco_dataset.sh bash file.
Using the bash file, get 5k.txt and no5k.txt. Those are the file names for validation and training images/labels. After preparing the data following the COCO 2014 data preparation section, merge the original training/validation set and re-split it according to those two files. The re-split training and validation set is used as the training/validation set for YOLOv3. This re-split procedure is important to reproduce the SOTA results.
Prepare the training spec file
We provided a spec for training YOLOv3 models with input size 416*416 on the COCO 2014 dataset. The model’s backbone is the ImageNet-pretrained DarkNet53. Download the full spec file for YOLOv3 COCO14: v3_coco.txt. After you download this spec file, be sure to replace the pretrain_model_path value with the path to DarkNet53 ImageNet classification model that you trained with the highest validation accuracy.
Train
Run the following command to trigger the training:
tao yolo_v3 train -e /workspace/tao-experiments/yolo_v4/coco/spec.txt -k nvidia_tao -r /workspace/tao-experiments/yolo_v4/coco
Validate
After training, check the screen log to see the mAP on the validation set. The evaluation metric is 11-points sample mAP with a matching IoU threshold of 0.5. Evaluate the model on the COCO2014 (DarkNet split) validation dataset. The following is a sample evaluation log of a YOLOv3 model:
******************************* airplane AP 0.812 ... zebra AP 0.814 mAP 0.523 *******************************
Summary of YOLOv3 mAP
Here’s the accuracy for TAO Toolkit YOLOv3 mAP on PASCAL VOC and COCO2014 compared to the state-of-the-art results.
| Model | Dataset | SOTA accuracy | TAO Toolkit accuracy |
| YOLOv3_DarkNet53 | PASCAL VOC2007/VOC2012 | 75.4% | 75.3% |
| YOLOv3_DarkNet53 | COCO2014 (DarkNet split) | 54.2% | 52.3% |
Summary
In this post, you learned about using TAO Toolkit to create AI models that achieve comparable or higher accuracies on several popular deep learning architectures as compared to the literature. TAO Toolkit is a zero-coding, AI training toolkit that makes it easy for anyone to get started with training custom AI models.
With TAO Toolkit, you do not have to spend months learning deep learning frameworks to create a model or struggle with optimizing models for deployment.
TAO Toolkit supports all the popular DL architectures such as ResNet, Faster R-CNN, SSD, YoloV3/V4, and others. As noted in our experiments, the accuracy achieved by the toolkit is comparable and sometimes higher than what is presented in literature. In addition to ease of use and flexibility, TAO Toolkit also provides features such as model pruning and INT8 quantization, which can optimize the model for inference without sacrificing accuracy. Pruning and INT8 quantization is supported on all image classification and object detection networks.
For more information, see the following resources:
