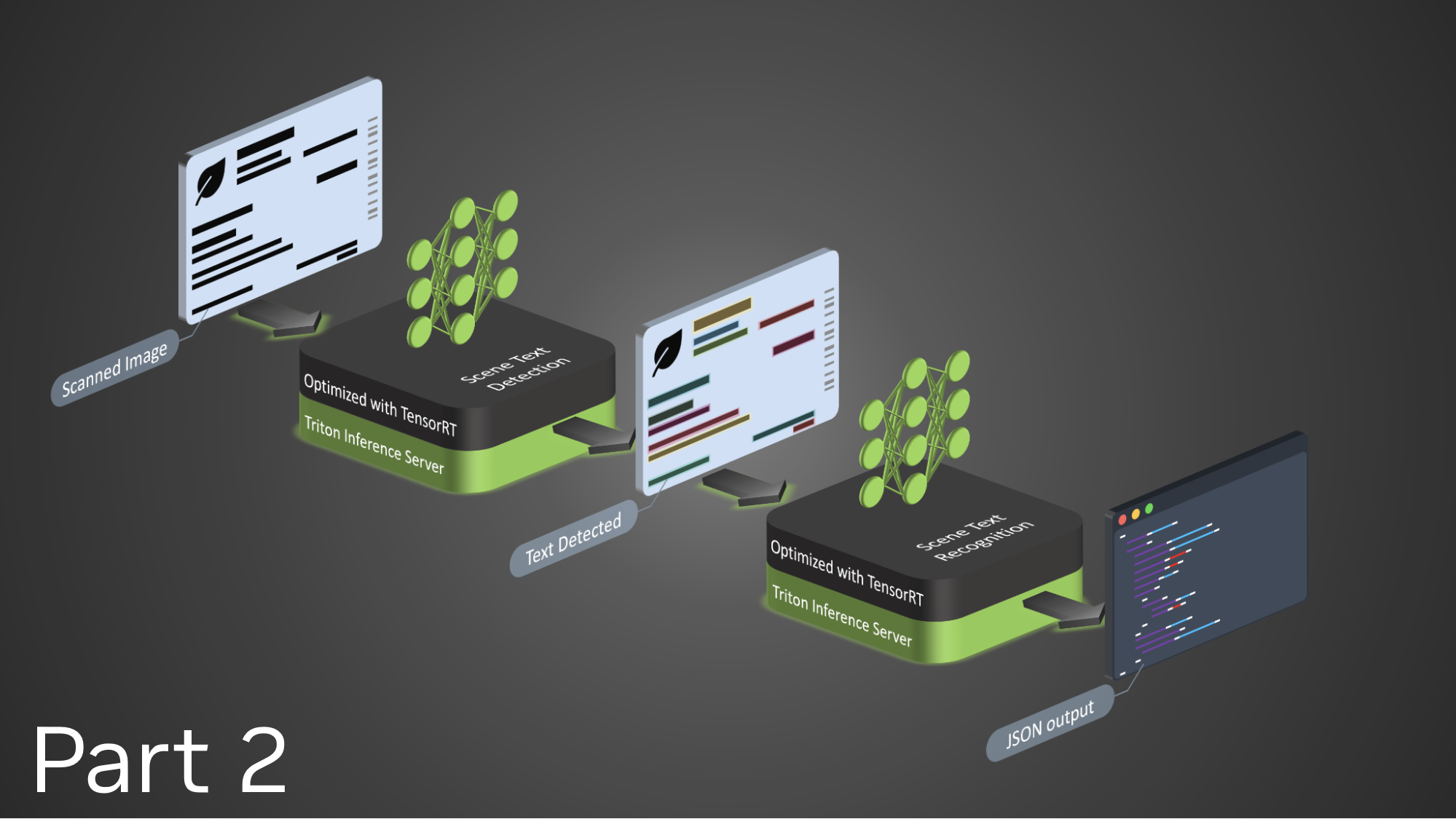
要使场景文本检测和识别适用于不规则文本或特定用例,您必须完全控制模型,以便根据用例和数据集执行增量学习或微调。请记住,此工作流是场景理解、基于 AI 的检查和文档处理平台的主要构建块。它应该准确且低延迟。
在本系列的第一篇文章中,强大的场景文本检测和识别:简介 讨论了稳健的场景文本检测和识别(STDR)在各行各业中的重要性以及所面临的挑战。第三篇博文 强大的场景文本检测和识别:推理优化 涵盖了 STDR 工作流的生产就绪型优化和性能。
在这篇博文中,我们决定采用高度精确的先进深度学习模型。为了确保准确性并维持较低的端到端延迟,我们采用了以下工具和框架来执行模型推理优化:NVIDIA TensorRT 和 ONNX Runtime。为了确保标准模型能够被部署和执行,同时保证具有可扩展性的高性能推理,我们还选择使用了 NVIDIA Triton 推理服务器。
为了训练模型,我们使用了NGC 目录 作为 GPU 优化 AI 和 ML 软件的中心。NGC 容器利用 NVIDIA GPU 的强大功能,可以在配置了 NVIDIA 虚拟 GPU (vGPU) 软件的虚拟机 (VM) 中运行,适用于 NVIDIA vGPU 和 GPU 透传部署。这些容器预配置了适用于 PyTorch 和 TensorRT 等 SDK 的优化库。
为了在云端、本地和边缘实现高性能推理,我们还使用了 Triton 推理服务器 Docker 容器。此容器支持在单个 GPU 或 CPU 上同时执行来自不同框架的多个模型。在多 GPU 服务器上,Triton 推理服务器会自动为每个 GPU 上的每个模型创建一个实例,以更大限度地提高利用率。
STDR 管道有三个构建块:
- 场景文本检测
- 场景文本识别
- 编排
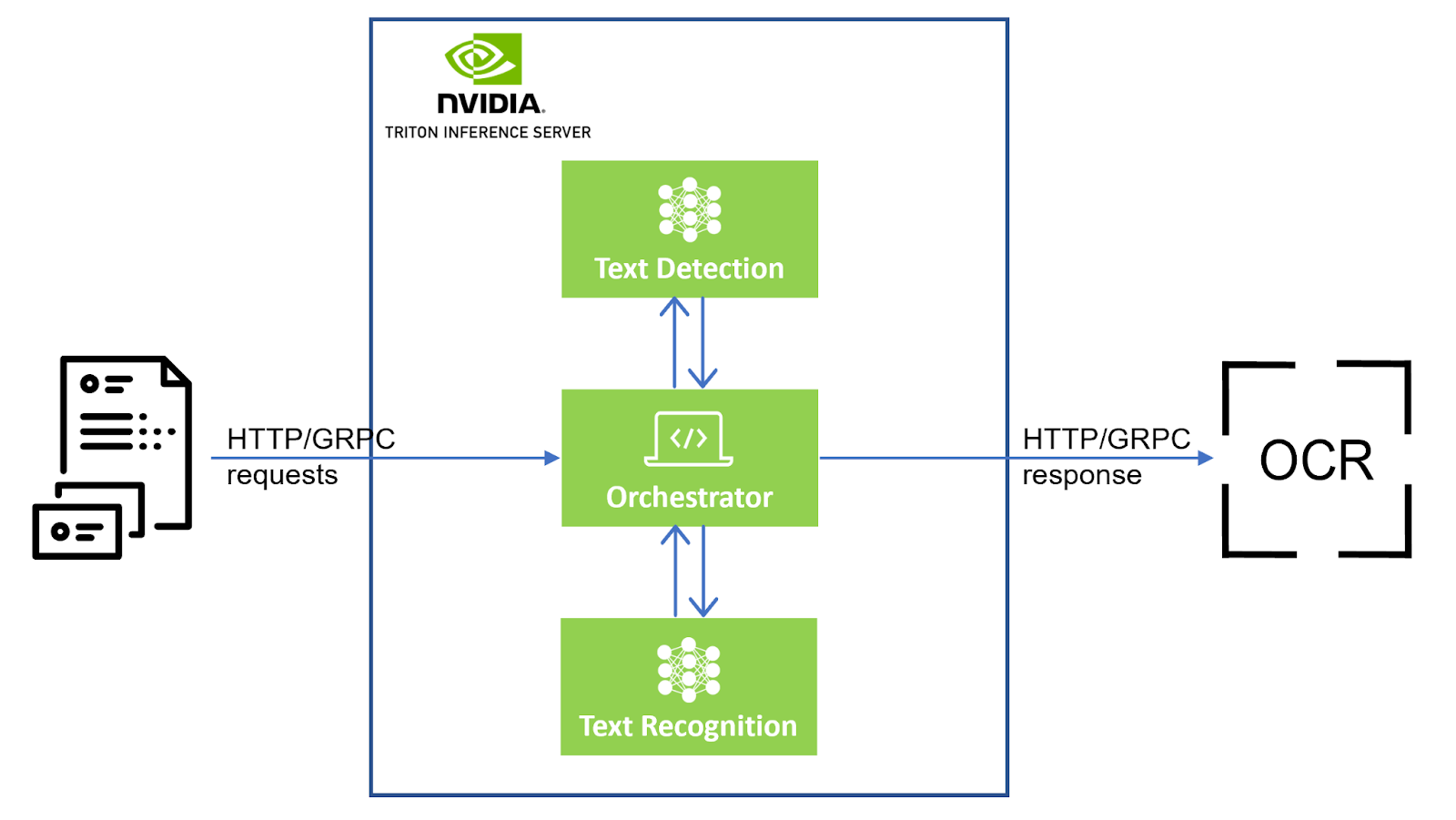
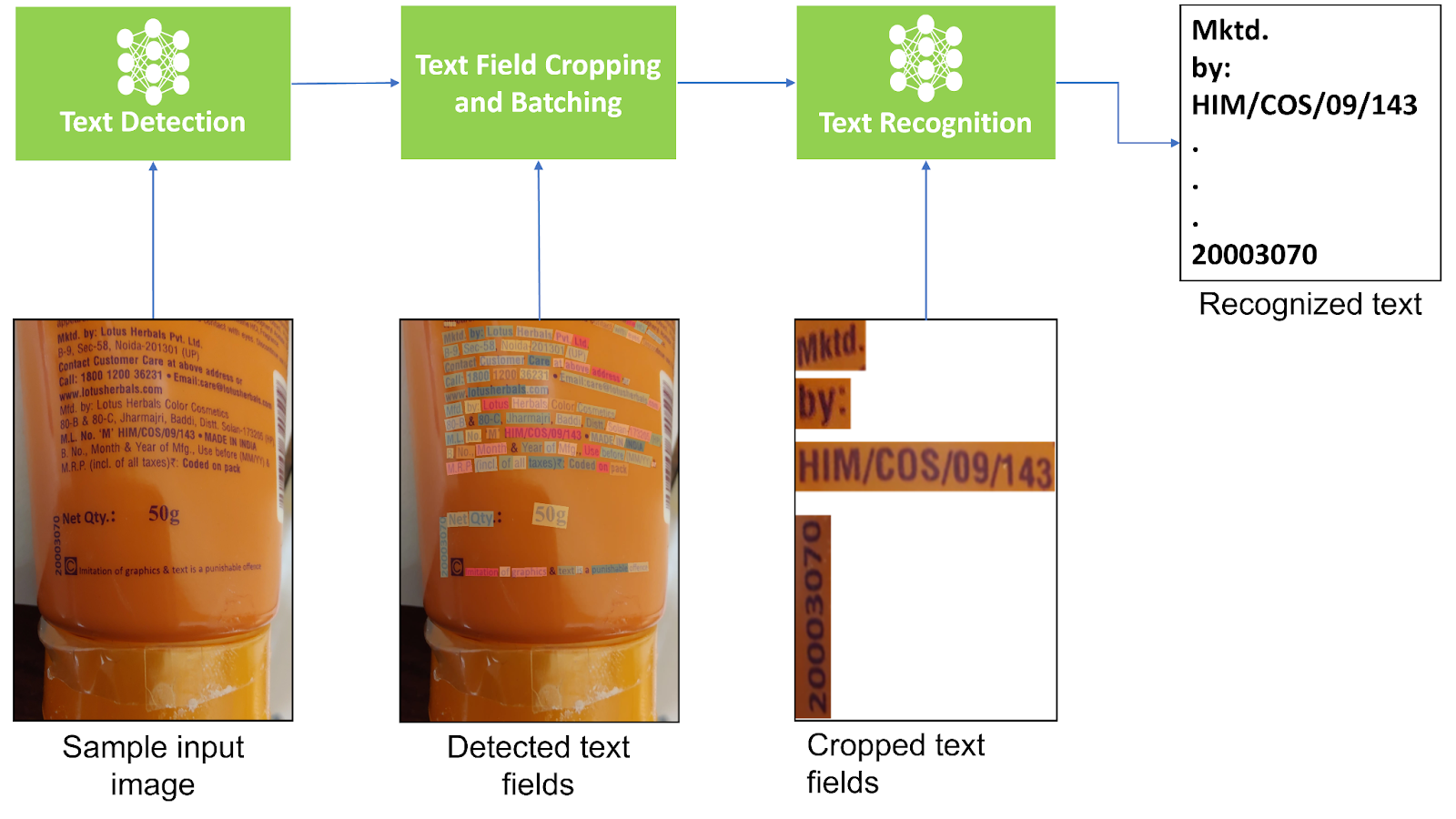
场景文本检测
在当前工作流中,文本检测算法有以下选项:
- FCENet
- CRAFT
- TextFuseNet
您可以针对特定用例训练和微调 FCENet 和 TextFuseNet。但是,由于 Clova AI 出于知识产权原因未发布训练代码,因此无法训练或微调 CRAFT。