
ネットワーク トラフィックのリアルタイム処理では、GPU が提供する高度な並列性を活用することができます。この種のアプリケーションでは、パケットの取得や送信を最適化することで、ボトルネックを回避し、全般にわたって高速ネットワークに対応することを可能にします。この流れにおいて、DOCA GPUNetIO は 、CPU の介入なしにネットワークや演算タスクを実行できる独立したコンポーネントとして GPU を推進しています。
この記事では、NVIDIA DOCA GPUNetIO が低遅延で、パフォーマンスを最大化するために統合された、異なる、そして関連性のないコンテキストに焦点を当てた GPU パケット処理アプリケーションのリストを提供します。
NVIDIA DOCA GPUNetIO API
NVIDIA DOCA GPUNetIO は、NVIDIA DOCA ソフトウェア フレームワークと共にリリースされた新しいライブラリの 1 つです。DOCA GPUNetIO ライブラリは、1 つまたは複数の CUDA カーネルを通じて、NIC と GPU 間の直接的な通信を可能にします。これにより、CPU がクリティカル パスから取り除かれます。
DOCA GPUNetIO ライブラリの CUDA デバイス関数を使用することで、CUDA カーネルは CPU コアやメモリを消費せずに GPU との間で直接パケットを送受信することができます。このライブラリの主な特徴は以下のとおりです:
- GPUDirect Async Kernel-Initiated Network (GDAKIN): イーサネット上の通信。GPU (CUDA カーネル) はネットワーク カードと直接やりとりし、CPU の介入なしに GPU メモリ内でパケットを送受信できます (GPUDirect RDMA)。
- GPU メモリ公開: CUDA の基本的なメモリ割り当て機能と GDRCopy ライブラリを 1 つの関数内で組み合わせることで、CUDA API を使用せずに GPU メモリ バッファを CPU から直接アクセス (読み取りまたは書き込み) できるようになります。
- 正確な送信スケジューリング: GPU から、将来のパケットバーストの送信をスケジューリングし、タイムスタンプを関連付け、その情報をネットワーク カードに提供することができます。
- セマフォ: 異なる CUDA カーネル間、または CUDA カーネルと CPU スレッド間で情報を共有し、同期するための便利なメッセージ パッシング オブジェクトです。
DOCA GPUNetIO の原理と利点の詳細については、NVIDIA DOCA GPUNetIO によるインライン GPU パケット処理をご覧ください。DOCA GPUNetIO API の詳細については、DOCA GPUNetIO SDK プログラミング ガイドを参照してください。

ライブラリと共に、以下の NVIDIA DOCA アプリケーションと NVIDIA DOCA サンプルは、ライブラリが提供する関数や機能の使用方法を示しています。
- NVIDIA DOCA アプリケーション: UDP、TCP、ICMP トラフィックを検出、管理、フィルタリング、分析できる GPU パケット処理アプリケーション。このアプリケーションは、HTTP over TCP サーバーも実装しています。単純な HTTP クライアント (curl や wget など) を使って、TCP の 3 ウェイ ハンドシェイク接続を確立し、GPU への HTTP GET リクエストを通じて単純な HTML ページを要求することができます。
- NVIDIA DOCA サンプル: Accurate Send Scheduling 機能の使用方法 (システム構成、使用する関数) を示す GPU 送信のみの例です。
DOCA GPUNetIO の実例
DOCA GPUNetIO は、NVIDIA Aerial SDK が GPU を使用して送受信し、CPU を排除するために使用されています。詳細については、NVIDIA DOCA GPUNetIO によるインライン GPU パケット処理をご覧ください。以下のセクションでは、DOCA GPUNetIO をうまく使用して、GDAKIN 技術による GPU パケット取得を活用する新しい例を示します。
NVIDIA Morpheus AI
NVIDIA Morpheus は、サイバーセキュリティ開発者が大量のリアルタイム データをフィルタリング、処理、分類するための完全に最適化された AI パイプラインを作成できるようにする、パフォーマンス指向のアプリケーション フレームワークです。このフレームワークは、Python と C++ の API で構成されるアクセス可能なプログラミング モデルを通じて、GPU と CPU の並列性と並行性を抽象化します。
このフレームワークを活用することで、開発者は、下流のコンシューマー向けにデータを取得、変異、または公開するステージで構成される任意のデータ パイプラインを迅速に構築することができます。Morpheus は、マルウェア検出、フィッシング/スピアフィッシング検出、ランサムウェア検出など、さまざまなコンテキストに適用できます。その柔軟性と高い性能は、リアルタイムのネットワーク トラフィック分析に最適です。
