适用于 Jetson 的 NVIDIA Metropolis 微服务提供了一套易于部署的服务,使您能够使用最新的 AI 方法快速构建生产级视觉 AI 应用。
本文将介绍如何开发和部署生成式 AI 应用程序,这些应用程序在 NVIDIA Jetson 边缘 AI 平台上运行,并通过 Metropolis 微服务进行管理。您可以通过参考示例(这些示例可以作为构建任何模型的一般指南)来进行探索。
参考示例使用独立的零射检测 NanoOwl 应用,并将其与 适用于 Jetson 的 Metropolis 微服务 相结合,以便您可以在生产环境中快速构建原型并进行部署。
使用生成式 AI 实现应用转型
生成式 AI 是一种机器学习技术,它使模型能够以比之前方法更开放的方式理解世界。
大多数生成式 AI 的核心是基于 Transformer 的模型,该模型已在互联网规模的数据上进行训练。这些模型对各个领域有更广泛的理解,使它们能够用作各种任务的中坚力量。这种灵活性使 CLIP、Owl、Lama、GPT 和 Stable Diffusion 等模型能够理解自然语言输入。它们能够零学习或几次学习。

有关 Jetson 的生成式 AI 模型的更多信息,请访问 NVIDIA Jetson 生成式 AI 实验室 和 借助 NVIDIA Jetson 实现生成式 AI.
适用于 Jetson 的 Metropolis 微服务
Metropolis 微服务可用于在 Jetson 上快速构建生产就绪型 AI 应用。Metropolis 微服务是一组易于部署的模块化 Docker 容器,用于摄像头管理、系统监控、物联网设备集成、网络、存储等。这些容器可以组合在一起,创建功能强大的应用。图 2 显示了可用的微服务。
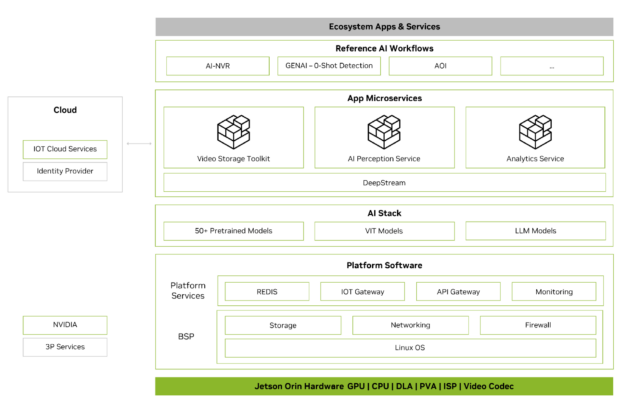
有关更多信息,请参阅适用于 Jetson 的 Metropolis 微服务白皮书。
将生成式 AI 应用与 Metropolis 微服务集成
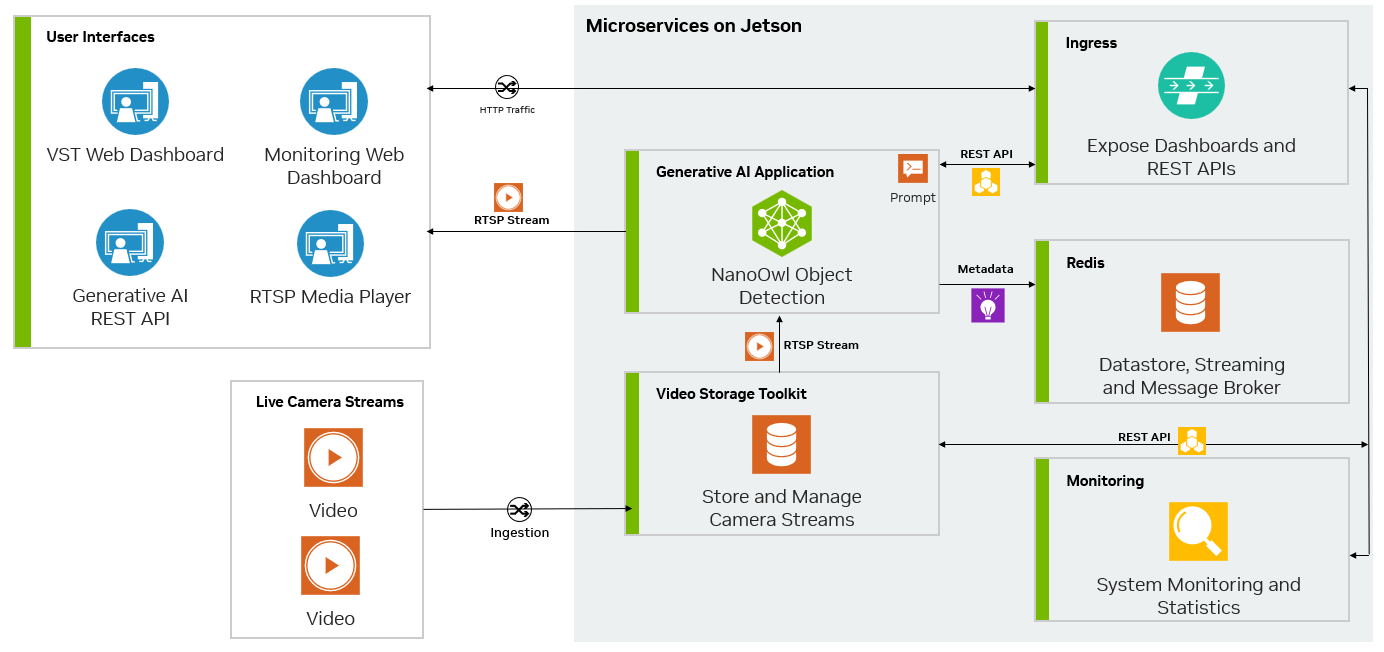
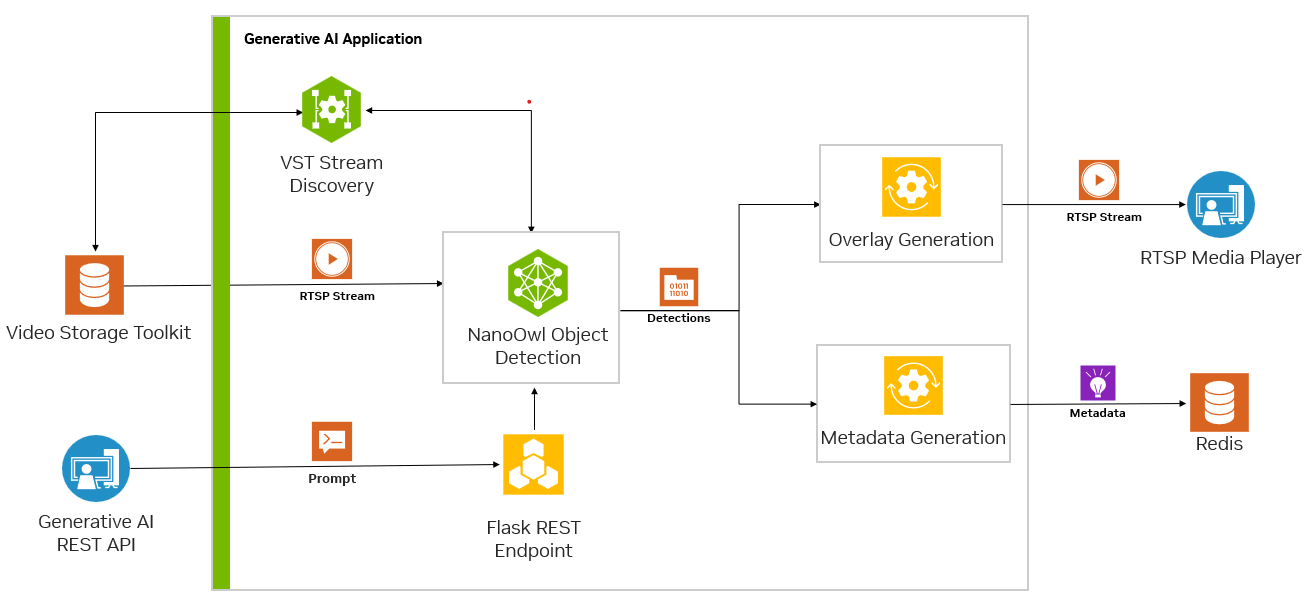
Metropolis 微服务和生成式 AI 可以结合使用,以利用几乎不需要训练或无需训练的模型。图 3 显示了 NanoOwl 参考示例图,该示例可用作在 Jetson 上使用 Metropolis 微服务构建生成式 AI 驱动的应用程序的一般方法。
使用 Metropolis 微服务定制应用程序
在 GitHub 上,您可以找到多种开源的生成式 AI 模型。其中一些模型经过优化,专为在 Jetson 平台上运行而设计。您可以在Jetson 生成式 AI 实验室上找到这些模型。
这些模型大多数都有许多共同点。作为输入,它们通常可以接受文本和图像。必须首先将这些模型加载到具有任何配置选项的内存中。然后,可以使用推理函数调用模型,在该函数中,图像和文本被传入以生成输出。
在 Python 参考示例中,我们使用 NanoOwl 作为生成式 AI 模型。但是,参考示例的一般方法几乎可以应用于任何生成式 AI 模型。
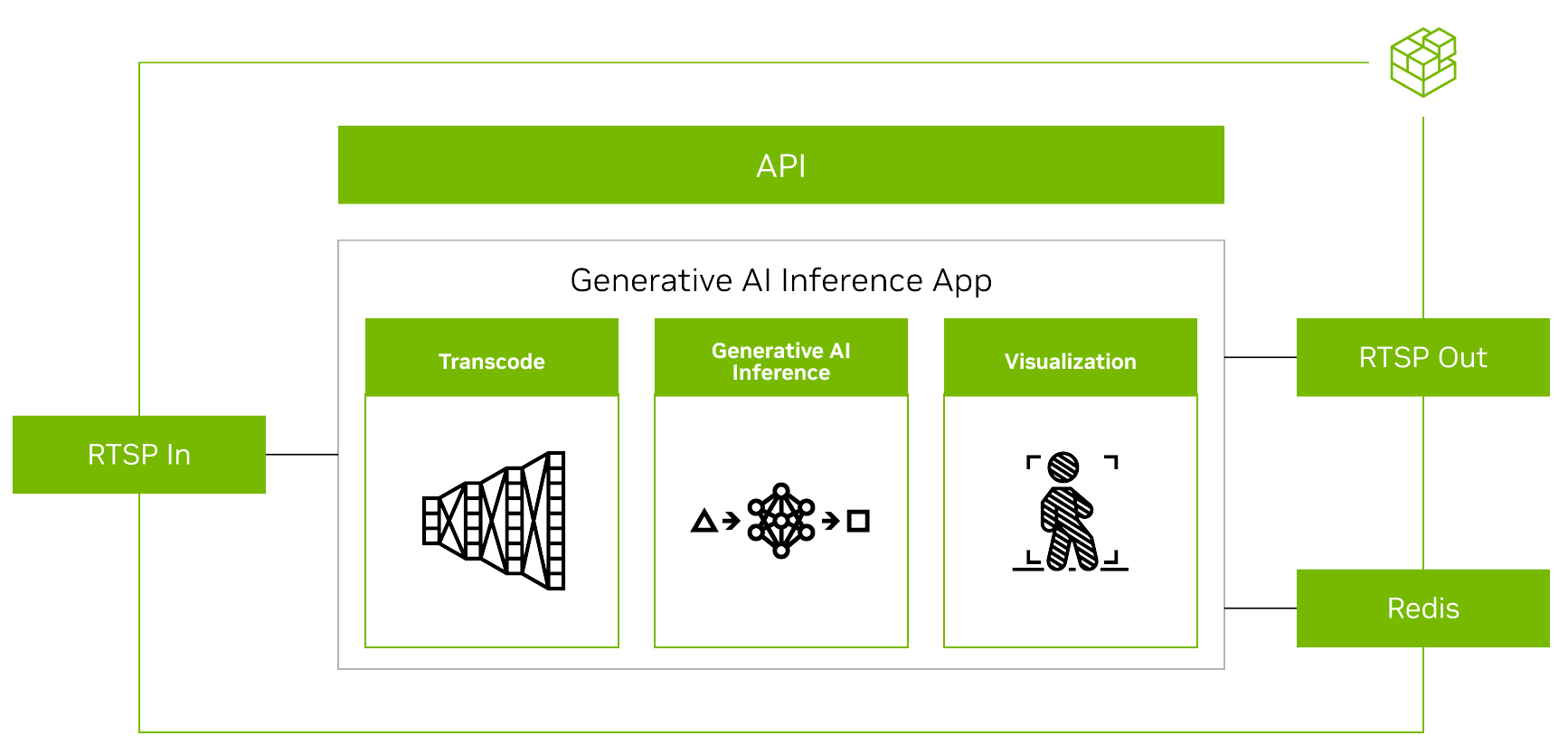
要使用 Metropolis 微服务运行任何生成式 AI 模型,您必须首先对齐其他微服务的输入和输出(图 4)。
在流式传输视频时,输入和输出均使用RTSP协议。RTSP从视频提取和管理微服务Video Storage Toolkit(VST)进行流式传输。输出通过覆盖的推理输出通过RTSP进行流式传输。输出元数据将发送到Redis流,其他应用程序可以在其中读取数据。欲了解更多信息,请观看使用Metropolis微服务的视频存储工具包演示视频。
其次,由于生成式 AI 应用程序需要一些外部接口(例如提示),因此您需要该应用程序接受 REST API 请求。