我们的通用型工作流程使用了在 synthText、IC13 和 IC17 数据集上进行训练的预训练 CRAFT 模型。有关更多信息,请参阅用于文本检测的字符区域感知。
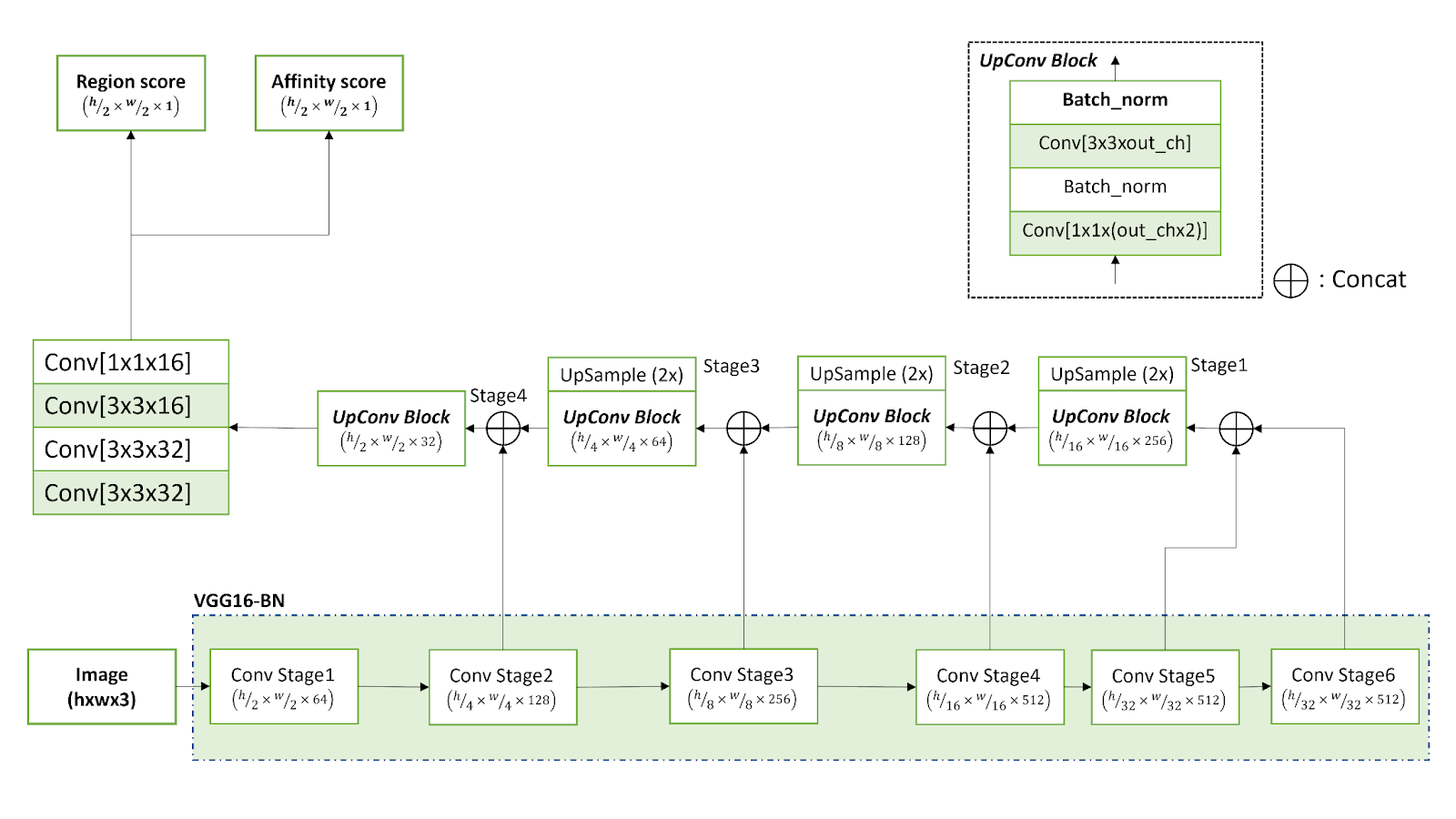
此网络使用基于 VGG-16 模型的全卷积网络架构,该架构将输入编码为独特的特征表示。CRAFT 的解码段与 UNet 的解码段类似,包括聚合低级别特征的跳转连接。
CRAFT 为每个角色预测两个单独的分数:
- 地区评分:提供有关角色所在区域的信息。
- 亲和力分数:展示角色组合成为单一实体的程度。

场景文本识别
在本文中,我们采用了先进的场景文本识别技术和置换自回归序列 (PARseq) 算法。欲了解更多信息,请参阅使用置换自回归序列模型进行场景文本识别。
