
想象一下,你是一名机器人或机器学习( ML )工程师,负责开发一个检测托盘的模型,以便叉车能够操纵托盘。您熟悉传统的深度学习管道,策划了手动注释的数据集,并培训了成功的模型。
你已经为下一个挑战做好了准备,它以密集堆放的托盘的形式出现。你可能会想,我应该从哪里开始? 2D 边界框检测或实例分割对此任务最有用吗?我应该进行三维边界框检测吗?如果是,我将如何对其进行注释?最好使用单眼相机、立体相机或激光雷达进行检测吗?考虑到自然仓库场景中出现的托盘数量之多,手动注释并非易事。如果我弄错了,代价可能会很高。
这就是我在面对类似情况时所想的。幸运的是,我有一个简单的方法来开始相对较低的承诺:合成数据。
合成数据概述
合成数据生成(SDG)是一种使用渲染图像而不是真实世界图像来训练神经网络的技术。使用合成渲染数据的优势在于,您可以隐式地获取场景中对象的完整形状和位置,并可以生成注释,如 2D 边界框、关键点、3D 边界框、分割遮罩等。
合成数据是引导深度学习项目的有效方法,因为它使您能够在不需要大规模手动数据注释的情况下,或者在数据有限、受限或根本不存在的情况下,快速迭代想法。对于这种情况,您可能会发现域随机化可以为您的应用程序提供有效的即用解决方案。此外,您还可以节省时间。
或者,你可能会发现你需要重新定义任务或使用不同的传感器模式。使用合成数据,你可以尝试这些决策,而无需付出昂贵的注释工作。
在许多情况下,您仍然可以从使用一些真实世界的数据中受益。好的部分是,通过对合成数据进行实验,您将更加熟悉这个问题,并可以将注释工作投入到最重要的地方。每项 ML 任务都有其自身的挑战,因此很难准确确定合成数据将如何融入,您是否需要使用真实世界的数据,或者混合使用合成数据和真实数据。
使用合成数据训练托盘分割模
当考虑如何使用合成数据来训练托盘检测模型时,我们的团队从小处着手。在我们考虑 3D 盒子检测或任何复杂的东西之前,我们首先想看看我们是否可以使用用合成数据训练的模型来检测任何东西。为此,我们渲染了一个简单的场景数据集,其中只包含一个或两个托盘,顶部有一个盒子。我们使用这些数据来训练语义分割模型。
我们之所以选择训练语义分割模型,是因为任务定义得很好,而且模型架构相对简单。还可以直观地识别模型的故障位置(不正确分割的像素)。
为了训练分割模型,团队首先渲染了粗略的合成场景(图 1 )。

该团队怀疑,仅凭这些渲染图像就缺乏训练有意义的托盘检测模型的多样性。因此,我们决定使用生成式 AI来产生更逼真的图像。在训练之前,我们将应用人工智能来对这些图像进行变换,以增加模型推广到现实世界的能力。
这是使用深度条件生成模型完成的,该模型大致保留了渲染场景中对象的姿势。请注意,使用 SDG 时不需要使用生成人工智能。你也可以尝试使用传统的领域随机化,比如改变托盘的合成纹理、颜色、位置和方向。您可能会发现,通过改变渲染纹理的传统域随机化对于应用程序来说已经足够了。

在绘制了大约 2000 幅这些合成图像后,我们使用 PyTorch 训练了一个基于 resnet18 的 Unet 分割模型。很快,结果在真实世界的图像上显示出了巨大的前景(图 3 )。

该模型可以精确地分割托盘。基于这一结果,我们对工作流程有了更多的信心,但挑战远未结束。到目前为止,该团队的方法没有区分托盘的实例,也没有检测到没有放置在地板上的托盘。对于如图 4 所示的图像,结果几乎不可用。这可能意味着我们需要调整我们的训练分布。

不断增加数据多样性以提高准确性
为了提高分割模型的准确性,该团队添加了更多以不同随机配置堆叠的各种托盘的图像。我们在数据集中又添加了大约 2000 张图像,使总数达到 4000 张。我们使用 USD 场景构建实用程序 开源项目。
USD 场景构建实用程序用于在反映您可能在现实世界中看到的分布的配置中,相对于彼此定位托盘。我们曾经提供 Universal Scene Description (OpenUSD) SimReady Assets,其中包含多种托盘型号可供选择。

