检索增强生成 (RAG) 应用程序如果能够处理各种数据类型,包括表格、图形和图表,而不仅仅是文本,其效用将会呈指数级增长。这就需要一个能够通过一致的解释文本、视觉和其他形式的信息来理解和生成响应的框架。
在本文中,我们将讨论应对多种模式和方法以构建多模态 RAG 工作流所面临的挑战。为保持讨论简洁,我们只关注两种模式,即图像和文本。
为什么多模态很难实现?
企业 (非结构化) 数据通常分布在多种模式下,无论是充满高分辨率图像的文件夹,还是包含混合文本表格、图表、图形等的 PDF 文件。
在使用这种模式时,需要考虑两个要点:每种模式都有自己的挑战,以及如何跨模式管理信息?
每种模式都有自己的挑战
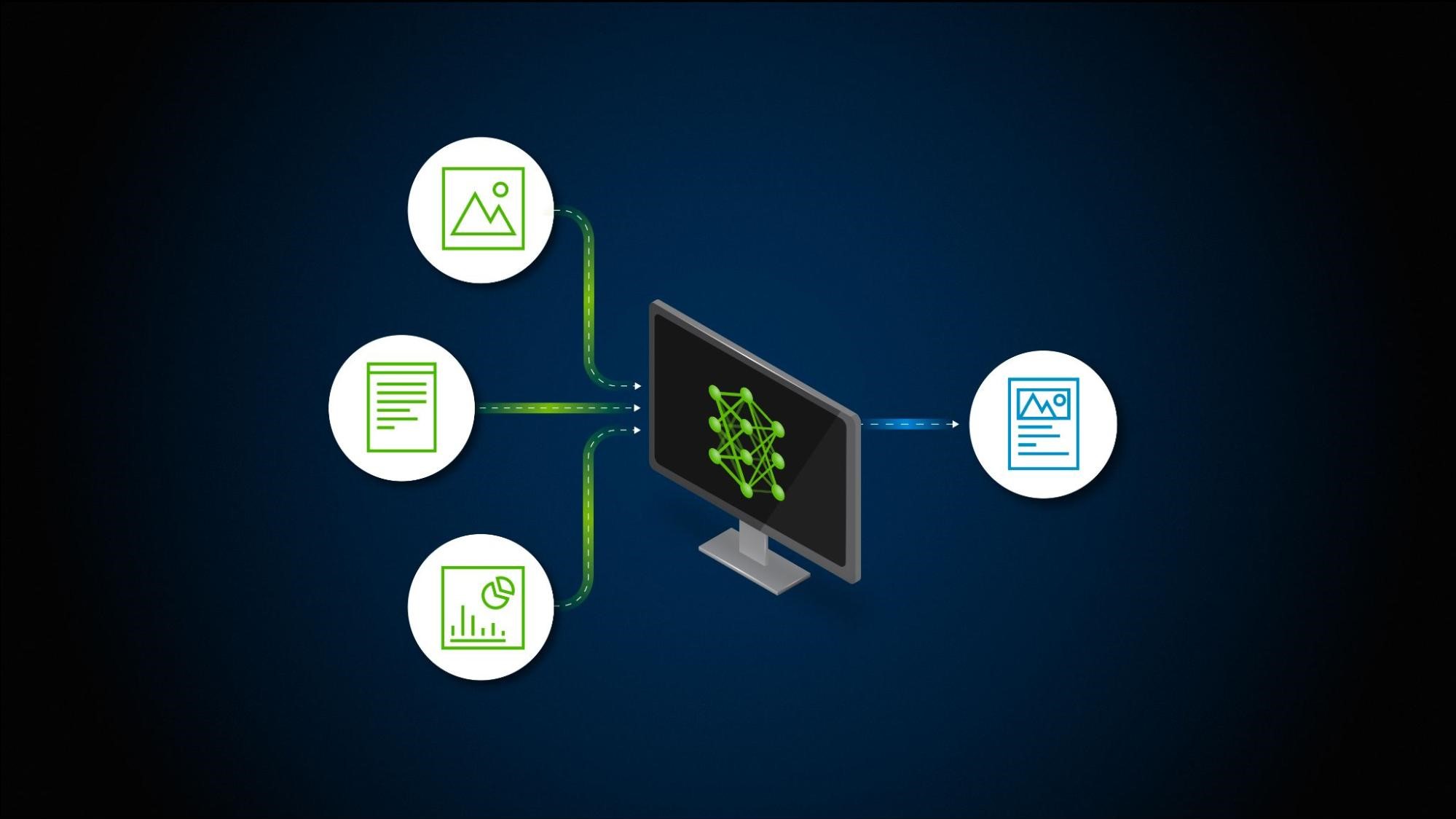
以图像为例 (图 1)。对于左侧的图像,重点更多的是一般图像,而不是微小的细节。只关注几个关键点,如池边、海洋、树木和沙滩。

报告和文档可能包含信息密集型图像 (如图表和图表),这些图像具有许多兴趣点和可从图像衍生的其他上下文。无论您构建何种工作流,都必须捕捉并解决这些细微差别,以有效嵌入信息。
如何跨模式管理信息?
另一个重要方面是跨不同模式表示信息。例如,如果您使用的是文档,则必须确保图表的语义表示与讨论同一图表的文本的语义表示保持一致。
多模态检索方法
我们已了解关键挑战,以下是构建 RAG 工作流以应对这些挑战的具体内容。
构建多模态 RAG 工作流的主要方法有以下几种:
- 将所有模式嵌入同一向量空间
- 将所有模式整合到一个主要模式中
- 为不同模式提供单独的商店
为使本次讨论保持简洁,我们仅讨论图像和文本输入。
将所有模式嵌入同一向量空间
对于图像和文本,您可以使用 CLIP 在同一向量空间中对文本和图像进行编码。这使得您可以在很大程度上使用相同的纯文本 RAG 基础设施,并交换嵌入模型以适应另一种模式。对于生成通道,您可以替换 大型语言模型(LLM),使用多模态 LLM (MLLM) 来处理所有问答。这种方法简化了管道,因为通用检索管道中唯一需要的更改是交换嵌入模型。
在这种情况下,我们的取舍是访问一个模型,该模型可以有效地嵌入不同类型的图像和文本,并捕获图像和复杂表格中的文本等所有复杂内容。
将所有模式整合到一个主要模式中
另一种选择是根据应用程序的重点选择主要模式,并将所有其他模式都接入主要模式。
例如,假设您的应用程序主要围绕基于文本的问答 (而非 PDF) 展开。在这种情况下,您通常会处理文本,但对于图像,您会在预处理步骤中创建文本描述和元数据。您还会存储图像以供日后使用。
然后,在推理通道中,检索主要从图像的文本描述和元数据开始,根据检索的图像类型,混合使用 LLM 和 MLLM 生成答案。
这样做的主要好处是,从信息丰富的图像中生成的元数据对于回答客观问题非常有帮助。这还可以解决调整用于嵌入图像的新模型的需求,以及构建重新排名器以对不同模式下的结果进行排名的需求。主要缺点是预处理成本和图像的一些细微差别。
为不同模式提供单独的商店
Rank-rerank 是一种方法,您可以为不同的模式维护单独的数据库,并查询所有数据库以检索 N 个结果。然后,让专用的多模态重排名器提供最相关的结果。
这种方法简化了建模过程,因此您不必对齐一个模型以使用多个模式。但是,它增加了重新排名器形式的复杂性,以安排 now – top-M*N块 (N来自M模式)。
用于生成的多模态模型
LLM 旨在理解和生成基于文本的信息。这些模型基于大量文本数据进行训练,能够执行一系列自然语言处理任务,如文本生成、总结、问答等。
MLLM 可以感知的不仅仅是文本数据。MLLM 可以处理图像、音频和视频等模式,这通常是真实数据的构成方式。它们将这些不同的数据类型结合起来,对信息进行更全面的解释,从而提高预测的准确性和可靠性。
这些模型可以执行各种任务:
- 视觉语言理解和生成
- 多模态对话
- 图片说明
- 视觉问答 (VQA)
在处理多种模式时,RAG 系统可以从这些任务中受益。要更深入地了解 MLLM 如何处理图像和文本,需要了解这些模型的构建方式。