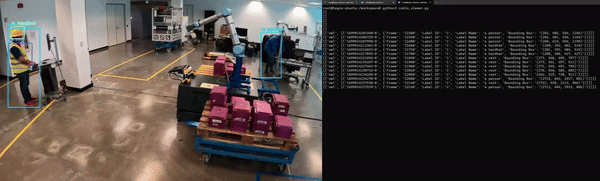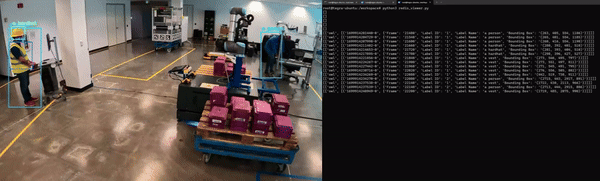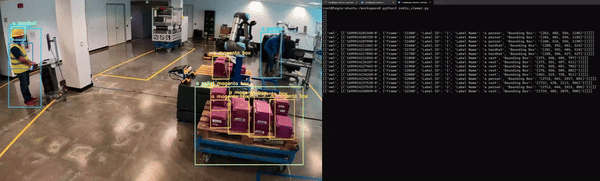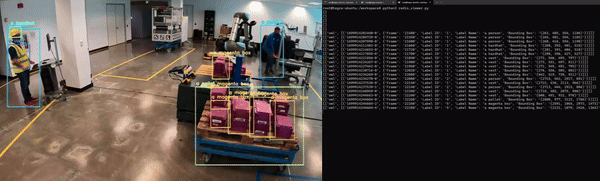
最后,应用程序必须经过容器化才能与其他微服务无缝集成。图 5 展示了 Redis 上 NanoOwl 物体检测和元数据输出的示例。
准备生成式 AI 应用程序
此参考示例使用 NanoOwl.但是,对于具有可从 Python 调用的加载和推理函数的任何模型,您都可以按照这些步骤进行操作。本文中展示了几个 Python 代码示例,以重点介绍如何将生成式 AI 与 Metropolis 微服务相结合的主要理念,但省略了一些代码以专注于常规 recipe.有关完整实现的更多信息,请参阅 /NVIDIA-AI-IOT/mmj_genai GitHub 项目。
要准备与 Metropolis 微服务集成的生成式 AI 模型,请执行以下步骤:
- 调用
predict模型推理的函数 - 使用
jetson-utils库。 - 使用 Flask 添加 REST 端点以提示更新。
- 使用
mmj_utils生成叠加。 - 使用
mmj_utils与 VST 交互以获取流。 - 使用
mmj_utils向 Redis 输出元数据。
调用模型推理的 predict 函数
NanoOwl 将生成式 AI 模型包装成OwlPredictor类。当此类实例化时,它会将模型加载到内存中。要对图像和文本输入进行推理,请调用predict函数来获取输出。
在这种情况下,输出是已检测对象的边界框和标签列表。
import PIL.Image
import time
import torch
from nanoowl.owl_predictor import OwlPredictor
image = PIL.Image.open("my_image.png")
prompt = ["an owl", "a person"]
#Load model
predictor = OwlPredictor(
"google/owlvit-base-patch32",
image_encoder_engine="../data/owlvit_image_encoder_patch32.engine"
)
#Embed Text
text_encodings = predictor.encode_text(text)
#Inference
output = predictor.predict(
image=image,
text=prompt,
text_encodings=text_encodings,
threshold=0.1,
pad_square=False)
大多数生成式 AI 模型都有类似的 Python 接口。有图像和文本输入,必须加载模型,然后模型可以从提示和图像中推理以获得一些输出。要引入自己的生成式 AI 模型,您可以将其包装在类中,并实现类似于OwlPredictor类。
使用 Jetson-utils 库添加 RTSP I/O
您可以使用 jetson-utils 库。该库提供了 videoSource 和 videoOutput,它们可以用来从 RTSP 流中捕获帧,并在新的 RTSP 流上输出帧的类别。
from jetson_utils import videoSource, videoOutput
stream_input = "rtsp://0.0.0.0:8554/input"
stream_output = "rtsp://0.0.0.0:8555/output"
#Create stream I/O
v_input = videoSource(stream_input)
v_output = videoOutput(stream_output)
while(True):
image = v_input.Capture() #get image from stream
output = predictor.predict(image=image, text=prompt, ...)
