识别和识别自然场景和图像中的文本对于视频标题文本识别、检测车载摄像头的标牌、信息检索、场景理解、车牌识别以及识别产品文本等用例变得非常重要。
大多数这些用例都需要近乎实时的性能。常用的文本提取技术包括使用光学字符识别 (OCR) 系统。但是,大多数免费的商用 OCR 系统都经过训练,可以识别文档中的文本。在识别自然场景或带字幕的视频(如图像透视、反射、模糊等)中的文本方面存在许多挑战。
在本系列的下一篇文章中,强大的场景文本检测和识别:实施,讨论了如何使用先进的深度学习算法和技术(例如增量学习和微调)实现 STDR 工作流。第三篇博文强大的场景文本检测和识别:推理优化,涵盖了为您的 STDR 工作流提供生产就绪型优化和性能。
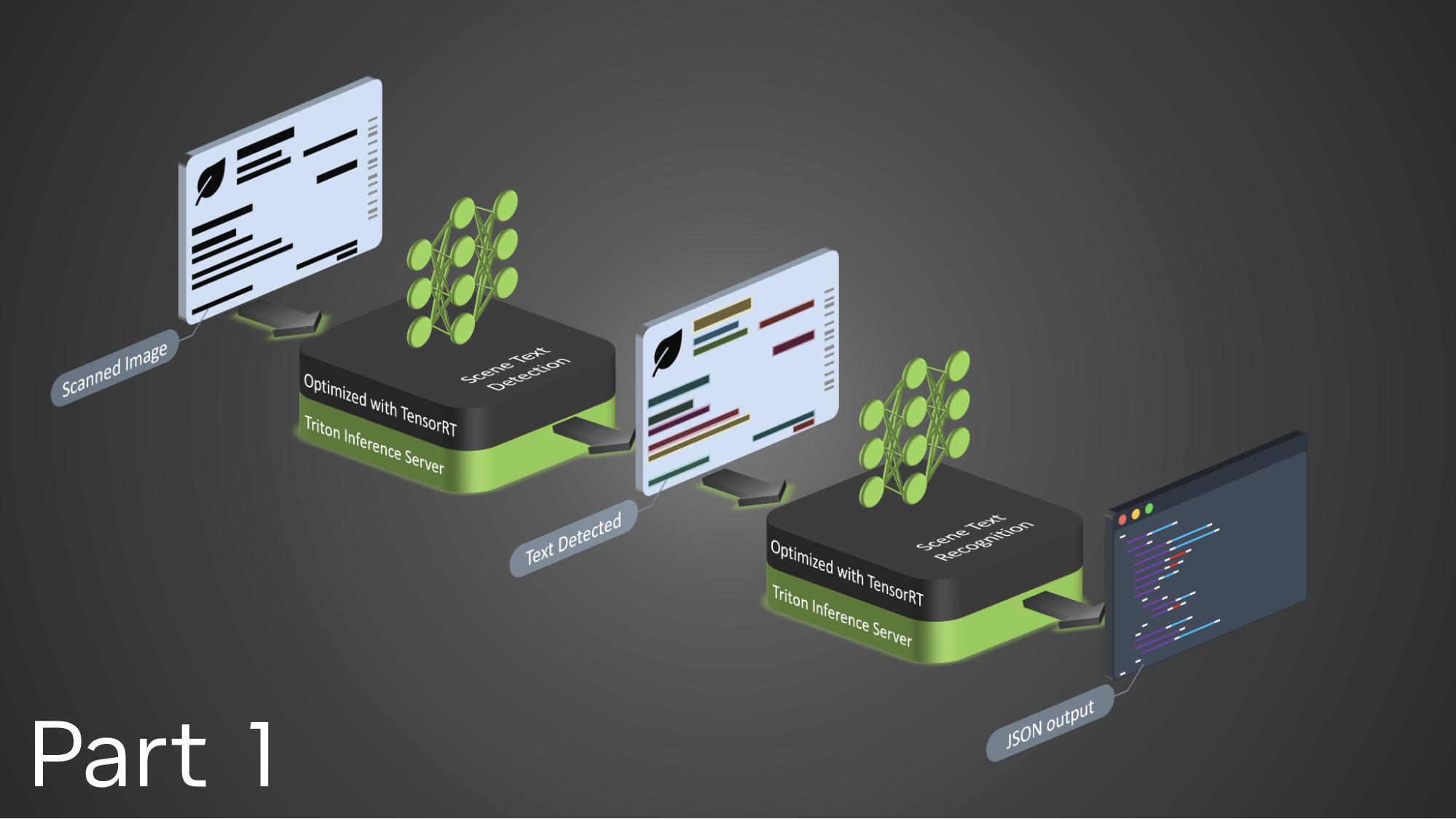
通常,文本提取过程涉及以下步骤:
- 通过文本检测算法从更大的场景中检测文本字段。
- 此文本使用自定义 OCR 技术进行提取和识别。
由于文本外观的可变性(例如曲率、方向和失真),识别自然场景图像中的不规则文本可能具有挑战性。为了克服这一问题,通常需要复杂的深度学习架构和细粒度注释。
然而,在创建和部署这些算法时,这些问题可能会导致优化和延迟挑战。尽管存在这些挑战,计算机视觉的进步在文本检测和识别方面取得了重大进展,为各行各业提供了强大的工具。为了进一步优化推理,您可以使用专业的优化工具来降低延迟并提高性能。
在本文中,我们将介绍这些挑战以及优化和加速推理的方法。我们强调,部署场景文本检测和识别 (STDR) 流程需要仔细考虑现实世界的场景和条件。为了满足这些需求,我们使用了先进的深度学习算法和利用技术,例如针对特定用例的增量学习和微调。
为确保低延迟,我们使用了以下模型推理优化工具:
- ONNX Runtime 是一个跨平台的机器学习模型加速器,它提供了与特定硬件库集成的灵活性。它可以与 PyTorch、TensorFlow 和 Keras、TensorFlow Lite、scikit-learn 以及其他框架中的模型一起使用。
- NVIDIA TensorRT SDK 用于高性能深度学习推理,提供深度学习推理优化器和运行时环境,确保推理应用程序具有低延迟和高吞吐量。
- NVIDIA Triton 推理服务器 旨在为云端、本地和边缘设备提供高性能的推理服务。
NVIDIA AI Enterprise 的软件层中包含了 TensorRT 和 Triton 推理服务器。
STDR 应用
识别图像和视频中的文本用于各行各业。
医疗健康和生命科学:场景文本检测和识别技术在医疗保健行业中应用广泛,用于扫描患者的病史记录并将其数字化存储,包括病历报告、X光片、过往疾病、治疗方案、诊断结果和医院记录。此外,医疗设备和药品制造领域的物流与仓储运营也依赖于场景文本检测和识别技术。
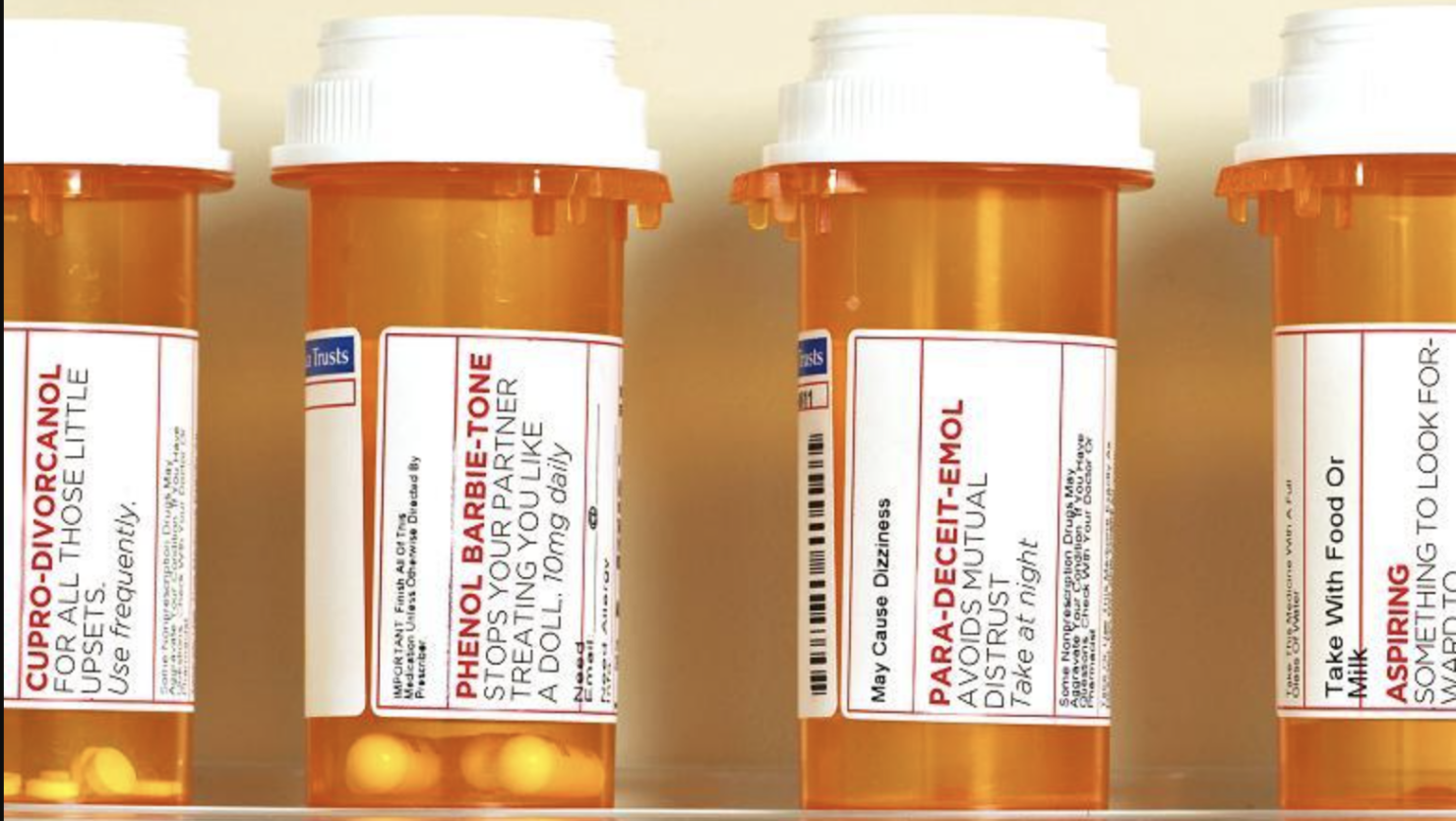
制造业供应链/物流:在整个供应链的质量控制中,场景文本检测和识别对于食品、饮料和化妆品行业至关重要。它用于跟踪产品并读取产品代码、批次代码、过期日期和序列号。这些信息有助于确保遵守安全和防伪法规,并能够在任何时候准确地追踪供应链中的产品位置。OCR 通常与条形码结合使用,以进一步提高信息收集的准确性。

银行:场景文本检测和识别在银行业有广泛应用,能够自动处理出生证明、结业证书等“了解你的客户”(KYC)文档。
汽车和公共事业:自动驾驶汽车和电力线路维护驾驶通常需要识别场景图像并提取数据(例如,街道名称、场所名称、电线杆编号以及变压器和发电机的详细信息)。通常情况下,文本在车辆移动时只出现一小段时间,从而产生运动模糊。在这种情况下,手动检测变得不可能。
STDR 挑战