MLLM 的一个热门子类型是 Pix2Struct,这是一种预训练的图像到文本模型,通过其新颖的预训练策略实现了对视觉输入的语义理解。顾名思义,这些模型能够生成基于图像提取的结构化信息。例如,Pix2Struct 模型可以从图表中提取关键信息,并以文本形式表示。
理解了这一点后,您可以在此处了解如何构建 RAG 管道。
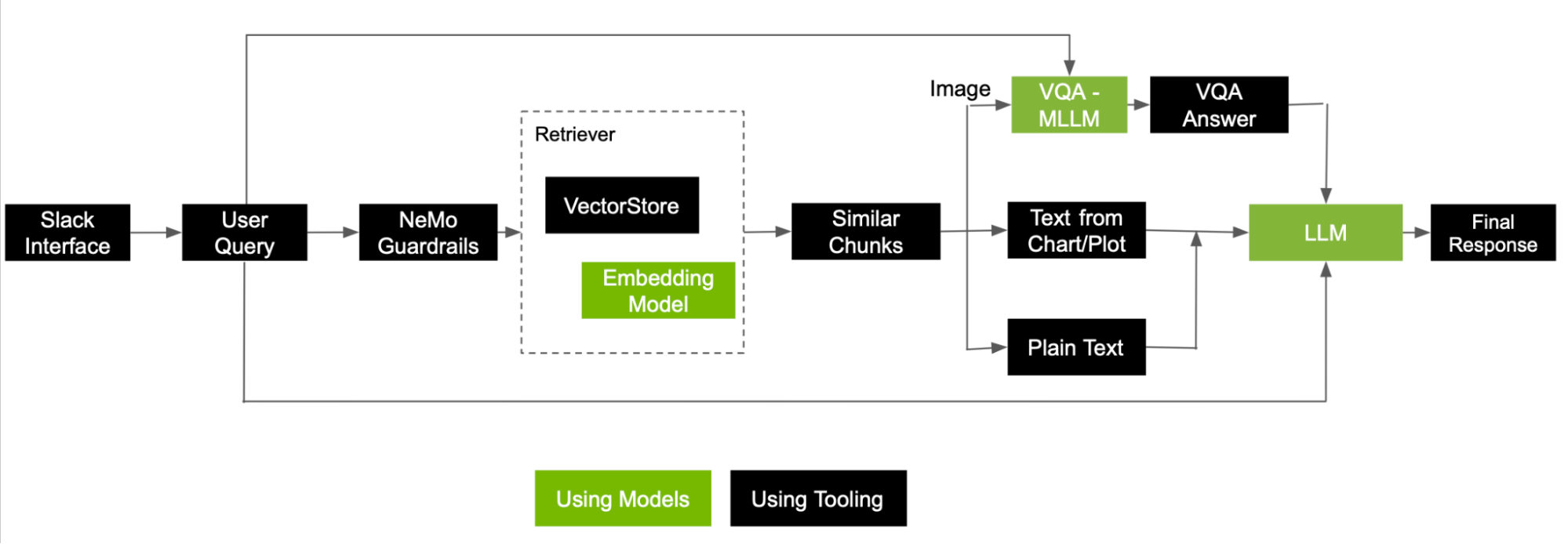
为多模态 RAG 构建管道
为了展示如何处理不同的数据模式,我们为您介绍了一个包含多个技术帖子索引的应用程序,例如 借助 NVIDIA H100 GPU 打破 MLPerf 训练记录. 本文包含复杂的图像,这些图像是包含丰富文本、表格数据的图表和图形,当然还有段落。
以下是您开始处理数据和构建 RAG 工作流之前所需的模型和工具:
- MLLM:用于图像字幕和视觉问答(VQA)。
- LLM: 一般推理和问答。
- 嵌入模型:将数据编码为向量。
- 向量数据库:存储已编码的向量以供检索。
解释多模态数据并创建向量数据库
构建 RAG 应用程序的第一步是预处理数据并将其存储为向量,以便您可以根据查询检索相关向量。
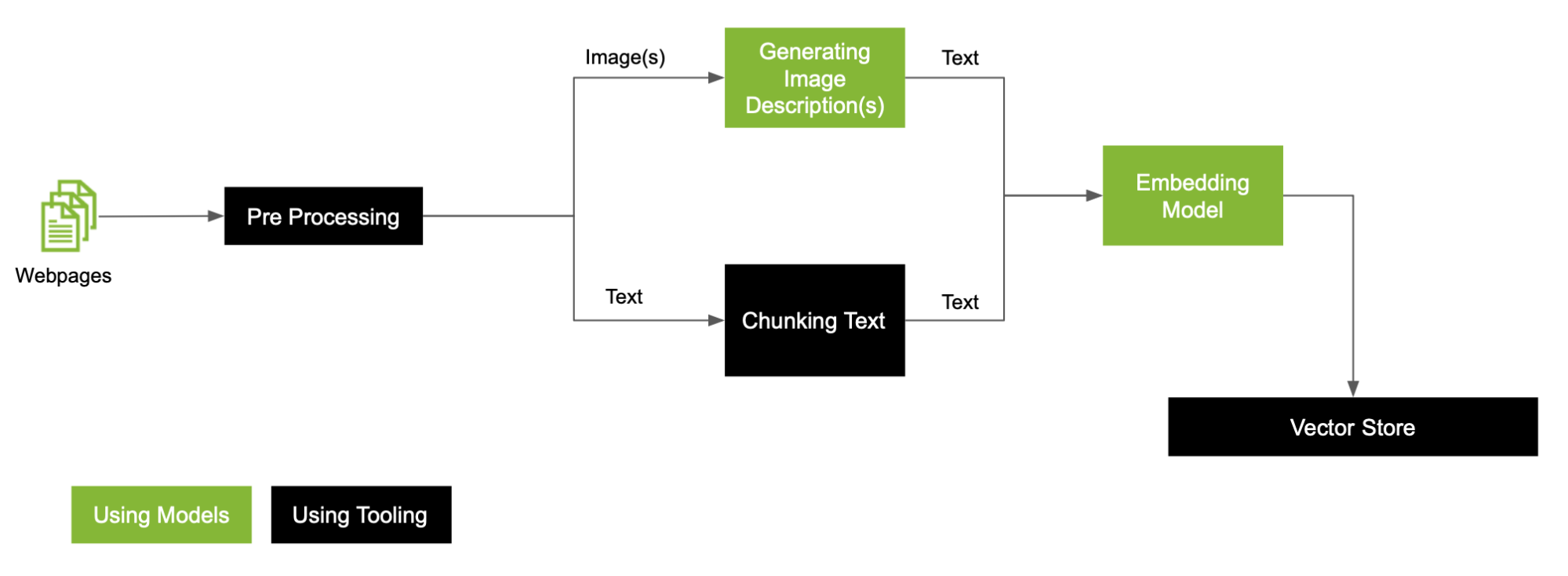
对于数据中存在的图像,这是一个通用的 RAG 预处理工作流 (图 2)。
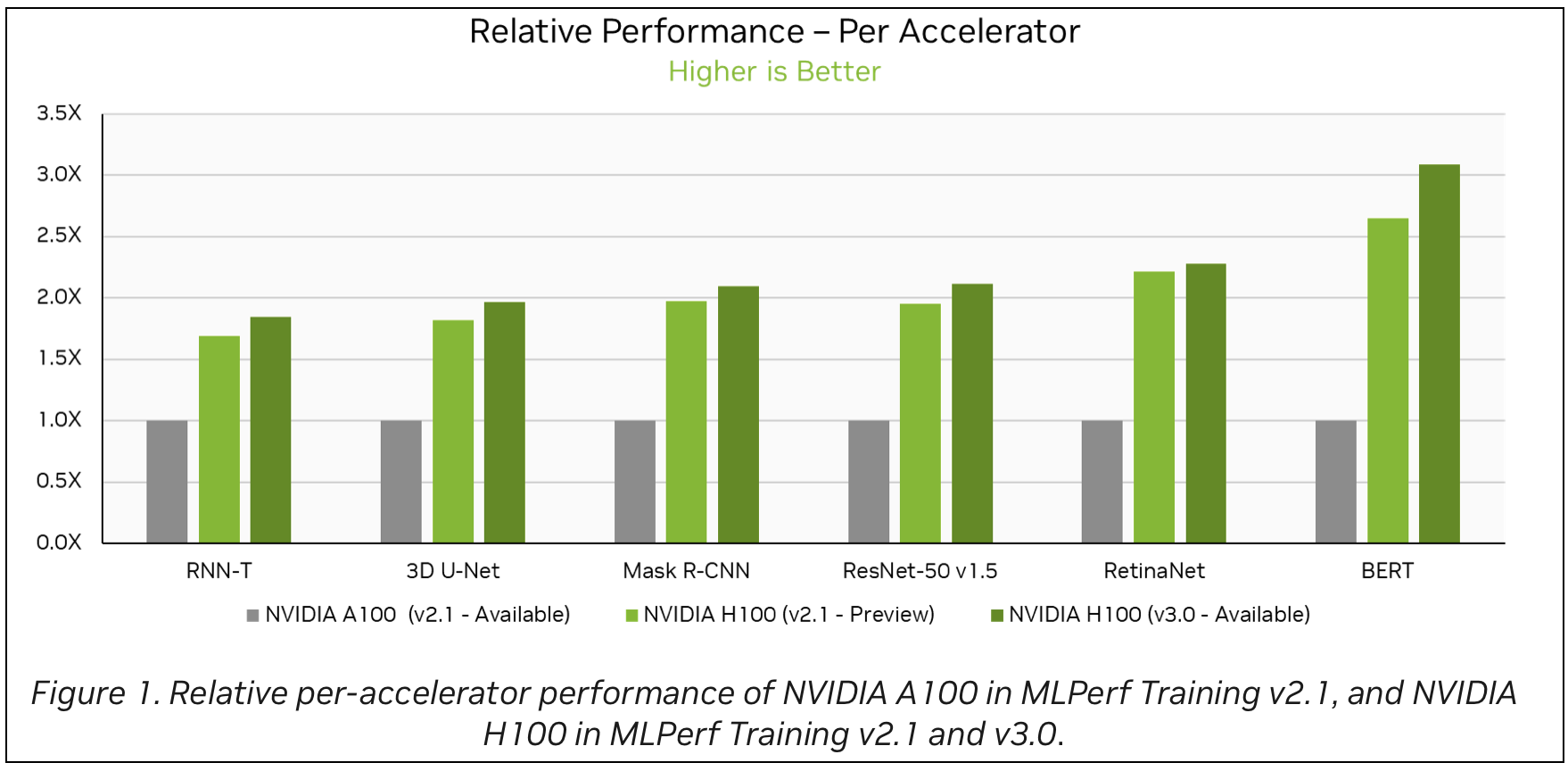
这篇博文包含几个条形图,如图 3 所示。要解释这些条形图,可以使用 Google 的 DePlot,这是一种视觉语言模型,能够与大型语言模型(LLM)结合,以理解和解释图表和图形。DePlot 模型可以在 NGC 上获取。
有关在 RAG 应用中使用 DePlot API 的更多信息,请参阅 使用优化的 DePlot 模型查询图形。
此示例专注于图表和图形。其他文档可能包含的图像可能需要模型自定义来处理专用图像,例如医学影像或原理图。这取决于用例,但您有几个选项可以解决图像中的这种差异:调整一个 MLLM 以处理所有类型的图像,或者为不同类型的图像构建模型集合。
为了简化解释,这是一个包含两个类别的简单集成案例:
在本文中,我们扩展了预处理工作流,以更深入地探讨如何处理工作流中的每种模式,这些模式利用自定义文本分割器、自定义 MLLM 和 LLM 来创建 VectorDB (图 4)。

以下是预处理工作流程中的一些关键步骤:
- 单独的图像和文本
- 根据图像类型,使用 MLLM 对图像进行分类
- 在 PDF 中嵌入文本
单独的图像和文本
目标是将图像打磨为文本模式。首先,提取和清理数据以分离图像和文本。然后,您可以继续处理这两种模式,最终将其存储在向量存储中。
根据图像类型,使用 MLLM 对图像进行分类
无论图像是否为图形,MLLM 生成的图像描述都可用于将图像分为类别。根据分类,对包含图形的图像使用 DePlot,以生成线性化的表格文本。此文本在语义上不同于普通文本,因此在推理期间执行搜索时,很难检索相关信息。
我们建议使用线性化文本的摘要作为块存储在向量存储中,并将自定义 MLLM 的输出作为元数据存储,以便您在推理期间使用。
在 PDF 中嵌入文本
您可以根据所处理的数据探索各种文本分割技术,以获得最佳 RAG 性能。为简单起见,请将每个段落存储为一个块。
与向量数据库对话
完成此流程后,您可以成功捕获 PDF 中存在的所有多模态信息。以下是用户提出问题时 RAG 流程的工作原理。
当用户向系统提示问题时,简单的 RAG 工作流会将问题转换为嵌入,并执行语义搜索以检索一些相关信息块。考虑到检索到的数据块也来自图像,请执行一些其他步骤,然后将所有数据块发送到 LLM 以生成最终响应。
图 5 展示了如何使用从图像和文本中检索的信息块处理用户查询以回答问题的参考流程。
这是一个示例问题,提示可以访问相关 PDF 的支持 RAG 的多模态机器人“ NVIDIA A100 和使用 3D U-Net 的 NVIDIA H100 (v2.1) 之间的性能差异是什么?”
该流程成功检索了相关图形图像,并准确解释了 NVIDIA H100 (v2.1),在 3D U-Net 基准测试中,每个加速器的相对性能比 NVIDIA A100 高出 80%。
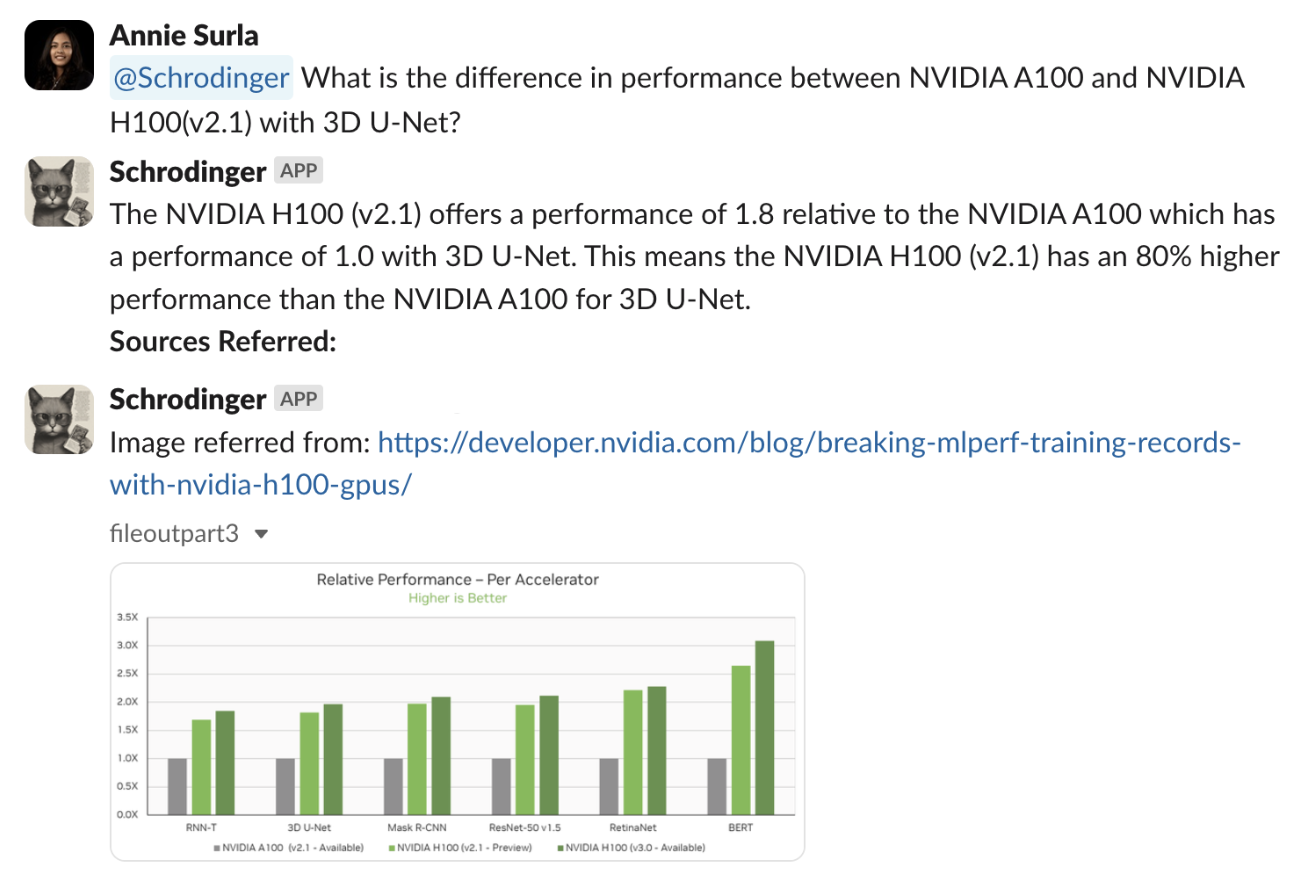
以下是在执行搜索并检索前五个相关数据块后处理问题所涉及的一些关键步骤:
- 如果从图像中提取数据块,MLLM 会将图像与用户问题一起作为输入,以生成答案。这不过是 VQA 任务。然后,生成的答案将用作 LLM 响应的最终上下文。
