
생성형 AI는 텍스트 기반에서 멀티모달 모델로 발전해 왔으며, 최근에는 비디오 영역으로 확장되어 다양한 산업 분야에서 새로운 활용 가능성을 열어가고 있는데요. 비디오 모델은 사용자에게 새로운 경험을 제공하거나 대규모 자율 에이전트를 훈련하기 위한 시뮬레이션 시나리오를 생성할 수 있습니다. 이처럼 비디오 모델은 로봇 공학, 자율주행차, 엔터테인먼트 등 다양한 산업에서 혁신을 촉진하고 있습니다.
비디오 파운데이션 모델 개발에는 방대한 양의 비디오 데이터와 다양성이라는 고유 과제에 직면하게 됩니다. 이를 해결하려면 데이터를 정교하게 선별하고, 시간적·공간적 특성을 효과적으로 이해할 수 있도록 모델을 학습시키는 확장 가능한 파이프라인이 필수적입니다.
NVIDIA는 비디오 파운데이션 모델의 사전 훈련과 파인 튜닝을 지원하는 엔드투엔드 트레이닝 프레임워크, NVIDIA NeMo 프레임워크의 새로운 비디오 파운데이션 모델 기능을 발표했습니다. 이 프레임워크는 데이터의 고속 큐레이션, 효율적인 멀티모달 데이터 로딩, 확장 가능한 모델 트레이닝, 그리고 병렬화된 프레임워크 내 추론 기능을 제공합니다.
최적화된 파이프라인을 활용한 높은 처리량의 비디오 큐레이션
NeMo Curator는 비디오의 대규모 데이터 세트를 포함한 고품질 데이터를 효율적으로 처리하고 준비하여 생성형 AI 모델의 정확도를 높이는 역할을 합니다.
NeMo Curator의 확장 가능한 데이터 파이프라인을 사용하면 100PB 이상의 동영상을 효율적으로 스크랩하고, 주석을 달고, 필터링할 수 있습니다. 병목 현상을 제거하고 성능을 최적화하기 위해 NeMo Curator는 다음과 같은 기술 조합을 사용합니다:
NeMo Curator의 자동 밸런싱 기술은 다양한 유형의 GPU가 포함된 이기종 클러스터를 활용하여 L40S GPU의 NVENC와 H100 및 GB200 GPU의 성능을 효과적으로 극대화합니다.
그림 1은 NeMo Curator가 2,000만 시간 분량의 비디오 데이터를 처리하면서, 처리 시간을 수년에서 단 며칠로 단축한 과정을 보여줍니다. 또한, ISO 전력 사용량 기준으로 최적화되지 않은 CPU 기반 파이프라인에 비해 1,000개의 GPU를 사용해 처리 속도를 89배 향상시킨 결과도 확인할 수 있습니다.

NeMo Curator는 비디오 파운데이션 모델 훈련과 데이터 세트 파인 튜닝을 위해 다음과 같은 관련 파이프라인을 제공합니다:
- 클리핑(Clipping)
- 샤딩(Sharding)
클리핑 파이프라인은 프레임 간 색상 변화를 분석하여 원본 비디오를 디코딩하고 짧고 연속적인 클립으로 분할하는 것으로 시작됩니다. 스티칭 단계에서는 이미지 임베딩 유사성을 사용하여 인접한 클립을 병합하여 클립을 매끄럽게 다듬습니다. 그런 다음 클립은 고품질 비디오 인코딩(H264)으로 트랜스코딩되고, 의미 검색 기능을 용이하게 하기 위해 기존 또는 합성적으로 생성된 비디오 임베딩 및 캡션으로 주석이 추가됩니다.

샤딩은 캡션에 대한 텍스트 임베딩을 생성하여 학습에 사용되는 최종 웹 데이터세트를 생성합니다. 또한 NeMo Curator는 레이 스트리밍을 사용하여 자동 밸런싱 시스템을 구축하고 파이프라인의 각 단계에 최적의 작업자 수를 배치하여 어떤 단계에서도 병목 현상이 발생하지 않도록 합니다(그림 3).

효율적인 멀티모달 데이터 로딩
비디오 모델은 수십억 개의 이미지와 수백만 개의 비디오로 학습할 수 있으므로 학습 시간 동안 높은 처리량을 달성하기 위한 효율적인 데이터 로딩 전략이 필요합니다.
이는 NeMo 프레임워크에서 Megatron-Energon 데이터 로더를 사용하여 달성할 수 있습니다:
- 대규모 데이터 샤딩: WebDataset 형식을 사용하여 TB 크기의 데이터 세트를 압축 파일로 샤딩하여 학습 중 I/O 오버헤드를 줄입니다.
- 결정론적 저장 및 로드: 훈련 작업이 중단될 때 반복 없이 한 번에 데이터세트를 방문할 수 있도록 하여 다양한 훈련 클러스터 설정에서 일관성을 보장합니다.
- 시퀀스 패킹: 다양한 길이 또는 해상도의 이미지와 비디오를 최대 시퀀스 길이까지 함께 패킹하여 패딩으로 인한 컴퓨팅 낭비를 최소화하는 동시에 데이터 로딩 로직을 간소화합니다. NeMo는 트랜스포머 엔진의 특수 THD 어텐션 커널을 사용하여 시퀀스 패킹으로 가속화된 훈련을 지원합니다.