从视频和手机拍摄的复杂图像中检测和提取文本的最大挑战是,此类图像中的文本通常是不规则的,并且覆盖在玻璃、塑料、橡胶等不同背景上。
此外,即使机器学习模型的开发具有相当高的准确性,模型也应实时或近乎实时地处理图像。因此,满足准确性和性能预期需要高度优化的模型,这些模型可以在云和边缘设备中进行优化。本文将详细介绍这些挑战。
创建稳健的模型
通常,场景文本模型中存在准确性问题的主要原因是输入数据的变异数量。以下是一些数据变异。
文本大小比例模糊:自然场景中的文本可能以各种大小和比例出现。文本与摄像头的距离对于文本的缩放同样起着重要作用。摄像头的角度可能会引入透视失真。此外,光照条件可能在文本周围产生反射和阴影。移动物体或摄像头的移动都有可能增加模糊效果。所有这些因素共同作用,可能会导致图像中文本的大小比例出现模糊失真。
文本方向、颜色和字体:文本可能以水平、垂直、对角线甚至循环的方式显示。这种文本方向的变化会使算法难以正确检测和识别文本。如果训练数据未能反映实际使用中的颜色、透明度和字体风格,同样会带来挑战。
背景和叠加:自然场景中的文本可能出现在各种背景之上,如建筑物、树木、车辆等,并且常常覆盖在玻璃、金属、塑料或贴纸等物体上。它还可能被浮雕或凹凸处理在不同的材质上。
多语言环境:真实世界的图像中常包含多种文字脚本和语言的文本。例如,标牌或餐厅菜单通常使用混合语言编写。
在 ML 项目中,另一个常见的挑战是获取已标记的数据来训练模型。然而,在此管道中,我们使用了预训练的CRAFT 模型进行文本检测,该模型在SynthText、IC13以及IC17数据集上进行了训练。
对于文本识别,我们使用了PARseq 模型在各种数据集上进行训练MJSynth, SynthText,COCO 文本, RCTW17, Uber-Text, ArT, LSVT, MLT19以及ReCTS, TextOCR)并根据内部数据进行微调。