使用堆叠的托盘进行训练,并使用更广泛的视角,我们能够提高这些情况下模型的准确性。
如果添加这些数据有助于模型,那么如果没有添加注释成本,为什么只生成 2000 张图像?我们没有从很多图像开始,因为我们是从相同的合成分布中采样的。添加更多的图像并不一定会给我们的数据集增加太多的多样性。相反,我们可能只是添加了许多类似的图像 从而提高了模型的真实世界的准确性。
从小处着手使团队能够快速训练模型,查看其失败的地方,并调整 SDG 管道和添加更多数据。例如,在注意到模型对托盘的特定颜色和形状有偏见后,我们添加了更多的合成数据来解决这些故障案例。

这些数据变化提高了模型处理遇到的故障场景(塑料和彩色托盘)的能力。
如果数据变化是好的,为什么不全力以赴,一次增加很多变化呢?在我们的团队开始对真实世界的数据进行测试之前,很难判断可能需要什么样的方差。我们可能错过了使模型正常工作所需的重要因素。或者,我们可能高估了其他因素的重要性,不必要地耗尽了我们的努力。通过迭代,我们可以更好地了解任务需要什么数据。
扩展托盘侧面中心检测模
一旦我们在分割方面取得了一些有希望的结果,下一步就是将任务从语义分割调整为更实用的任务。我们决定最简单的下一个评估任务是检测托盘侧面的中心。

托盘侧面中心点是叉车在操作托盘时将自身居中的位置。虽然在实践中可能需要更多的信息来操作托盘(例如此时的距离和角度),但我们认为这一点是该过程中的一个简单的下一步,使团队能够评估我们的数据对任何下游应用的有用程度。
检测这些点可以通过热图回归来完成,与分割一样,热图回归是在图像域中完成的,易于实现,并且易于视觉解释。通过为这项任务训练模型,我们可以快速评估我们的合成数据集在训练模型以检测操作的重要关键点方面的有用性。
训练后的结果很有希望,如图 8 所示。

该团队确认了使用合成数据检测托盘侧面的能力,即使是紧密堆叠的托盘。我们继续对数据、模型和训练管道进行迭代,以改进该任务的模型。
扩展拐角检测模
当我们达到侧面中心检测模型的满意点时,我们探索将任务提升到下一个层次:检测盒子的角。最初的方法是对每个角使用热图,类似于托盘侧面中心的方法。
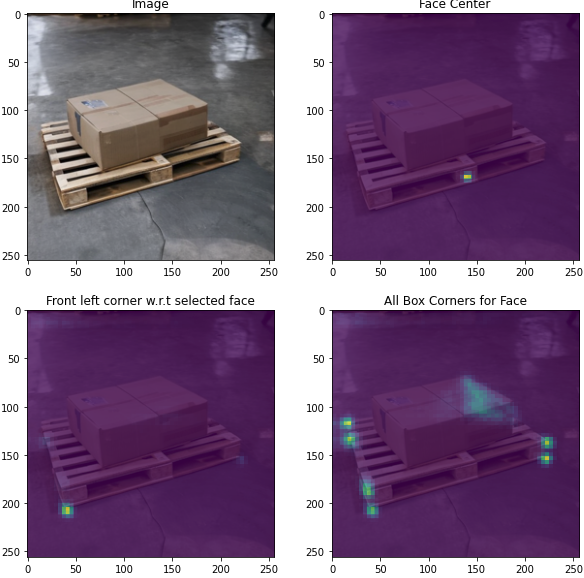
然而,这种方法很快提出了挑战。由于用于检测的对象具有未知的尺寸,因此如果托盘的角不直接可见,则模型很难精确推断出托盘的角应该在哪里。使用热图,如果峰值不一致,则很难可靠地解析它们。
因此,我们没有使用热图,而是选择在检测到人脸中心峰值后对角点位置进行回归。我们训练了一个模型来推断向量场,该向量场包含角与给定托盘面中心的偏移。这种方法很快就显示出了这项任务的前景,即使在大的遮挡情况下,我们也可以提供有意义的拐角位置估计。
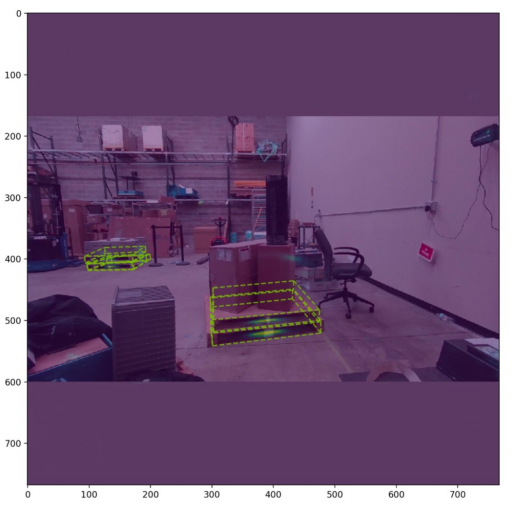
现在团队有了一个有希望的工作管道,我们迭代并扩展了这个过程,以解决出现的不同故障案例。总的来说,我们的最终模型是在大约 25000 张渲染图像上进行训练的。我们的模型以相对较低的分辨率( 256 x 256 像素)进行训练,能够通过以更高的分辨率运行推理来检测小托盘。最终,我们能够以相对较高的精度检测到具有挑战性的场景,如上面的场景。
这是我们可以使用的东西——所有这些都是用合成数据创建的。这就是我们今天的托盘检测模型。