- 네트워크 대역폭 부담 감소: 각 모델 병렬 순위는 전체 데이터 세트 대신 서로 다른 데이터 하위 집합을 다운로드한 다음 순위 전체에 걸쳐 데이터를 모두 수집하여 동일한 데이터 로더를 얻습니다.

비디오 파운데이션 모델 훈련 확장하기
비디오 파운데이션 모델은 자동 회귀 모델 또는 확산 모델일 수 있습니다.
거대 언어 모델(LLM)에서 잘 확립된 NeMo 도구 제품군을 자동 회귀 모델에 재사용할 수 있으며, DiT, MovieGen 및 최신 NVIDIA Cosmos 월드 파운데이션 모델과 같은 확산 변환기에 대한 지원이 새로 추가되었습니다.
NeMo 기술 스택은 고도로 최적화되어 최신 벤치마크에서 40% 이상의 모델 플롭스 활용률(MFU)을 제공합니다(표 1).
| 모델 규모 | 컨텍스트 길이 | 트레이닝 구성 | 사용된 GPU (TFLOPS/s) | 처리량(token/s/GPU) |
| DiT 7B | 8k | baseline, no optimization | OOM | |
| DiT 7B | 8k | CP=2 | 457 | 8,969 |
| DiT 7B | 74k | TP=4 SP CP=4 | 414 | 2,933 |
| DiT 28B | 8k | TP=2 SP PP=2 | 435 | 2,392 |
| DiT 28B | 74k | TP=8 SP CP=4 PP=4 | 411 | 994 |
표 1. 확산 변압기(DiT)에서의 NVIDIA NeMo 프레임워크에 대한 GPU 사용률 및 처리량 벤치마크
범례: CP=컨텍스트 병렬 처리, TP=텐서 병렬 처리, SP=시퀀스 병렬 처리, PP=파이프라인 병렬 처리
비디오 확산 파이프라인 개요
비디오 확산 훈련 파이프라인은 일반적으로 다음과 같은 주요 단계로 구성됩니다:
- 인과적 시간적 3D 토큰화기로 입력 이미지와 비디오를 토큰화하여 3D 시공간적 토큰을 생성합니다.
- 확산 노이즈 스케줄 타임스텝 t와 텍스트 입력에 따라 조건이 지정된 트랜스포머 디코더를 사용합니다.
- 타임스텝 컨디셔닝은 적응형 레이어 정규화(AdaLN) 메커니즘을 통해 적용되며, 훈련 중 모델 플롭 활용도(MFU)를 더욱 향상시키는 AdaLN-LoRA를 사용할 수 있는 옵션이 있습니다.
- 텍스트 컨디셔닝은 각 트랜스포머 블록의 크로스 어텐션 레이어를 통해 적용됩니다.
- NeMo 프레임워크를 사용하면 표준 DiT 아키텍처 또는 그룹화된 쿼리 어텐션(GQA)를 사용하는 MovieGen Llama 아키텍처를 기반으로 트랜스포머 디코더를 초기화할 수 있습니다.
- 디퓨전 트랜스포머의 노이즈 예측을 사용하여 병렬화된 EDM 디퓨전 파이프라인으로 디퓨전 손실을 계산합니다.
NeMo는 또한 확산 학습을 안정화하기 위해 어텐션 블록 전에 쿼리와 키에 추가 RMSNorm(Root Mean Square Layer Normalization)을 적용합니다. 텐서 병렬 처리와 호환성을 유지하기 위해 어텐션 헤드별로 RMSNorm이 적용됩니다.

