大规模图形神经网络 (GNN) 训练带来了艰巨的挑战,特别是在图形数据的规模和复杂性方面。这些挑战不仅涉及神经网络的正向和反向计算的典型问题,还包括带宽密集型图形特征收集和采样以及单个 GPU 容量限制等问题。
在上一篇文章中,WholeGraph 被作为 RAPIDS cuGraph 库中的一项突破性功能,旨在优化大规模 GNN 训练的内存存储和检索。
在我的简介文章奠定的基础上,本文将更深入地探讨 WholeGraph 的性能评估。我的重点还扩展到它作为存储库和 GNN 任务促进器的作用。借助 NVIDIA NVLink 技术的强大功能,我将探讨 WholeGraph 如何应对 GPU 间通信带宽的挑战,有效打破通信瓶颈并简化数据存储。
通过检查其性能和实际应用,我的目标是展示 WholeGraph 在克服大规模 GNN 训练中固有障碍方面的有效性。
作为存储的 WholeGraph 性能
为了评估使用 WholeGraph 作为存储的性能,我测量了固定长度内存随机采集的带宽。固定长度组织为具有固定嵌入维度的浮点嵌入向量。
测试在 NVIDIA DGX-A100 系统上进行,涵盖了 WholeGraph 支持的所有内存类型:
- 8 块 NVIDIA A100 GPU 通过 NVIDIA NVSwitch 互联。
- 每个 GPU 的双向带宽为 600 GB/s,转换为每个 GPU 每个方向的 300 GB/s 带宽。
- 每两个 GPU 连接到一个 PCIe 4.0 交换机,共享一个 PCIe 4.0 x16 主机带宽,因此每两个 GPU 到主机显存的共享带宽为 32GB/s。
- 理论上,跨多个 GPU 的内存聚合带宽为 300 GB/s 每个 GPU 8/7=343 GB/s.关于主机内存,理论上每个 GPU 的聚合带宽为 32 GB/s/2=16 GB/s。
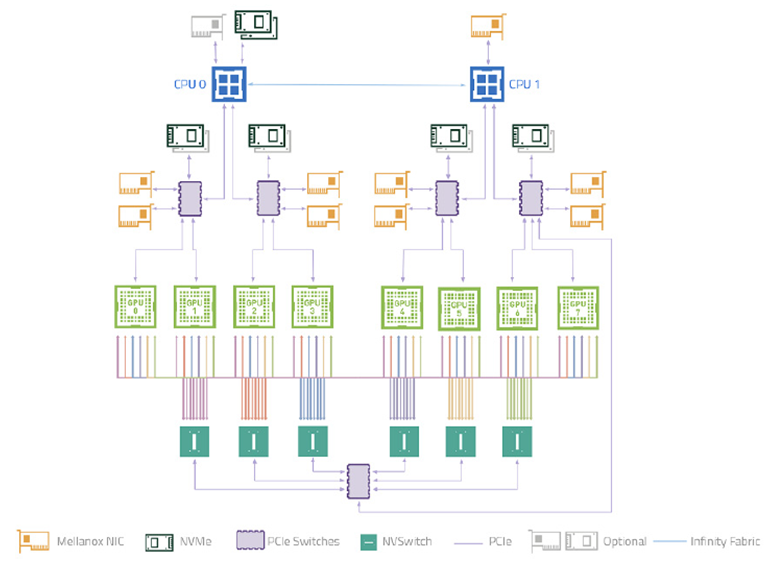
表 1 显示了基准测试结果。由于连续和分块类型的主机内存现在使用相同的实现,因此它们使用相同的列。如您所见,对于分块设备内存,您可以获得 75%的 NVLink 带宽。对于主机内存,您可以获得约 80%的 PCIe 带宽。
| 嵌入维度 | 连续设备 | 分块设备 | 分布式设备 | 非分布式+主机 | 分布式主机 |
| 32 | 2.78 | 264.16 | 113.29 | 2.47 | 11.73 |
| 64 | 5.35 | 260.99 英镑 | 133.25 | 4.91 | 12.2 |
| 128 | 10.35 | 501.03 | 144.61 | 9.73 | 12.31 |
| 256 | 19.74 | 501.18 | 14951 | 13.18 | 12.34 |
| 512 | 36.93 | 264.45 | 151.82 | 12.89 | 12.34 |
