
In the last few years, the roles of AI and machine learning (ML) in mainstream enterprises have changed. Once research or advanced-development activities, they now provide an important foundation for production systems.
As more enterprises seek to transform their businesses with AI and ML, more and more people are talking about MLOps. If you have been listening to these conversations, you may have found that nearly everyone involved agrees that you need an MLOps strategy to get ML into production.
This post provides a brief overview of enterprise MLOps. To learn more, join me at NVIDIA GTC 2023 for Enterprise MLOps 101, an introduction to the MLOps landscape for enterprises. I will be presenting the session with my colleague, Michael Balint.
Why MLOps is confusing
The MLOps conversation is confusing for several key reasons, which are detailed below.
MLOps is broad
MLOps is a broad term describing the technologies, processes, and culture that enable organizations to design, develop, and sustain production ML systems. Nearly any tool or system that is relevant to conventional software development, data management, or business intelligence could be relevant to a production ML system.
Because MLOps is a popular topic, many such tools and systems that could be relevant to production ML systems have rebranded to emphasize their connection to MLOps.
MLOps is diverse
Machine learning systems are complex software systems. Different organizations and practitioners will take diverse approaches to managing this complexity, just as they do with managing the complexity of building and maintaining conventional software systems.
However, because organizations have not been building production ML systems for as long as organizations have been building conventional software, standardized approaches have not been established. Standardization is also missing for the language used to describe these systems and the criteria with which to evaluate them.
It can be confusing when different people talk about MLOps because they may be describing different parts of the problem space. For example, the parts that are most important to their use case, their industry, or their organization’s processes and tools.
MLOps is complex
MLOps is legitimately complex. However, because experienced MLOps practitioners and organizations are focused on the details of their particular approach and tools, they have a tendency to emphasize its complexity. Part of the problem is that in an evolving domain like production machine learning, it can be difficult to figure out how to tease apart accidental complexity and essential complexity in order to present a simple view of a complex problem.
Getting past the confusion
A better way to start approaching MLOps is to think about what your organization is doing today with machine learning, what you would like to do in the future, and what challenges you will face with machine learning systems as a result.
What problems need to be solved?
Different ML problems impose different sorts of requirements on ML systems. Problems involving unstructured data, like understanding video, audio, or natural language, involve far more effort, including manual human effort, to label training examples than problems involving tabular business data, in which the labeling effort can often be trivial or automated.
Some problems benefit from a model that only needs data that is immediately available from a single source, while other approaches and problems depend on federating historical and aggregated data from multiple sources with a new observation to make a prediction. Novel applications of ML may benefit from better support for experimental and exploratory development, while mature systems may benefit more from development process automation.
Finally, systems that automate critical decisions that can affect human lives, control dangerous machinery, or manage financial portfolios need to be simulated in a range of conditions, including unlikely or adversarial scenarios, in order to validate their suitability and safety. If you are working with problems that imply special requirements, make sure you land on a MLOps solution that can help you meet those requirements.
What factors need to be considered?
Similarly, some application areas and business requirements impose technical requirements on machine learning systems. Applications in regulated industries often benefit from being able to reproduce and explain historical results, such as explaining a financial underwriting discussion or showing that a user’s personal data was not used in training a model.
Latency-sensitive applications, like search, media recommendations, and ad targeting, can benefit from serving infrastructure that supports low latency prediction and serving a result from an ensemble of more and less complex models together to improve worst-case response time. Many perceptual problems will benefit from infrastructure for transfer learning and serving frameworks that can handle and optimize large and complex models.
What do the ML and data teams look like today?
Just as the overall ML landscape continues to evolve, the roles and personas of data teams continue to evolve. In the early 2010s, a “data scientist” was a full-stack role that had substantial data engineering and software development responsibilities, as well as some statistical sophistication. Today, data scientists are far more specialized. Teams now commonly include the following roles:
Data scientists focus on designing and executing experiments to identify and exploit patterns in data, using tools like basic summaries and aggregation, applied statistics, and machine learning.
Data engineers make data—whether structured or unstructured, at rest or in motion—available at scale and also address concerns of cataloging, governance, and access control.
Business analysts use query processing on structured, federated datasets to understand characteristics of a business problem.
Application developers build up production systems by developing mature and robust services based on data scientists’ experiments, integrating with data services maintained by data engineers, and developing conventional application components and integrations with enterprise middleware.
Machine learning engineers have responsibilities that span multiple roles, but with a particular focus on developing, maintaining, and optimizing production infrastructure.
Thinking about who is currently involved in your data teams—and who you would like to have involved in the future—is an important aspect of evaluating MLOps tools, systems, and solutions. This evaluation tells you what is important to your team and who the audience is for a given solution.