new_image = postprocess(output)
v_output.Render(new_image) #write image to stream
此代码示例从 RTSP 流中捕获帧,然后将其传递给模型推理函数。根据模型输出创建新图像,并将其渲染到输出 RTSP 流。
添加 REST 端点,以便使用 Flask 进行提示更新
许多生成式 AI 模型接受某种提示或文本输入。要使用户或其他服务能够动态更新提示,请添加 REST 端点以促使 Flask 接受提示更新并将其传递给模型。
为了更轻松地将 Flask 服务器与您的模型集成,请创建一个可调用的包装器类,使其能够在自己的线程中启动 Flask 服务器。有关更多信息,请参阅NVIDIA-AI-IOT/mmj_genai GitHub 项目。
from flask_server import FlaskServer
#Launch flask server and connect queue to receive prompt updates
flask_queue = Queue() #hold prompts from flask input
flask = FlaskServer(flask_queue)
flask.start_flask()
while(True):
...
if not flask_queue.empty(): #get prompt update
prompt = flask_queue.get()
output = predictor.predict(image=image, text=prompt, ...)
...
通过包含任何传入提示更新的队列连接您的主脚本和 Flask 端点。当 GET 请求发送到 REST 端点时,Flask 服务器会将更新的提示放在队列中。然后,您的主循环可以检查队列中是否有新的提示,并将其传递给模型,以便对更新的类进行推理。
使用 mmj_utils 生成叠加层
对于计算机视觉任务,可以看到模型输出的可视化叠加效果(图 6)。对于物体检测模型,您可以在输入图像上叠加模型生成的边界框和标签,以查看模型检测到每个物体的位置。

要执行此操作,请使用名为 DetectionGenerationCUDA 的函数,该函数来自 mmj_utils 库。此库依赖于 jetson_utils,它提供了用于生成叠加的 CUDA 加速函数。
from mmj_utils.overlay_gen import DetectionOverlayCUDA
overlay_gen = DetectionOverlayCUDA(draw_bbox=True, draw_text=True, text_size=45) #make overlay object
while(True):
...
output = predictor.predict(image=image, text=prompt, ...)
#Generate overlay and output
text_labels = [objects[x] for x in output.labels]
bboxes = output.boxes.tolist()
image = overlay_gen(image, text_labels, bboxes)#generate overlay
v_output.Render(image)
您可以使用DetectionGenerationCUDA类,通过指定关键字参数来调整文本大小、边界框大小和颜色,以满足您的需求。有关如何使用mmj_utils,请参考/NVIDIA-AI-IOT/mmj_utilsGitHub 库。
要生成叠加层,请调用对象并传递模型生成的输入图像、标签列表和边界框。然后,它会在输入图像上绘制标签和边界框,并返回带有叠加层的修改后的图像。然后,可以在 RTSP 流上渲染修改后的图像。
使用 mmj_utils 与 VST 交互以获取流
VST 可以帮助管理 RTSP 流,并提供一个良好的 Web UI 来查看输入和输出流。要与 VST 集成,可以直接使用 VST REST API,或者使用 mmj_utils 中的 VST 类,该类包含了 VST REST API 的接口。
从 VST 获取 RTSP 流链接,而不是在 Python 脚本中对 RTSP 输入流进行硬编码。此链接可能来自 IP 摄像头或通过 VST 管理的其他视频流源。
from mmj_utils.vst import VST
vst = VST("http://0.0.0.0:81")
vst_rtsp_streams = vst.get_rtsp_streams()
stream_input = vst_rtsp_streams[0]
v_input = videoSource(stream_input)
...
这将连接到 VST 并获取第一个有效的 RTSP 链路。可以在此处添加更复杂的逻辑,以连接到特定源或动态更改输入。
使用 mmj_utils 将元数据输出到 Redis
生成式 AI 模型生成 元数据,可供其他服务用于生成分析和见解。
在这种情况下,NanoOwl 会输出检测到的物体的边界框。您可以在 Metropolis 架构 中,通过分析 Redis 流中的数据来捕获这些信息。在 mmj_utils 库中,有一个辅助类可以帮助在 Redis 上生成检测元数据。
from mmj_utils.schema_gen import SchemaGenerator
schema_gen = SchemaGenerator(sensor_id=1, sensor_type="camera", sensor_loc=[10,20,30])
schema_gen.connect_redis(aredis_host=0.0.0.0, redis_port=6379, redis_stream="owl")
while True:
...
output = predictor.predict(image=image, text=prompt, ...)
#Output metadata
text_labels = [objects[x] for x in output.labels]
schema_gen(text_labels, bboxes)
您可以将SchemaGenerator包含输入摄像头流相关信息的对象并连接到 Redis.然后,可以通过传入模型生成的文本标签和边界框来调用该对象。检测信息将转换为 Metropolis Schema,并输出到 Redis 以供其他微服务使用。
应用程序部署
要部署应用程序,您可以设置 Ingress 和 Redis 等平台服务。然后,通过将自定义生成式 AI 容器与 VST 等应用程序服务相结合,docker compose.
主应用程序已准备好所有必要的 I/O 和微服务集成(图 7),您可以部署该应用程序并连接 Metropolis 微服务。
- 将生成式 AI 应用程序容器化。
- 设置必要的平台服务。
- 使用
docker compose. - 实时查看输出。
将生成式 AI 应用容器化
部署的第一步是使用 Docker 容器化生成式 AI 应用程序。
为了实现这一目标,一个简单的方法是利用jetson-containers项目。该项目提供了一个构建适用于Jetson平台的Docker容器的简易方案,这些容器能够支持机器学习应用,包括生成式AI模型。通过使用Jetson容器来创建包含必要依赖项的容器,随后可以进一步定制这些容器,以添加应用程序代码以及运行生成式AI模型所需的任何其他软件包。
有关如何为 NanoOwl 示例构建容器的更多信息,请参阅 src/readme GitHub 项目中的文件。
设置必要的平台服务
接下来,设置 Metropolis 微服务提供的必要平台服务。这些平台服务提供使用 Metropolis 微服务部署应用程序所需的许多功能。
此参考生成式 AI 应用仅需要 Ingress、Redis 和 Monitoring 平台服务。可以通过 APT 快速安装平台服务,并使用systemctl.
有关如何安装和启动必要平台服务的更多信息,请参阅适用于 Jetson 的 Metropolis 微服务快速入门指南。
使用 docker compose 启动应用程序
应用容器化和必要的平台服务设置完成后,您可以使用docker compose.
为此,创建一个docker-compose.yaml文件,该文件定义了要启动的容器以及任何必要的启动选项。在您定义docker compose文件,您可以使用docker compose up和 docker compose down命令。
有关 Docker 部署的更多信息,请查阅 GitHub 项目中的 /deploy/readme 文件。
实时查看输出
部署应用程序后,您可以通过 VST 添加 RTSP 流,并通过 REST API 与生成式 AI 模型交互,以发送提示更新,并通过查看 RTSP 输出实时查看检测变化。您还可以在 Redis 上看到元数据输出。
结束语
本文介绍了如何采用生成式 AI 模型并将其与适用于 Jetson 的 Metropolis 微服务集成。借助生成式 AI 和 Metropolis 微服务,您可以快速构建灵活准确的智能视频分析应用。
欲了解有关所提供服务的更多信息,请访问 适用于 Jetson 的 Metropolis 微服务产品页面。如需查看完整的参考应用以及有关如何自行构建和部署应用的更多详细步骤,请查阅 /NVIDIA-AI-IOT/mmj_genai GitHub 项目。