NVIDIA는 최신 CUDA 툴킷 소프트웨어 릴리스인 12.0을 발표합니다. 이 릴리스는 수년 만에 처음으로 출시된 주요 릴리스로, 새로운 하드웨어 기능을 통한 새로운 프로그래밍 모델과 CUDA 애플리케이션 가속화에 중점을 두고 있습니다.
자세한 내용은 YouTube Premiere 웨비나, CUDA 12.0: 새로운 기능과 전망을 시청하세요.
이제 CUDA 맞춤형 코드, 향상된 라이브러리 및 개발자 도구를 통해 NVIDIA Hopper 및 NVIDIA Ada Lovelace 아키텍처에서 아키텍처 특정 기능 및 지침을 대상으로 할 수 있습니다.
CUDA 12.0에는 주요한 변경 사항 및 사소한 변경 사항이 모두 포함되어 있습니다. 모든 변경 사항이 여기에 나열된 것은 아니지만, 이 게시물에서는 주요 기능에 대한 개요를 제공합니다.
개요
- 더 높은 수준의 C 및 C++ API를 통한 새로운 PTX 지침 및 노출을 포함하여 모든 GPU에 대한 추가적인 프로그래밍 모델 개선 사항을 갖춘 새로운 NVIDIA Hopper 및 NVIDIA Ada Lovelace 아키텍처 기능 지원
- 개선된 CUDA 동적 병렬 처리 API 지원으로 기존 API에 비해 상당한 성능 향상 제공
- CUDA 그래프 API 개선 사항:
- 이제 기본 제공 함수를 호출하여 GPU 디바이스 측 커널에서 그래프 실행 일정을 예약할 수 있습니다. 이 기능을 사용하면 커널의 사용자 코드는 그래프 실행을 동적으로 예약할 수 있으므로 CUDA 그래프의 유연성을 크게 높일 수 있습니다.
- cudaGraphInstantiate API는 사용하지 않는 매개변수를 제거하도록 리팩터링되었습니다.
- GCC 12 호스트 컴파일러 지원
- C++ 20 지원
- JIT LTO용 CUDA 툴킷의 새로운 nvJitLink 라이브러리
- 라이브러리 최적화 및 성능 개선 사항
- Nsight Compute 및 Nsight Systems 개발자 도구 업데이트
- 최신 Linux 버전에 대한 지원 업데이트
자세한 내용은 CUDA 툴킷 12.0 릴리스 노트를 참조하세요. CUDA 툴킷 12.0을 다운로드할 수 있습니다.
NVIDIA Hopper 및 NVIDIA Ada Lovelace 아키텍처 지원
CUDA 애플리케이션은 새로운 GPU 제품군에서 스트리밍 멀티프로세서(SM) 수 증가, 메모리 대역폭 증가 및 클럭 속도 향상의 이점을 즉시 누릴 수 있습니다. CUDA 및 CUDA 라이브러리는 GPU 하드웨어 아키텍처 개선 사항을 기반으로 새로운 성능 최적화를 제공합니다.
CUDA 12.0은 NVIDIA Hopper 및 NVIDIA Ada Lovelace 아키텍처의 다양한 기능에 프로그래밍 가능한 기능을 제공합니다.
- 공개 PTX를 통한 많은 Tensor 작업 사용 가능
- TMA 작업
- TMA 일괄 작업
- Ultra xMMA(FP8 및 FP16 포함) 32배
- 실행 매개변수가 NVIDIA Hopper GPU의 membar 도메인 제어
- smem 동기화 장치 PTX 및 C++ API 지원
- CGA(Coperative Grid Array) 완화 장벽용 C 내부 기능 지원
- SM 멀티캐스트에 대한 프로그래밍 방식의 L2 캐시 지원(NVIDIA Hopper GPU만 해당)
- SIMT 집합용 공개 PTX 지원: elect_one
- 이제 유전체학 및 DPX 지침을 NVIDIA Hopper GPU에서 사용할 수 있어 더 빠른 결합 수학 산술 연산(three-way max, fused add+max 등)을 제공합니다.
지연 로딩
지연 로딩은 애플리케이션이 로딩이 필요할 때까지 커널과 CPU 측 모듈 모두의 로딩을 지연시키는 기술입니다. 기본값은 라이브러리를 처음 초기화할 때 모든 모듈을 선제적으로 로드합니다. 이를 통해 디바이스 및 호스트 메모리뿐만 아니라 알고리즘의 엔드 투 엔드 실행 시간도 크게 절약할 수 있습니다.