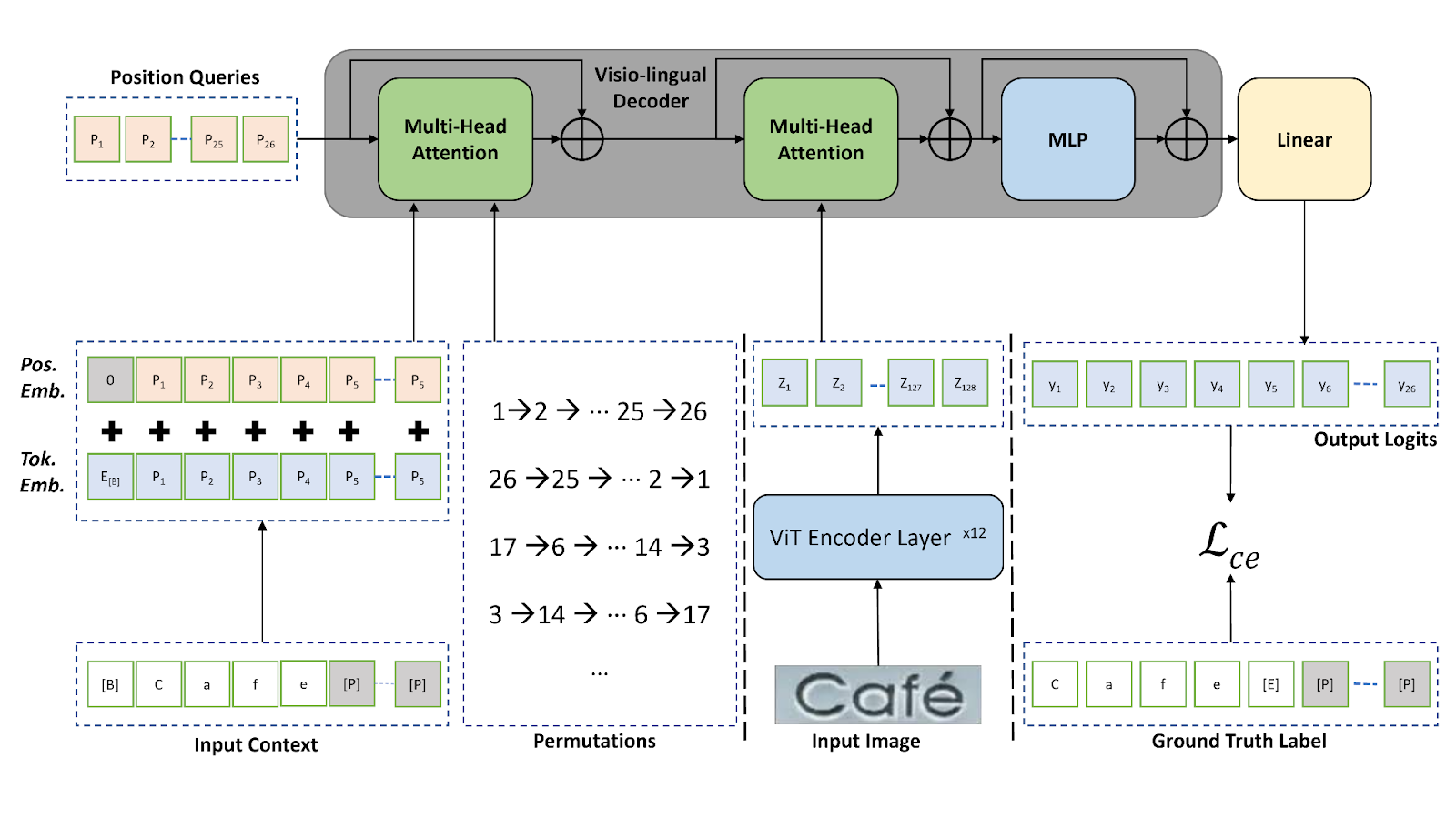
我们在 MJSynth 和 SynthText、COCO-Text、RCTW17、Uber-Text、ArT、LSVT 以及 MLT19 等多个数据集上训练了已发布的预训练模型。此外,我们还使用增量学习技术在自定义数据集上对预训练模型进行了微调。
编排师
编排器模块是流程的控制单元。此模块负责协调场景文本检测和场景文本识别。
- 它会接收来自请求的输入图像。
- 系统会对该图像进行预处理,并将其发送到场景文本检测模块。
- 检测模块会返回输入图像中文本字段的位置。
- Orchestrator 会将输入图像中的文本字段裁剪为
ndarrays. - 它根据预定义批量大小的裁剪文本图像创建批量,并一次将一个批量发送到文本识别模块。
- 识别模块会返回 STR 输出,并为该批处理中的每个裁剪文本图像提供置信度分数。
编排器会维护每个文本字段位置、相应 STR 输出和置信度分数的跟踪。它会使用所有这些信息创建响应 JSON.
总结
在本文中,我们讨论了使用先进的深度学习算法以及增量学习和微调等技术实现 STDR 工作流的问题。我们使用 CRAFT 算法进行文本检测,使用 PARSeq 算法进行文本识别。我们设计了一个独特的编排模块,以促进文本检测和识别之间的协调。本文还重点介绍了使用 NVIDIA TensorRT、ONNX Runtime 和 NVIDIA Triton Inference Server 进行模型优化和高性能推理服务的情况。
有关更多信息,请参阅强大的场景文本检测和识别:简介和推理优化相关文章。