- 如果从图表或绘图中提取数据块,请调用存储为元数据的线性化表,并将文本作为上下文附加到 LLM。
- 最后,来自纯文本的数据块按原样使用。
所有这些数据块以及用户问题现已准备就绪,可供 LLM 生成最终答案。从图 6 中列出的来源来看,机器人参考了显示不同基准测试的相对性能的图表,以生成准确的最终答案。
扩展 RAG 管道
本文介绍了使用跨多种模式传播的数据回答简单文本问题的场景。为了进一步发展多模态 RAG 技术并扩展其功能,我们推荐以下研究领域。
解决涉及不同模式的用户问题
假设用户问题由包含图形和问题列表的图像组成,需要对流程进行哪些更改才能适应此类多模态请求?
多模态响应
基于文本的答案可能包含代表其他模式的引文,如图 6 所示。然而,对于用户查询来说,书面解释并不总是最佳结果类型。例如,可以进一步扩展多模态响应,根据请求生成图像,如堆叠条形图。
多模态代理
解决复杂的问题或任务不仅仅是简单的信息检索。这需要规划、专用工具和提取引擎。有关更多信息,请参阅 LLM 智能体简介。
总结
在生成式 AI 应用中,改进和探索未来多模态功能的空间仍然很大,这要归功于多模态模型以及对 RAG 驱动的工具和服务的需求不断增加。
如果企业能够将多模态功能集成到其核心运营和技术工具中,则可以更好地扩展其 AI 服务和产品,以用于待列出的用例。
获取实施 NVIDIA Omniverse 多模态 RAG 工作流程 的指导,该流程已在 GitHub 上发布。