지연 로딩은 11.7 릴리스부터 CUDA에 포함되었습니다. 이후의 CUDA 릴리스에서 계속해서 이를 증강하고 확장했습니다. 애플리케이션 개발 관점에서는 지연 로딩을 선택할 때 특별한 것이 필요하지 않습니다. 기존 애플리케이션은 그대로 지연 로딩과 함께 작동합니다.
특히 지연 시간에 민감한 작업이 있다면 애플리케이션을 프로파일링할 수 있습니다. 지연 로딩과의 절충은 함수가 처음 로드되는 애플리케이션의 시점에서의 최소 지연 시간입니다. 이는 지연 로딩 없는 총 지연 시간보다 전반적으로 낮습니다.
| Metric | Baseline | CUDA 11.7 | CUDA 11.8+ | Improvement |
| End-to-end runtime [s] | 2.9 | 1.7 | 0.7 | 4x |
| Binary load time [s] | 1.6 | 0.8 | 0.01 | 118x |
| Device memory footprint [MB] | 1245 | 435 | 435 | 3x |
| Host memory footprint [MB] | 1866 | 1229 | 60 | 31x |
표 1. 지연 로딩을 통한 애플리케이션 속도 향상 예시
지연 로딩과 함께 사용되는 모든 라이브러리는 11.7 이상으로 구축해야 합니다.
이 릴리스에서는 기본적으로 CUDA 스택에서 지연 로딩이 활성화되어 있지 않습니다. 애플리케이션에 대해 평가하려면 환경 변수 CUDA_MODULE_LOADING=LAZY 세트와 함께 실행합니다.
호환성
CUDA 사소한 버전 호환성은 11.x에서 도입된 기능으로, 동일한 주요 릴리스에서 애플리케이션을 모든 사소한 버전의 CUDA 툴킷에 동적으로 연결할 수 있는 유연성을 제공합니다. 코드를 한 번 컴파일하면 동일한 주요 버전의 CUDA 툴킷의 모든 사소한 버전에서 라이브러리, CUDA 런타임 및 사용자 모드 드라이버에 동적으로 연결할 수 있습니다.
예를 들어 11.6 애플리케이션은 11.8 런타임 및 그 반대에 연결할 수 있으며 그 반대도 가능합니다. 이는 라이브러리 파일 내의 API 또는 ABI 일관성을 통해 이루어집니다. 자세한 내용은 CUDA 호환성을 참조하세요.
사소한 버전의 호환성은 CUDA 12.x에도 계속됩니다. 그러나 12.0은 새로운 주요 릴리스이므로 호환성을 통해 재설정이 보장됩니다. 11.x에서 사소한 버전 호환성을 사용한 애플리케이션은 12.0에 연결할 때 문제가 발생할 수 있습니다. 애플리케이션을 12.0에 다시 컴파일하거나 11.x에서 필요한 라이브러리에 정적으로 연결하여 개발 연속성을 보장합니다.
마찬가지로, 12.0에 다시 컴파일되거나 빌드된 애플리케이션은 향후의 12.x 버전과 연결되지만 CUDA 툴킷 11.x에서의 작동이 보장되지는 않습니다.
JIT LTO 지원
CUDA 12.0 툴킷에는 JIT LTO 지원을 위한 새로운 nvJitLink 라이브러리가 도입됩니다. NVIDIA는 이 기능의 드라이버 버전을 지원하지 않습니다. 자세한 내용은 사용되지 않는 기능을 참조하세요.
C++20 컴파일러 지원
CUDA 툴킷 12.0은 C++20 표준에 대한 지원이 추가됩니다. C++20은 다음 호스트 컴파일러 및 해당 최소 버전에 대해 활성화되어 있습니다.
- GCC 10
- Clang 11
- MSVC 2022
- NVC++ 22.x
- Arm C/C++ 22.x
기능에 대한 자세한 내용은 해당 호스트 컴파일러 설명서를 참조하세요.
대부분의 C++20 기능은 호스트 및 디바이스 코드에서 사용할 수 있지만 일부는 제한됩니다.
모듈 지원
번역 단위로 엔터티를 가져오고 내보낼 수 있는 새로운 방법으로 C++20에 모듈이 도입되었습니다.
CUDA 디바이스 컴파일러와 호스트 컴파일러 간의 복잡한 상호 작용이 필요하므로 CUDA C++에서 모듈은 호스트 또는 디바이스 코드에서 지원되지 않습니다. 모듈과 내보내기 및 가져오기 키워드 사용은 오류로 진단됩니다.
코루틴 지원
코루틴은 다시 시작 가능한 함수입니다. 실행이 일시 중단될 수 있으며 이 경우 제어 권한이 호출자에게 반환됩니다. 이후 코루틴의 호출은 중단된 지점에서 재개됩니다.
코루틴은 호스트 코드에서 지원되지만 디바이스 코드에서는 지원되지 않습니다. 디바이스 함수의 범위에서 co_await, co_yield 및 co_return 키워드의 사용은 디바이스 컴파일 중에 오류로 진단됩니다.
3방향 비교 연산자
3방향 비교 연산자(<=>)는 컴파일러가 다른 관계형 연산자를 합성할 수 있도록 지원하는 새로운 종류의 관계형 연산자입니다.
표준 템플릿 라이브러리의 유틸리티 함수와 긴밀하게 연결되어 있으므로 호스트 함수가 암시적으로 호출될 때마다 디바이스 코드에서의 사용이 제한됩니다.
연산자가 직접 호출되고 암시적 호출을 활성화할 필요가 없는 경우에 사용합니다.
Nsight 개발자 도구
Nsight 개발자 도구는 CUDA 툴킷 12.0과 함께 업데이트됩니다.
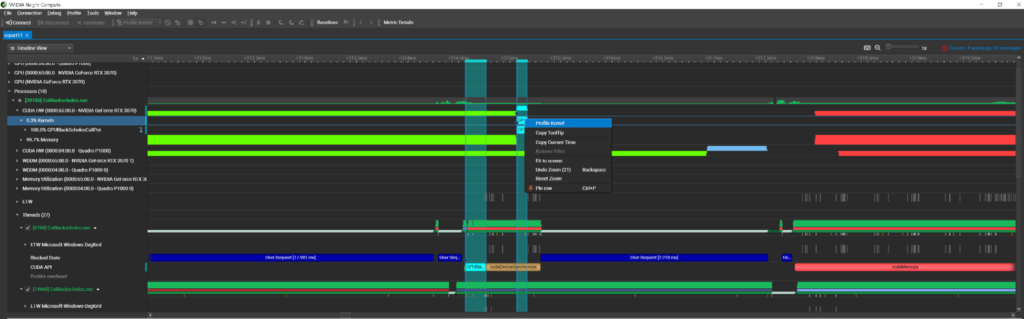
NVIDIA Nsight Systems 2022.5에 InfiniBand 스위치 메트릭 샘플링의 미리보기가 도입되었습니다. NVIDIA Quantum InfiniBand 스위치는 고대역폭과 짧은 저지연 통신을 제공합니다. Nsight Systems 타임라인에서 스위치 메트릭을 확인하면 애플리케이션의 네트워크 사용량을 더 잘 이해할 수 있습니다. 해당 정보를 사용하여 애플리케이션의 성능을 최적화할 수 있습니다.

Nsight 도구는 협업적으로 사용할 수 있도록 제작되었습니다. Nsight Systems의 성능 분석은 종종 Nsight Compute의 커널 활동에 대한 심층 분석을 제공합니다.
이 프로세스를 간소화하기 위해 Nsight Compute 2022.4에서는 Nsight Systems 통합이 도입됩니다. 해당 기능을 사용하면 시스템 추적 활동을 시작하고 Nsight Compute 인터페이스에서 보고서를 확인할 수 있습니다. 그런 다음 보고서를 검사하고 컨텍스트 메뉴에서 커널 프로파일링을 시작할 수 있습니다.
이 워크플로우를 사용하게 되면 두 개의 서로 다른 애플리케이션을 실행할 필요가 없습니다. 하나의 애플리케이션 내에서 모두 실행할 수 있습니다.
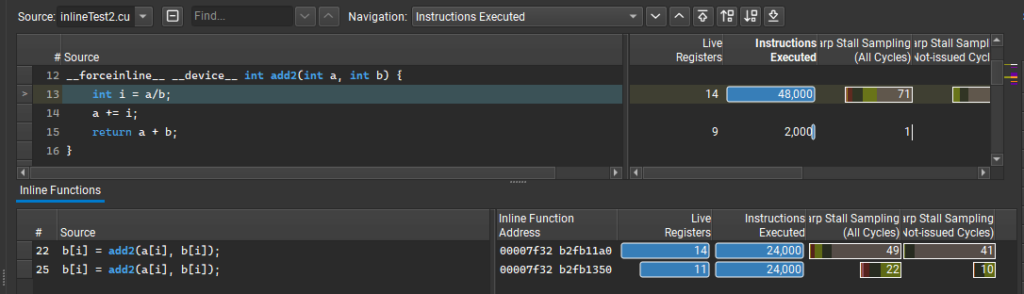
또한 Nsight Compute 2022.4에는 함수의 여러 내장 인스턴스에 대해 분할된 성능 메트릭을 제공하는 새로운 인라인 함수 테이블을 도입합니다. 많은 요청이 있었던 이 기능을 이용하면 함수가 일반적으로 성능 문제가 있는지 아니면 특정 인라인 상황에서만 발생하는지 파악할 수 있습니다.
또한 인라인이 발생하는 위치를 파악할 수 있으므로 이러한 수준의 세부 정보를 사용할 수 없을 때 종종 혼란을 야기할 수 있습니다. 주 소스 보기에서는 줄 당 수준에서 메트릭 집계를 계속 표시하며 표에는 함수가 인라인으로 표시된 여러 위치와 각 위치의 성능 메트릭이 나열됩니다.
또한 가속 구조 뷰어는 NVIDIA OptiX 곡선 프로파일링에 대한 지원을 포함하여 다양한 최적화 및 개선 사항을 제공받았습니다.
자세한 내용은 NVIDIA Nsight Compute, NVIDIA Nsight Systems, Nsight Visual Studio Code Edition을 참조하세요.
수학 라이브러리 업데이트
라이브러리에 추가된 모든 최적화 및 기능은 일반적으로 바이너리 크기의 형태로 비용이 발생합니다. 각 라이브러리의 바이너리 크기는 수명 주기 동안 서서히 증가했습니다. NVIDIA는 성능을 저하하지 않고 이러한 바이너리를 축소하기 위해 많은 노력을 기울였습니다. cuFFT는 CUDA 툴킷 11.8과 12.0 사이에서 50% 이상의 가장 큰 크기 감소를 보였습니다.
다음은 호출할 가치가 있는 몇 가지 라이브러리 특정 기능입니다.
cuBLAS
cuBLASLt는 새로운 FP8 데이터 유형으로 혼합 정밀도 곱셈 연산을 제공합니다. 이러한 작업은 또한 BF16 및 FP16 편향 융합뿐만 아니라 FP8 입력 및 출력 데이터 유형이 있는 GEMM에 대한 GELU 활성화 융합을 통한 FP16 편향을 지원합니다.
성능과 관련하여 FP8 GEMM은 A100의 BF16에 비해 H100 PCIe 및 SXM에서 각각 최대 3배 및 4.5배 더 빠를 수 있습니다. CUDA Math API는 새로운 FP8 행렬 곱셈 연산의 사용을 용이하게 하기 위해 FP8 변환을 제공합니다.cuBLAS 12.0은 API를 확장하여 64비트 정수 문제 크기, 선행 차원 및 벡터 증분을 지원합니다. 이러한 새로운 함수는 이름에 _64 접미사가 붙으며 해당 매개변수를 int64_t 선언하는 것을 제외하고는 32비트 정수와 동일한 API를 가집니다
cublasStatus_t cublasIsamax(cublasHandle_t handle, int n, const float *x, int incx, int *result);
64비트 정수 대응은 다음과 같습니다:
cublasStatus_t cublasIsamax_64(cublasHandle_t handle, int64_t n, const float *x, int64_t incx, int64_t *result);
cuBLAS는 성능이 가장 중요합니다. 64비트 정수 API로 전달된 인수가 32비트 범위에 맞으면 라이브러리는 32비트 정수 API를 호출하는 것과 동일한 커널을 사용합니다. 새 API를 시도하려면 int32_t 값에서 int64_t로의 C/C++ 자동 변환 덕분에 cuBLAS 함수에 _64 접미사를 추가하는 것처럼 간단해야 합니다.
cuFFT
계획 초기화 중에 cuFFT는 휴리스틱을 포함한 일련의 단계를 수행하여 커널 모듈 로드뿐만 아니라 사용되는 커널을 결정합니다.