비디오 확산 모델을 위한 병렬 처리 최적화
NeMo와 Megatron-Core는 다양한 모델 병렬 처리 기법을 지원합니다:
- 텐서 병렬(TP)
- 시퀀스 병렬(SP)
- 파이프라인 병렬(PP)
- 컨텍스트 병렬(CP)
하지만 이러한 기법을 비디오 확산 변환기에 적용하면 특유의 문제가 발생할 수 있습니다. NeMo는 이러한 문제를 해결하며, 확장성과 높은 성능을 갖춘 훈련을 가능하게 합니다. 그 방법은 다음과 같습니다:
- 컨디셔닝을 위한 효율적인 파이프라인 병렬 처리
- 시공간적 DiT(ST-DiT) 아키텍처 지원
- 맞춤형 랜덤 시딩 메커니즘
기존 접근 방식은 파이프라인 단계 간에 컨디셔닝 정보를 전달해야 해서 통신 비용이 늘어나고, 파이프라인 일정을 크게 변경해야 하는 단점이 있습니다. NeMo는 각 파이프라인 단계에서 조건부 임베딩을 직접 계산해 이 문제를 해결합니다. 조건부 임베딩 계산에 필요한 효율적인 파이프라인 병렬 처리는 통신 비용보다 훨씬 적은 자원을 소모하며, 결과적으로 훈련 처리 속도를 높입니다.

시공간적 DiT(ST-DiT) 아키텍처는 긴 비디오 시퀀스에 대한 완전한 셀프 어텐션 학습의 대안으로 각 트랜스포머 블록에 추가 공간 및 시간적 셀프 어텐션 레이어를 도입합니다. 이 접근 방식은 이러한 레이어에 대한 짧은 입력 시퀀스에 대한 컴퓨팅이 작기 때문에 컨텍스트 병렬 처리 중에 통신 오버헤드가 노출됩니다. NeMo는 공간/시간적 어텐션을 위해 A2A 통신과 함께 로컬 어텐션 계산을 사용하는 동시에 완전한 셀프 어텐션을 위해 P2P 링 토폴로지를 유지함으로써 이 문제를 해결합니다. 이 하이브리드 접근 방식은 시간적/공간적 어텐션에 필요한 대역폭을 효과적으로 줄이면서도 전체 셀프 어텐션 레이어에 대한 컨텍스트 병렬 처리의 이점을 누릴 수 있습니다(표 2).

Figure 8. Spatial-temporal DiT transformer block
| 레이어 | 입력 시퀸스 | 통신 프리미티브 | 통신 대역폭 |
| 시간적 셀프 어텐션 (Temporal self-attention) | 짧은 시퀀스 | 로컬 컴퓨팅 및 A2A | (bhw/cp, t, d) |
| 공간적 셀프 어텐션 (Spatial self-attention) | 짧은 시퀀스 | 로컬 컴퓨팅 및 A2A | (bt/cp, hw, d) |
| 전체 어텐션 (Full attention) | 긴 시퀀스 | P2P 포함 CP | (b, h*w*t/cp, d) |
범례: b=배치 크기, hw=공간 크기, t=시간 크기, cp=컨텍스트 병렬 크기, d=숨겨진 크기, 입력 크기는 (b, th*w, d)입니다.
사용자 맞춤형 무작위 시드 메커니즘의 목표는 다음 구성 요소에서 무작위 시드가 올바르게 초기화되도록 하는 것입니다:
- 타임 스텝(Time step)
- 가우시안 노이즈(Gaussian noise)
- 실제 모델 가중치(The actual model weights)
표 3은 NeMo의 초기화 전략을 보여줍니다.
| RNG 시드 | 데이터 병렬 | 컨텍스트 병렬 | 파이프라인 병렬 | 텐서 병렬 |
| 타임 스텝 (t) | 차이 | 동일 | 동일 | 동일 |
| 가우시안 노이즈 | 차이 | 차이 | 동일 | 동일 |
| 가중치 초기화 | 동일 | 동일 | 차이 | 차이 |
표 3. 병렬화된 확산 트랜스포머를 위한 맞춤형 랜덤 시딩
범례: 차이=다른 병렬 순위와 다른 랜덤 시드, 동일=다른 병렬 순위와 동일한 랜덤 시드.
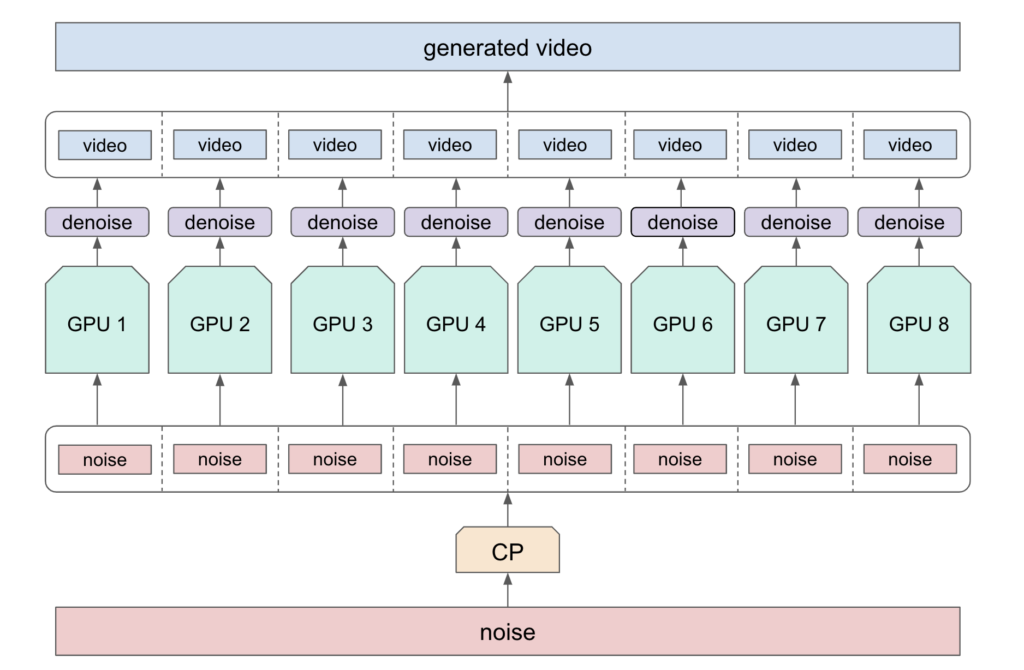
효율적인 프레임워크 내 추론
NeMo 프레임워크는 컨텍스트 병렬화를 활용해 노이즈 제거 작업을 여러 GPU에 분산 처리하며, 이를 통해 추론 속도를 크게 향상시킵니다. 병렬로 처리된 노이즈 제거 작업이 완료되면 잠재 텐서를 결합해 비디오 시퀀스를 재구성하고, 이를 Cosmos 비디오 토큰화기를 사용해 디코딩합니다.
벤치마크 결과에 따르면, 최대 32개의 H100 GPU를 사용할 때 80~90%의 확장 효율성을 보였으며, FP8 멀티 헤드 어텐션은 GPU 1개 사용 시 28%, 32개 사용 시 48%의 성능 향상을 달성했습니다.