满足性能预期
部署场景文本检测解决方案也会带来各种挑战。
计算资源:当今,现代 STDR 系统采用了复杂的深度学习算法。这些模型参数众多,导致运行成本高昂。因此,在计算资源受限的设备上(如智能手机或物联网 (IoT) 设备)部署这些解决方案变得颇具挑战。
延迟和响应时间摘要:在许多应用场景中,文本检测和识别必须实时进行才能发挥其效用。尽管深度学习模型能够提供高准确率,但其庞大的参数数量相较于参数较少的模型,会增加推理时间,从而导致不可接受的延迟和响应时间。为了在保持准确性的同时优化推理速度,可以采用先进算法,并通过量化、降低精度、剪枝等技术进行模型优化。然而,这些优化措施可能会对模型的准确性产生一定影响。
数据隐私和安全:在真实场景中部署解决方案时,用于训练和运行模型的数据的隐私和安全性极为重要。需要采取措施保护模型不受恶意攻击和防止数据泄露。同时,必须确保严格遵守数据隐私法规。
部署场景文本检测解决方案需要仔细考虑使用该解决方案的真实场景和条件。此过程是一个关键步骤,需要进行全面的测试、评估和微调。
假设一家包裹配送公司需要在传送带上使用标签读取应用程序。在这种情况下,高精度至关重要,因为任何错误都会导致延迟并给公司带来额外成本。传送带的速度是另一个需要考虑的关键因素,因为它会影响处理包裹所需的总时间。
实现高精度可能需要复杂的深度学习模型,而这些模型的计算成本高昂,会影响系统延迟。为了优化性能,必须考虑部署场景(例如传送带速度和计算资源)的具体要求和限制,并相应调整深度学习模型,以在准确性、延迟和资源之间取得平衡。
总结
在本文中,我们讨论了稳健的场景文本检测和识别 (STDR) 在各行各业中的重要性。我们重点介绍了 STDR 面临的挑战,包括创建准确的模型、满足性能预期以及处理真实世界的场景和条件。
有关更多信息,请参阅此系列的后续文章: