
自動運転システムが高速道路を安全に走行するためには、100 m 以上離れた車両などの遠方の物体を検出することが基本となります。
このような高い速度域では、1 秒 1 秒が大切です。そのため、時速 70 マイル (約時速 110 km) で走行中の自律走行車 (AV) の認識範囲を 100 m から 200 mに広げることができれば、車両が反応するための時間が大幅に増えることになります。
しかし、この範囲を拡大することは、量産される乗用車に一般的に搭載されるカメラベースの認識システムにとっては特に困難です。遠距離物体検出のためのカメラ認識システムの学習には、大量のカメラ データの収集と、3D バウンディング ボックスや距離などの GT (Ground Truth) ラベルが必要となります。
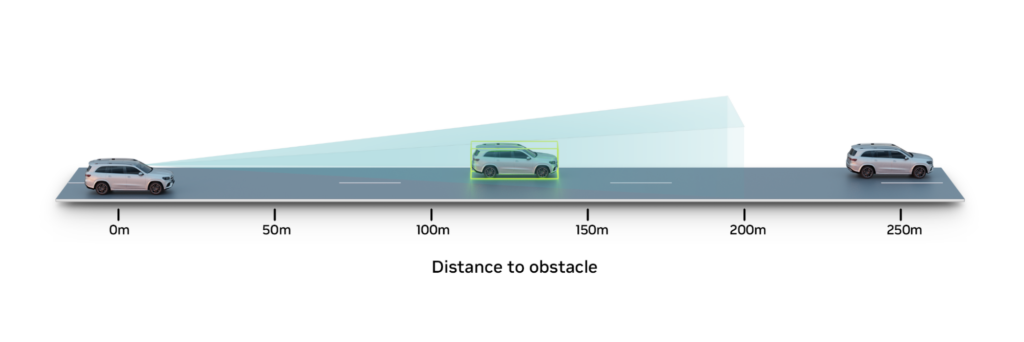
この GT データの抽出は、200 m を超えるような対象物では特に難しくなります。対象物が遠ければ遠いほど、画像中の対象物は小さくなり、最終的には数ピクセル幅にしかなりません。通常、3D や距離情報を抽出するために、ライダーなどのセンサーを用いたアグリゲーションやオートラベリング技術を使用しますが、ライダーの動作範囲を超えると、このデータはまばらになり、ノイズが多く発生します。

NVIDIA DRIVE AV チームは、開発の過程でこの課題を確実に解決する必要がありました。そのために、NVIDIA DRIVE Sim で、NVIDIA Omniverse Replicator の機能を活用し、遠方のオブジェクトの合成 GT データを生成しました。
NVIDIA DRIVE Sim は Omniverse をベースに構築された AV シミュレーターで、高い忠実度のセンサー シミュレーションのために徹底的に検証された物理ベースのセンサー モデルを含んでいます。詳しくは、「Validating NVIDIA DRIVE Sim Camera Models (NVIDIA DRIVE Sim カメラ モデルの検証)」をご覧ください。
NVIDIA DRIVE Sim では、あらゆるカメラの解像度で、自車両から 400 m から 500 m 離れた場所にある物体にいたるまで、シミュレーション シーン内のあらゆる物体の位置を、ピクセルレベルの精度で照会することができます。
車両の位置情報と物理法則に基づいた合成カメラ データを組み合わせると、認識に必要な 3D 情報や距離の GT ラベルを生成することが可能です。
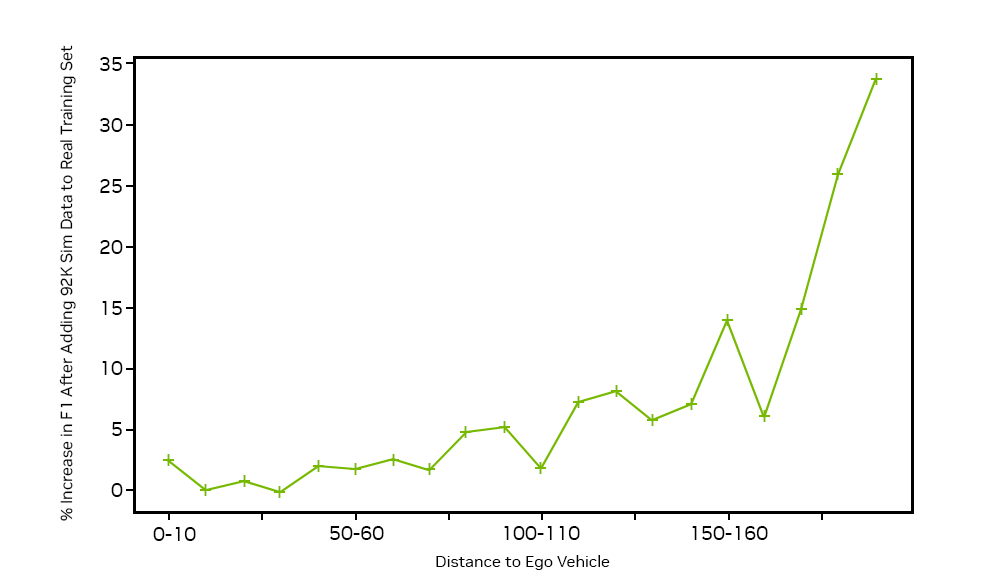
この合成 GT データを既存の実データセットに加えて遠距離の車を検出するネットワークを学習させ、190 m から 200 m の距離にある車に対する F1 スコアを 33% 向上することができました。
遠方にある物体の GT 合成データ作成
正確にラベル付けされた遠距離データの不足に対処するため、約 100,000 枚の画像からなる遠距離にある物体の合成データセットを生成し、既存の実データセットを補強することを目指しました。図 3 は、Omniverse Replicator を用いた NVIDIA DRIVE Sim で、これらのデータセットを生成し、3D 環境の選択からディープ ニューラル ネットワーク (DNN) の性能評価を行うまでの過程を示しています。
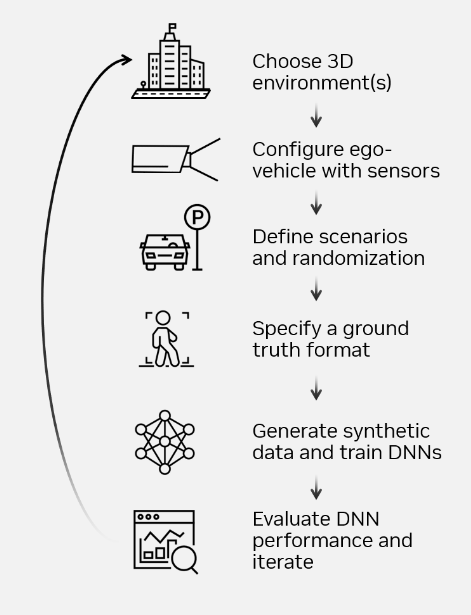
高速道路のユース ケースに対応した 3D 環境を選択した後、必要なカメラ センサーを搭載した自車両を構成しました。
NVIDIA DRIVE Sim は、Omniverse Replicator フレームワークで構築されたドメイン ランダム化 API を活用し、プログラムによって 3D アセットの外観、配置、動きを変更することができます。ASAM OpenDRIVE マップ API を使用して、100 m から 350 m の遠距離にある車両や障害物を、状況に応じた方法で配置しました。
NVIDIA DRIVE Sim アクション システムは、車線変更や急な割り込みなど、視界を遮る様々な困難なケースのシミュレーションを可能にします。これにより、現実世界では遭遇しにくいシナリオに重要なデータを提供します。
データ生成前の最終段階では、Omniverse Replicator から GT ライターを活用して、3D バウンディング ボックス、速度、セマンティックなラベル、オブジェクト ID など、必要なラベルを生成します。
合成カメラ データによるカメラ認識性能の向上
このユース ケースでは、実際の学習データセットは、高速道路シナリオの 200 m までの車両の GT ラベルを含む 100 万枚以上の画像で構成されています。これらの実際の画像における車両の分布は、図 4 の左側に示すように、データ収集車両から 100 m 未満でピークに達しています。それ以上の距離の物体に対しては、GT ラベルはまばらであり、認識を高めるには不十分です。
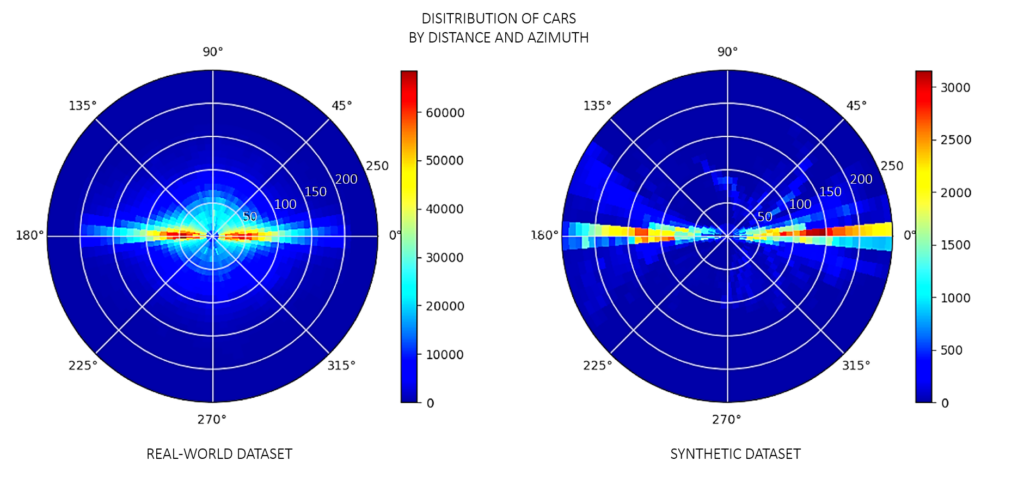
今回は、350 m までの遠距離の車両の分布に着目し、車と GT ラベルのインスタンス 371,000 個を含む、約 92,000 枚の合成画像を作成しました。合成データセットの車の分布は、150 m 以上のより遠距離に偏っています。実データセットに、この約 92,000 枚の合成画像を追加することで、学習に適切なラベル付き遠距離オブジェクトの分布を実現できました。
結合されたデータセットで認識アルゴリズムを学習した後、200 m までの分布がある実データセットを用いて、そのネットワークをテストしました。距離による認識性能向上の KPI では、190 m から 200 m の車について、データセットに対するモデルの精度を示す F1 スコアが最大で 33% 向上しています。
まとめ
合成データは、自動運転開発の大きなパラダイムシフトを推進し、これまで不可能だった新しいユース ケースの可能性を解き放ちます。NVIDIA DRIVE Sim と NVIDIA Omniverse Replicator を使えば、新しいセンサーのプロトタイプ作成、新たなグランド トゥルース タイプや 自動運転用認識アルゴリズムの評価、稀で対応が難しい出来事のシミュレーションなどを、仮想実験場で、現実世界でかかる時間とコストのほんの一部だけで行うことができます。
合成データセットが可能にする 自動運転用認識の豊富な可能性は、進化し続けています。NVIDIA GTC DRIVE Developer Day のセッション「How to Generate Synthetic Data with NVIDIA DRIVE Replicator (NVIDIA DRIVE Replicator で合成データを生成する方法)」では、私たちのワークフローと詳細をご紹介しています。
翻訳に関する免責事項
この記事は、「Bringing Far-Field Objects into Focus with Synthetic Data for Camera-Based AV Perception」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。