결론
이 게시물에서는 비디오 파운데이션 모델을 효과적이고 효율적으로 사전 훈련하거나 파인 튜닝하는 데 유용한 NVIDIA NeMo 프레임워크의 주요 기능들을 소개했습니다.
NeMo Curator는 클리핑 및 샤딩 파이프라인을 통해 대규모 데이터를 빠르고 효율적으로 큐레이션할 수 있도록 지원하며, Megatron Energon 라이브러리는 멀티모달 데이터 로딩을 최적화해줍니다. 또한 NeMo 프레임워크는 확산 및 자동 회귀 모델에 특화된 다양한 모델 병렬 처리 기법을 통해 대규모 비디오 파운데이션 모델의 확장 가능한 학습을 가능하게 합니다. 이와 더불어, 노이즈 제거 작업을 여러 GPU에 분산하고 FP8 멀티 헤드 어텐션을 활용해 프레임워크 내 추론 효율성을 극대화합니다.
NeMo Curator 얼리 액세스 프로그램을 통해 비디오 데이터를 큐레이팅하고 토큰화하며, 사전 훈련(확산, 자동 회귀), 파인 튜닝(확산, 자동 회귀), 멀티 GPU 인프레임워크 추론(확산, 자동 회귀)을 수행할 수 있는 NeMo 프레임워크를 지금 바로 사용해 보세요.
또한 build.nvidia.com에서 NVIDIA Cosmos 월드 파운데이션 모델을 체험해 볼 수 있으며, NVIDIA CEO 젠슨 황의 CES 키노트를 시청하여 NVIDIA Cosmos 월드 파운데이션 모델 플랫폼에 대해 자세히 알아볼 수 있습니다.
감사의 말
도와주신 모든 분들께 감사드립니다: Parth Mannan, Xiaowei Ren, Zhuoyao Wang, Carl Wang, Jack Chang, Sahil Jain, Shanmugam Ramasamy, Joseph Jennings, Ekaterina Sirazitdinova, Oleg Sudakov, Linnan Wang, Mingyuan Ma, Bobby Chen, Forrest Lin, Hao Wang, Vasanth Rao Naik Sabavat, Sriharsha Niverty, Rong Ou, Pallab Bhattacharya, David Page, Jacob Huffman, Tommy Huang, Nima Tajbakhsh, Ashwath Aithal.
관련 리소스
GTC 세션: Babit 멀티미디어 프레임워크를 사용한 차세대 클라우드 비디오 처리 파이프라인 구축하기
GTC 세션: 파운데이션 모델 살펴보기: AI 발전의 기둥
NGC 컨테이너: NeMo 프레임워크
SDK: NVIDIA NeMo 커스터마이저
SDK: NeMo 프레임워크
SDK: NeMo Retriever