Evaluate the landscape and design a solution for your team
After considering the problems you are trying to solve and the makeup of your data team, you are prepared to evaluate and understand the MLOps landscape in terms of the solution that you and your organization need. Your goal is to support your own machine learning initiatives, rather than trying to make sense of the MLOps landscape based on what vendors and influencers are saying about MLOps.
A workflow-centric approach
Because the MLOps ecosystem is rapidly evolving, many product categories are not mutually exclusive and have fuzzy boundaries. This means that you do not necessarily want to think of an MLOps solution as a checklist of features or a combination of complementary products that fit together like building blocks. That approach will commit you to a particular viewpoint of a changing landscape.
Instead, think about how people work together to build machine learning systems and how different kinds of tools and systems can support them.
Figure 1 shows a characteristic machine learning discovery workflow. This workflow features seven human processes, each of which informs the next. The personas involved in each stage are noted: data scientist and business analyst personas are typically not concerned with the details of compute infrastructure, while engineers and app developers interact with infrastructure directly as part of their job.
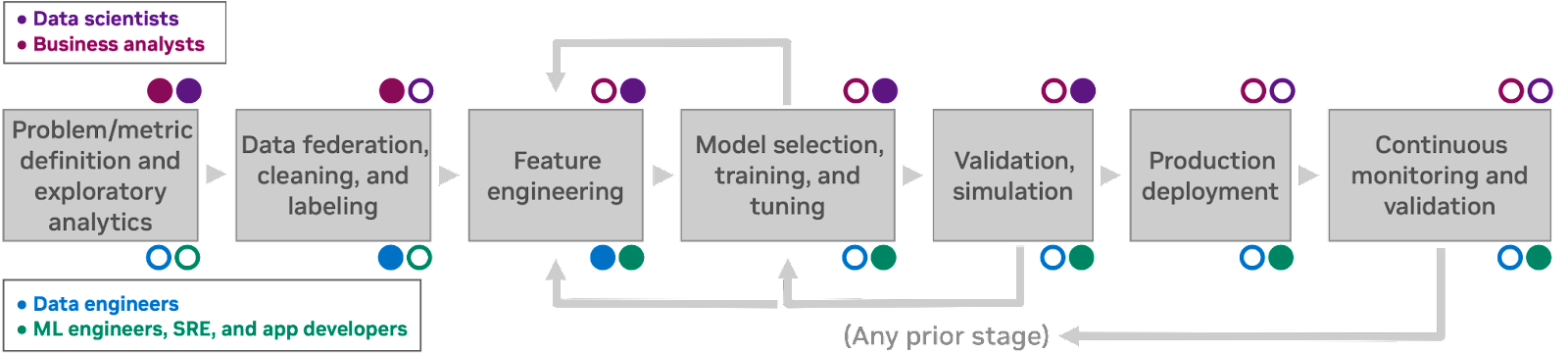
Because humans always have incomplete information (and often make mistakes), it is possible to return to an earlier workflow phase at any point and revisit earlier decisions in light of new insights. How your organization talks about ML workflows may involve slightly different terms or a different number of stages, but it should be possible to follow along in any case.
Supporting your team across the ML workflow
How can MLOps tools support the ML workflow? Figure 2 depicts various overlapping product categories and how they support aspects of the ML workflow. Personas and offering categories that are indifferent to or isolated from the underlying compute infrastructure are depicted above the workflow, while personas and products that depend on interacting directly with the underlying compute infrastructure are depicted below the workflow.
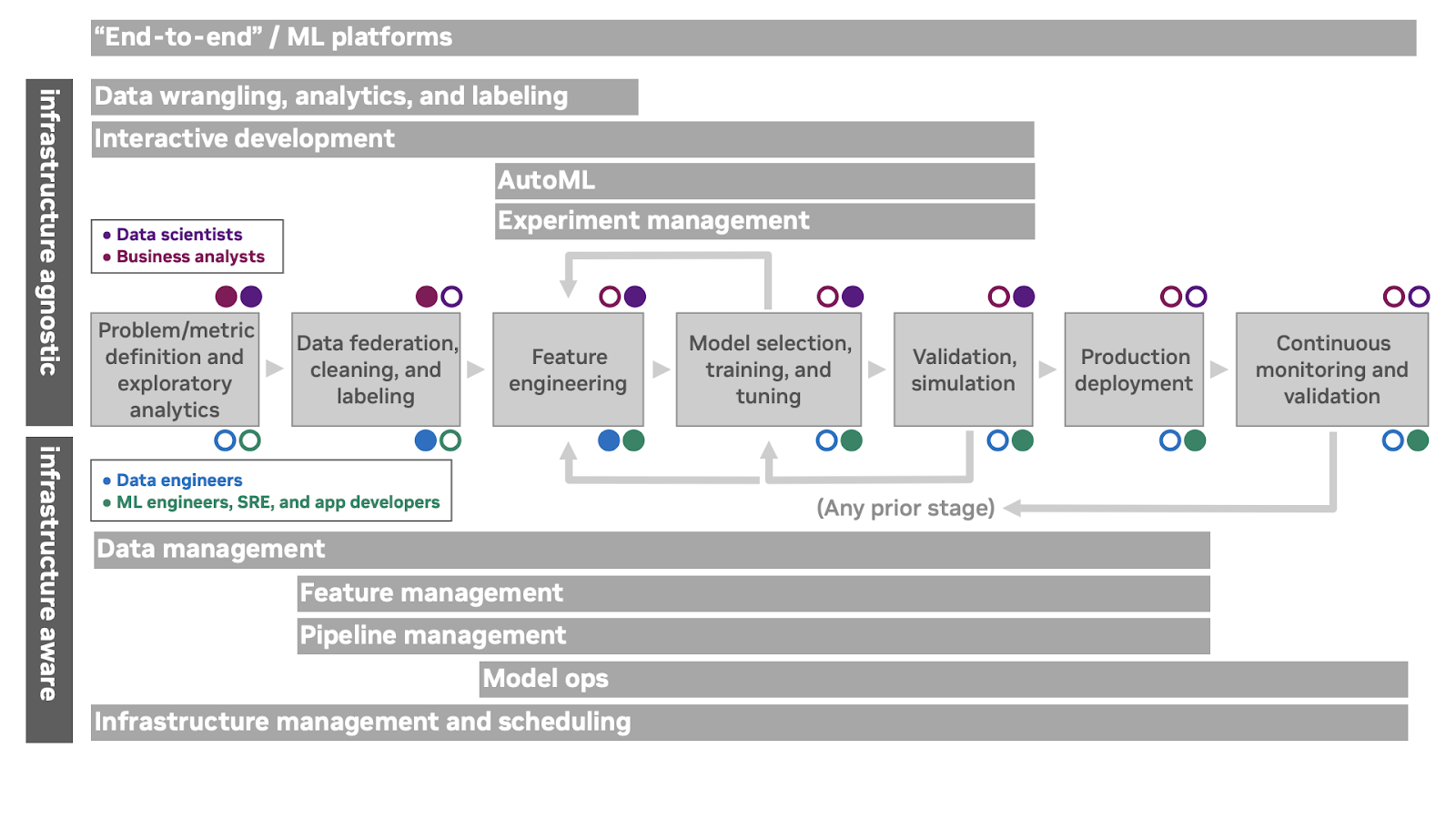
The topmost category in Figure 2, end-to-end, includes ML platform offerings that incorporate a control plane and support for several lifecycle phases. It is important to note that the term ‘end-to-end’ is not a value judgment or statement of completeness. Membership in this category merely indicates that a particular offering covers a broad slice of the lifecycle and is designed to be operated by itself.
The second category in Figure 2 combines data wrangling offerings, which include data exploration, visualization, and high-level federation capabilities, conventional business intelligence and analytics offerings, and labeling offerings for unstructured data. The sorts of problems you are solving will indicate which of these kinds of offerings are most relevant to your workflows.
Interactive development offerings provide a control plane to give data science and ML practitioners access to on-demand compute resources. These often provide a facility for managing development environments and integrate with external version control systems, desktop IDEs, and other standalone developer tools. They provide a unified view of on-premises and public cloud infrastructure, and make it easier for teams to collaborate on projects.
Experiment management offerings provide a way to track results from various model configurations (along with versioned code and data) in order to understand modeling performance over time. AutoML systems build on experiment management to automatically search the space of possible techniques and hyperparameters for a given technique to produce a trained model with minimal practitioner input.
Data management offerings support data warehousing, data versioning, ingest, and access control. From the perspective of ML systems, data versioning is often the critical piece—reproducible work depends on being able to identify the data on which a model was trained.
Feature management offerings incorporate feature stores to track derived, aggregated, or expensive-to-compute features for development and production. These can also support collaboration around feature engineering approaches in some organizations.
Pipeline management offerings provide a way to orchestrate and monitor the multiple software components involved in exploratory and production workflows, for example, preprocessing, training, and inference.
ModelOps offerings address the concerns of publishing models as deployable services, deploying these prediction services, managing and routing to ensembles of prediction services, explaining predictions after the fact, tracking feedback from predictions, and monitoring model inputs and outputs for concept drift.
Infrastructure management provides an interface to schedule compute jobs and services on underlying hardware or cloud resources. Offerings in this space are typically interesting from the perspective of machine learning systems if they provide special support for accelerated hardware, gang scheduling, and other ML-specific concerns.
Learn more
This is an exciting time to be thinking about and building ML systems. Register for NVIDIA GTC 2023 for free and join us March 20–23 for Enterprise MLOps 101, an introduction to the MLOps landscape for enterprises, and many other related sessions.