开始使用合成数据构建自己的模
通过使用合成数据迭代开发,我们的团队开发了一个适用于真实世界图像的托盘检测模型。更多的迭代可能会取得进一步的进展。除此之外,我们的任务可能会受益于添加真实世界的数据。然而,如果没有合成数据生成,我们就不可能快速迭代,因为我们所做的每一次更改都需要新的注释工作。
如果您有兴趣尝试这个模型,或者正在开发一个可以使用托盘检测模型的应用程序,您可以通过访问 SDG Pallet Model GitHub 找到模型和推理代码。回购包括预训练的 ONNX 模型,以及使用 TensorRT 优化模型和对图像运行推理的指令。该模型可以在 NVIDIA Jetson AGX Orin 上实时运行,因此您可以在边缘运行它。
您还可以查看最新的开源项目,USD 场景构建实用程序,其中包含使用 USD Python API 构建 Python 场景的示例和实用程序。
我们希望我们的经验能激励您探索如何使用合成数据来引导您的人工智能应用程序。如果您想开始合成数据生成, NVIDIA 提供了一套简化过程的工具。其中包括:
- Universal Scene Description (OpenUSD):被称为宇宙的 HTML,USD 是一个完整描述 3D 世界的框架。它不仅包括 3D 对象网格等基本元素,还能够描述材料、照明、相机、物理等。
- NVIDIA Omniverse Replicator:作为NVIDIA Omniverse的核心扩展,Replicator 平台使开发人员能够生成大量多样的合成训练数据,以引导感知模型训练。Replicator 具有易于使用的 API 、域随机化和多传感器模拟等功能,可以解决数据不足的问题,并加快模型训练的进程。
- SimReady Assets:支持模拟的资产是物理上精确的 3D 对象,包含精确的物理属性、行为和连接的数据流,以在模拟的数字世界中表示真实世界。 NVIDIA 提供了一系列逼真的资产和材料,可用于构建 3D 场景。这包括与仓库物流相关的各种资产,如托盘、手推车和纸箱。要在将 SimReady 资产添加到活动阶段之前搜索、显示、检查和配置这些资产,可以使用SimReady Explorer扩大每个 SimReady 资产都有自己预定义的语义标签,从而更容易生成用于分割或对象检测模型的注释数据。
如果您对托盘模型、使用 NVIDIA Omniverse 生成合成数据或使用 NVIDIA Jetson 进行推理有疑问,请访问 GitHub 或访问 NVIDIA Omniverse 合成数据生成开发者论坛 以及 NVIDIA Jetson Orin Nano 开发者论坛。
在 SIGGRAPH 探索人工智能的下一步
参加我们的 SIGGRAPH 2023,NVIDIA 首席执行官黄仁勋将发表强有力的主题演讲。您将有机会独家了解我们的一些最新技术,包括屡获殊荣的研究、OpenUSD 开发以及最新的人工智能内容创作解决方案。