ネットワーク モニタリングのユース ケースにおいて、NVIDIA Morpheus チームは最近、DOCA フレームワークを統合し、パケットの内容を分析する AI パイプラインにリアルタイム パケットを供給するために高速で低遅延の GPU パケット取得ソース ステージを実装しました。詳細については、GitHub の Morpheus をご覧ください。

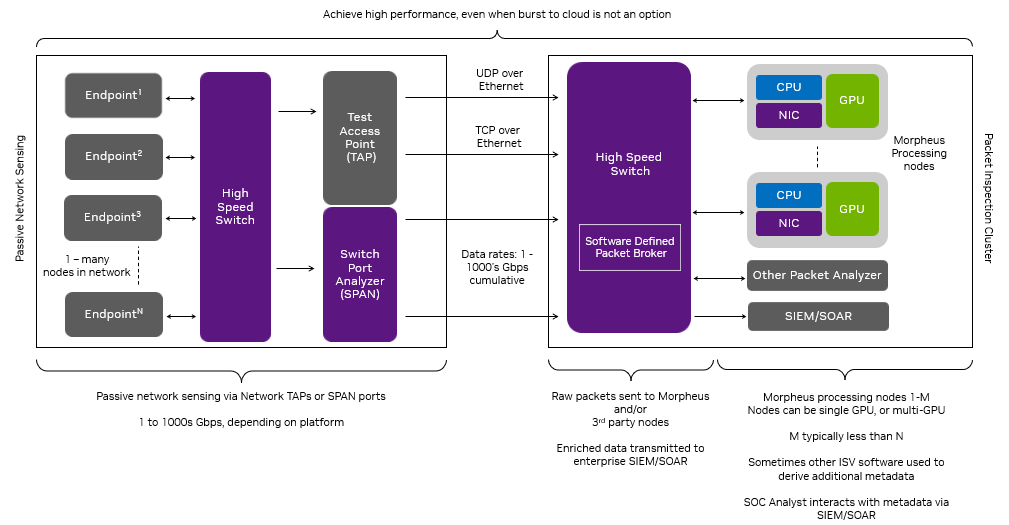
図 2 に示すように、GPU のパケット取得はリアルタイムで行われます。DOCA Flow を通じて、Flow Steering ルールがイーサネットの受信キューに適用され、キューは特定の種類のパケット (例えば TCP) のみを受信できます。Morpheus は CUDA カーネルを起動し、ループ内で以下のステップを実行します:
- DOCA GPUNetIO 受信機能を使ってパケットを受信
- GPU メモリ内のパケットをフィルタリングして並列で分析
- GPU メモリ バッファのリストに関連パケット情報をコピー
- 関連する DOCA GPUNetIO のセマフォ項目を、バッファに十分なパケット情報が蓄積された際に READY に設定
- AI パイプラインの前にある CUDA カーネルがセマフォ項目をポーリング
- アイテムが READY になると、パケット情報がバッファに準備され、AI はブロックを解除
GTC のセッション「Defensive Cyber Operations (DCO) on Edge Networks」では、このアーキテクチャを活用して高性能な AI 対応 SPAN/Network TAP ソリューションを展開した具体例を紹介しました。このソリューションは、情報技術 (IT) および運用技術 (OT) ネットワークにおける困難なデータ レート、レイヤ 7 のアプリケーション データの不均一性、エッジ コンピューティングのサイズ、重量、消費電力 (SWaP: Size, Weight and Power) の制約が動機となっています。
エッジ コンピューティングの場合、多くの組織は、特に切断されたエッジ ネットワーク上で、コンピューティング需要が増加したときに「クラウドにバースト」することができません。このシナリオでは、SWaP スペクトル全体にわたってパフォーマンスを提供する I/O とコンピューティングの課題に対するアーキテクチャを設計する必要があります。
この DCO の例は、暗号化されていない TCP トラフィックから流出したデータ (流出したパスワード、秘密鍵、個人情報など) を特定するという、サイバーセキュリティの一般的な問題のレンズを通して、これらの制約に対処するもので、Morpheus SID デモの拡張を表しています。このような脆弱性を特定して修正することで、攻撃対象が減り、組織のセキュリティ態勢が強化されます。
この例では、DCO ソリューションがパケットをヘテロジニアスな Morpheus パイプライン (Python と C++ の混合で書かれた GPU とコンカレント CPU ステージ) に受信し、レイヤー 7 のアプリケーション データから漏えいした機密データを検出するために Transformer モデルを適用します。このパイプラインは ELK スタックと出力を統合し、セキュリティ オペレーション センター (SOC) のアナリストが利用できる直感的な可視化機能を備えています (図3、4)。


実験でのセットアップでは、100Gbps の NVIDIA BlueField-2 DPU を搭載した VM 上で動作するクラウドネイティブの UDP マルチキャストおよび REST アプリケーションが含まれていました。これらのアプリケーションは、SWaP 効率の高い NVIDIA Spectrum SN2100 イーサネット スイッチを介して通信しました。パケット ジェネレーターは、これらのアプリケーションが送信するパケットに機密データを注入しました。ネットワーク パケットは、NVIDIA Spectrum SN2100 の SPAN ポートに集約されミラーリングされ、Morpheus パケット インスペクション パイプラインを駆動する NVIDIA A30X コンバージド アクセラレータに送られ、驚異的なスループットを達成しました。
- このパイプラインには、サードパーティの SIEM プラットフォーム (Elasticsearch) における、I/O、パケット フィルタリング、パケット処理、インデックス作成など、複数のコンポーネントが含まれています。DOCA GPUNetIO は、I/O の側面だけに着目し、Morpheus が単一の受信キューで最大 100Gbps のパケットを GPU メモリに受信することを可能にし、サイバー パケット処理アプリケーションにおける重要なボトルネックを取り除きます。