CUDA 12.0부터 cuFFT는 바이너리 형식 대신 CUDA PTX(Parallel Thread eXecution) 어셈블리 형식을 사용하여 커널의 더 많은 부분을 제공합니다.
cuFFT 커널의 PTX 코드는 cuFFT 계획이 초기화될 때 런타임에 CUDA 디바이스 드라이버에 의해 바이너리 코드로 로드되고 컴파일됩니다. 새로운 구현으로 인해 제공되는 첫 번째 개선 사항을 통해 NVIDIA Maxwell, NVIDIA Pascal, NVIDIA Volta 및 NVIDIA Turing 아키텍처용 위한 수많은 새로운 가속 커널이 지원됩니다.
cuSPARSE
SpGEMM(sparse-sparse matrix multiplication)에 필요한 작업 공간을 줄이기 위해 NVIDIA는 메모리 사용량이 적은 두 개의 새로운 알고리즘을 출시합니다. 첫 번째 알고리즘은 중간 제품의 수에 대한 엄격한 제한을 계산하고 두 번째 알고리즘은 조각으로 연산을 분할할 수 있습니다. 이러한 새로운 알고리즘은 메모리 저장 공간이 적은 디바이스를 사용하는 고객에게 유용합니다.
INT8 지원이 cusparseGather, cusparseScatter 및 cusparseCsr2cscEx2에 추가되었습니다.
마지막으로 SpSV 및 SpSM의 경우 전처리 시간이 평균 2.5배 향상되었습니다. 실행 단계에서 SpSV는 평균 1.1배 향상되며 SpSM은 평균 3.0배 향상됩니다.
수학 API
새로운 NVIDIA Hopper 아키텍처에는 3-way max, fused add+max 등과 같은 결합 산술 연산을 더 빠르게 계산할 수 있는 새로운 유전체학 및 DPX 명령어가 함께 제공됩니다.
새로운 DPX 명령어는 동적 프로그래밍 알고리즘을 A100 GPU보다 최대 7배나 가속화합니다. 동적 프로그래밍은 복잡한 재귀 문제를 더 단순한 하위 문제로 세분화하여 해결하는 알고리즘 기술입니다. 더 나은 사용자 경험을 위해 이 지침은 이제 Math API를 통해 노출됩니다.
예: 3-way max + ReLU 연산, max(max(max(a, b), c), 0)
int __vimax3_s32_relu ( const int a, const int b, const int c )
자세한 내용은 NVIDIA Hopper GPU DPX 명령어를 사용한 동적 프로그래밍 성능 향상을 참조하세요.
이미지 처리 업데이트: nvJPEG
nvJPEG는 이제 GPU 메모리 설치 공간을 크게 줄이는 개선된 구현을 제공합니다. 이는 제로 카피 메모리 연산, 커널 융합 및 장소 내 색 공간 변환을 사용하여 수행됩니다.
요약
NVIDIA는 연구원, 과학자, 개발자가 단순화된 프로그래밍 모델을 통해 세계에서 가장 복잡한 AI/ML 및 데이터 사이언스 문제를 해결하도록 지원하는 데 계속해서 중점을 두고 있습니다.
이 CUDA 12.0 릴리스는 수년 만에 출시된 첫 번째 주요 릴리스이며 차세대 NVIDIA GPU 사용으로 애플리케이션을 가속화하는 데 도움이 되는 기초입니다. NVIDIA Hopper 및 NVIDIA Ada Lovelace 아키텍처의 새로운 아키텍처별 기능 및 지침은 이제 CUDA 맞춤형 코드, 향상된 라이브러리 및 개발자 도구를 통해 대상으로 지정할 수 있습니다.
CUDA 툴킷을 사용하면 GPU 가속 임베디드 시스템, 데스크톱 워크스테이션 엔터프라이즈 데이터센터, 클라우드 기반 플랫폼 및 HPC 슈퍼컴퓨터에서 애플리케이션을 개발, 최적화 및 배포할 수 있습니다. 이 툴킷에는 GPU 가속 라이브러리, 디버깅 및 최적화 도구, C/C++ 컴파일러, 런타임 라이브러리, 다양한 고급 C/C++ 및 Python 라이브러리에 대한 액세스가 포함됩니다.
자세한 내용은 다음 리소스를 참조하시기 바랍니다.