| 1024 | 68.66 | 260.25 | 155.28 | 13.18 | 12.34 |
*Non-Distributed host (非分布式主机) 是指 Continuous host (连续主机) 和 Chunked host (分块主机),因为它们使用相同的实现。
WholeGraph 在 GNN 任务中的性能
为了评估 WholeGraph 在 GNN 任务中的性能,我使用了 OGBN-Papers100M 数据集 作为测试数据集。该数据集包含约 1.11 亿个节点和 32 亿个边缘,每个节点具有 128-dim 特征,并包含 172 类节点分类任务。
在本次评估中,我将 WholeGraph 23.10 用于图形和特征存储,并将 cuGraphOps 用于 GNN 层实现。与之前一样,测试也在 DGX-A100 服务器上进行。
计算性能提升
首先,我想重点介绍一下使用 cuGraph-Ops 的最新版 WholeGraph 23.10 与之前版本的 WholeGraph 相比的性能提升。
我使用相同的训练配置和训练样本数,其中样本数为[3030,30],并训练了 24 次,以验证准确性是否良好 (测试准确率约为 65%)。改进如图 2 所示。
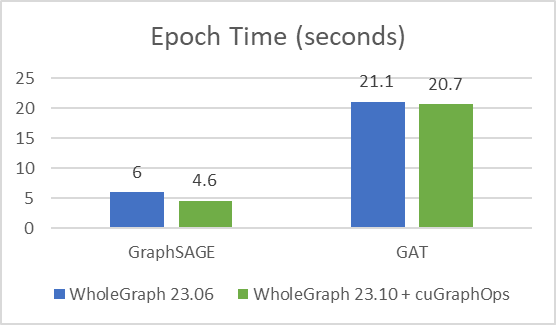
收优化时间
对于任何数据集,都可能存在最佳样本数量或其他超参数,从而为目标精度提供最佳时间。增加样本数量可能会导致大量计算,但准确度几乎没有提高。
我发现,对于目标测试准确率为 65% 的 ogmbn-papers100M 数据集,可以使用 [15,10, 5] 作为训练样本数。这与 Intel 在其论文中所报道的类似结果一致。
使用类似的样本计数对于比较很重要,因为减少样本数量可以显著减少计算负载。例如,通过将样本数量从[3030,30]减少到[15, 10, 5],计算工作负载的减少量可多达 36 倍。为了实现约 65%的测试准确率,也可能不需要执行 24 次迭代。我还调整了批量大小和学习率等超参数。
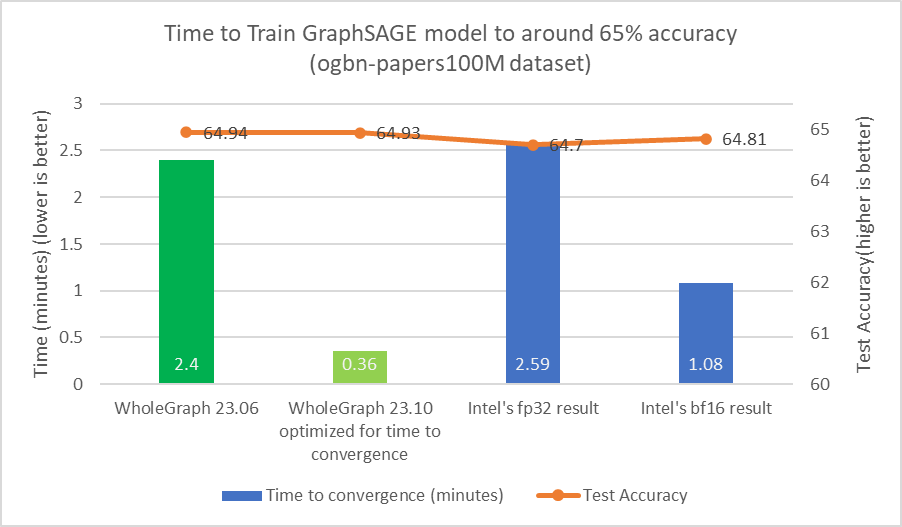
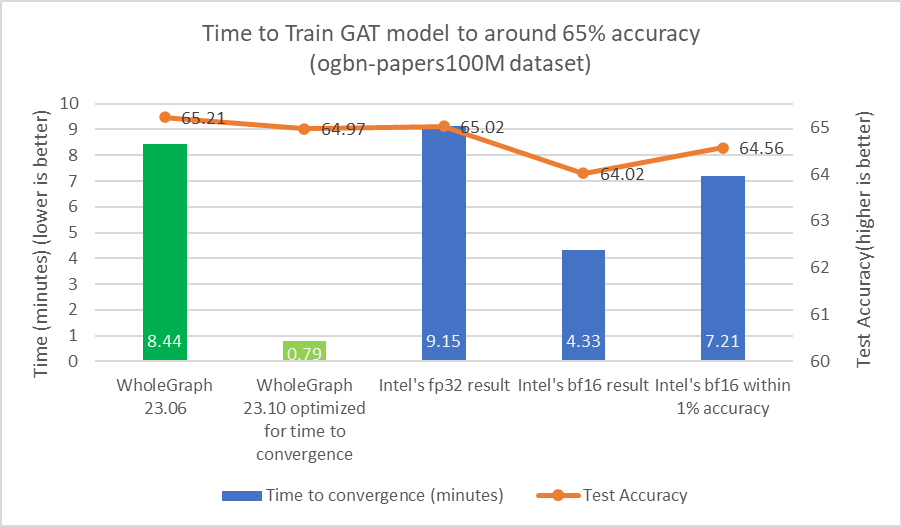
从图 3 和图 4 中可以看出,WholeGraph 在收时间方面实现了显著的加速。有关与 8 节点双路英特尔 8480+CPU 服务器比较的更多信息,请参阅以创纪录的速度设置图形神经网络模型。收时间可能因计算环境不同而有所差异。
结束语
在本文中,我展示了 WholeGraph 的性能,它与硬件的理论性能非常接近。我展示了它在现实世界的 GNN 任务中的性能,重点介绍了它显著加速 GNN 工作负载的能力。作为底层硬件, NVIDIA GPU 和 NVLink 技术为 GNN 任务提供了出色的硬件平台。