- このパイプラインは、ステージ レベルの並行性を活用し、Elasticsearch のインデックス作成のスループットを 60% 向上しました。
- NVIDIA A30X コンバージド アクセラレータ上でエンドツーエンドのデータ パイプラインを実行すると、Elasticsearch インデックスの ~50% の容量でエンリッチされたパケットが生成されました。2 倍の A30X を使用すると、インデックスが完全に飽和し、便利なスケーリング ヒューリスティックを提供します。
このユース ケースは、Morpheus の具体的なアプリケーションを示していますが、サイバー パケット処理アプリケーションの基礎となるコンポーネントを示しています。Morpheus と DOCA GPUNetIO を組み合わせることで、遅延に敏感で演算負荷の高い膨大な数のパケット処理アプリケーションに対応するパフォーマンスと拡張性を提供します。
ラインレート レーダー信号処理
このセクションでは、レーダー探知アプリケーションが、100Gbps のライン レートでシミュレーションされたレンジのみのレーダー システムからダウンコンバートされた I/Q サンプルを取り込み、受信した I/Q RF サンプルをリアルタイムでオブジェクト探知に変換するために必要なすべての信号処理を実行する例について説明します。
レーダー、ライダー、光学プラット フォームなどのリモート センシング アプリケーションは、測定対象環境から収集した生データを実用的な情報に変換する信号処理アルゴリズムに依存しています。これらのアルゴリズムは、多くの場合、高度に並列化可能で、高い演算負荷を必要とするため、GPU ベースの処理に最適です。
さらに、入力センサーは膨大な量の生データを生成するため、処理ソリューションにおける入力/出力の能力は、低遅延で非常に高い帯域幅を処理できるものでなければなりません。
さらに問題を複雑にしているのは、多くのエッジベースのセンサー システムには厳しい SWaP 制約があり、DPDK ベースの GPUDirect RDMA のような他の高スループット ネットワーキング アプローチで使用されるような CPU コアの数や電力が制限されていることです。
DOCA GPUNetIO は、リアルタイム センサー ストリーミング アプリケーションを成功させるために必要な信号処理だけでなく、ネットワーク負荷を GPU が直接処理できるようにします。
レーダー探知アプリケーションでは、一般的に使用されている信号処理アルゴリズムが使用されました。図 6 のフローチャートは、I/Q サンプルを検出に変換するために使用される信号処理パイプラインを示しています。

MTI フィルタリングは、レーダー システムの反射 RF 波形から、地面や建物などの静止した背景クラッタを除去するために使用される一般的な手法です。ここで使用されるアプローチは 3 パルス キャンセラーとして知られており、これは単にパルス次元の I/Q データをフィルター係数「[+1, -2, +1]」で畳み込んだものです。
パルス圧縮は、ターゲットの存在に対して受信波形の信号対雑音比 (SNR) を最大化します。これは、受信 RF データと送信波形の相互相関を計算することによって実行されます。
CFAR (Constant False Alarm Rate) 検出器は、フィルタリングされたデータの各レンジ ビンにローカライズされたノイズの経験的推定値を計算します。その後、各ビンのパワーがノイズと比較され、ノイズの推定値と分布から統計的に可能性が高ければ検出となります。
受信される整理された RF データを保持するために、サイズ (# 波形 )× (# チャンネル) × (# サンプル) の 3D バッファが使用されます (パケット受信時に MTI フィルタを適用すると、パルス次元のサイズが 1 に減少することに注意)。UDP データは、パケットの波形 ID の昇順でストリーミングされる以外は、順序は想定されていません。パケットあたり約 500 の複雑なサンプルが送信され、3D バッファ内のサンプルの位置は波形 ID、チャンネル ID、サンプル インデックスに依存します。
このアプリケーションは、2 つの CUDA カーネルと 1 つの CPU コアを持続的に実行します。最初の CUDA カーネルは、DOCA GPUNetIO API を使用して NIC から GPU にパケットを読み込む役割を果たします。2 番目の CUDA カーネルは、パケット ヘッダー内のメタデータに基づいてパケット データを正しいメモリ位置に配置し、MTI フィルタを適用し、CPU コアはパルス圧縮と CFAR を処理する CUDA カーネルの起動を担当します。FFT は cuFFT ライブラリを使用して実行されました。
図 7 は、アプリケーションの図解です。

レーダー探知パイプラインのスループットは 100Gbps を超えました。100 万個の 16 チャンネル波形に対して 100Gbps のライン レートで動作させましたが、パケットがドロップすることはなく、信号処理がデータ ストリームのスループットに遅れることはありませんでした。独立した波形 ID の最後のデータ パケットを受信した時点から測定した遅延は、3 ミリ秒のオーダーでした。NVIDIA ConnectX-6 Dx SmartNIC と NVIDIA A100 80GB GPU を使用し、データはイーサネット上の UDP パケットで送信されました。
将来的には、このアーキテクチャを GPU 内蔵の BlueField DPU のみで実行した場合の性能を評価する予定です。
GPU を介したリアルタイム DSP サービス
アナログ信号は、人工的なもの (例えば Wi-Fi 無線) や自然なもの (例えば太陽放射や地震) の両方が至る所に存在します。アナログ データをデジタルで取り込むには、D-A コンバーターを使って音波を変換する必要があり、サンプル レートやサンプル ビット深度などのパラメーターで制御されます。デジタル音声や映像は FFT で処理できるため、サウンド デザイナーはイコライザー (EQ) などのツールを使って信号の一般的な特性を変えることができます。
こちらの例では、NVIDIA 製品と SDK を使用して、ネットワーク経由で GPU によるリアルタイムの音声 DSP を実行した方法を説明します。この実現のために、チームは WAV ファイルを解析し、データを複数のイーサネット パケットにフレーム化し、ネットワーク経由でサーバー アプリケーションに送信するクライアントを構築しました。このアプリケーションは、パケットを受信し、FFT を適用し、音声信号を操作し、最後に変更されたデータを送り返す役割を担います。
クライアントは、信号処理チェーンのためにどの部分を「サーバー」に送るべきかを認識することと、サーバーから戻ってきた時に処理されたサンプルをどのように扱うかを認識することを担います。このアプローチは、OverLap-Add などの複数の DSP アルゴリズムや、様々なサンプル ウィンドウの選択をサポートします。
サーバー アプリケーションは DOCA GPUNetIO を使用して、CUDA カーネルから GPU メモリ内のパケットを受信します。パケットのサブセットが受信されると、CUDA カーネルは各パケットのペイロードに cuFFTDx ライブラリを通して FFT を並列に適用します。並行して、各パケットに対して、異なる CUDA スレッドが、低周波または高周波の振幅を低減する周波数フィルタを適用します。基本的には、ローパスまたはハイパス フィルターを適用します。

逆 FFT が各パケットに適用されます。DOCA GPUNetIO を通じて、CUDA カーネルは修正されたパケットをクライアントに送り返します。クライアントはパケットを並べ替え、再構築することで、サウンド効果が適用された可聴や再現可能な WAV 音声ファイルを再作成します。
クライアントを使って、チームはパラメーターを微調整し、パフォーマンスと音声出力の品質を最適化することができました。フローを分離し、ストリームを処理チェーンに多重化することで、多くの複雑な計算を GPU にオフロードすることも可能です。これは、クラウド DSP サービス プロバイダーにとって新たな市場機会を開く可能性があり、このソリューションの可能性をかすめたに過ぎません。
まとめ
DOCA GPUNetIO ライブラリは、リアルタイムのトラフィック解析を行うネットワーク アプリケーションにおいて、パケットの取得と送信の両方に対して GPU 中心の汎用的なアプローチを促進します。この記事では、このライブラリがさまざまなコンテキストの幅広いアプリケーションで採用され、遅延、スループット、システム リソースの利用率に大きな改善をもたらすことを紹介しました。
GPU パケット処理と GPUNetIO の詳細については、以下の関連情報を参照してください。
- Inline GPU Packet Processing with NVIDIA DOCA GPUNetIO
- DOCA GPUNetIO Programming Guide
- DOCA GPUNetIO Application Guide
- Defensive Cyber Security Operations on Edge Networks
関連情報
- GTC session: Connect with the Experts: Inter-GPU Communication Techniques and Libraries (Spring 2023)
- SDK: Magnum IO
- SDK: Nsight Systems
- SDK: GPUDirect Storage
- Webinar: Accelerating Low-Latency Market Data With NVIDIA A100X
- Webinar: Democratizing Low-Latency Network Adapters
翻訳に関する免責事項
この記事は、「Realizing the Power of Real-Time Network Processing with NVIDIA DOCA GPUNetIO」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。