この投稿は、NVIDIA TensorRT 8.0 のアップデートを反映するために 2021 年 7 月 20 日に更新されました。
ニューラル ネットワークをデプロイするときは、ネットワークの実行速度の高速化や空間の低減方法を考えると良いです。より効率的なネットワークは、限られた時間の中でより良い予測を行い、予想外の入力に対してより迅速に反応し、制約のあるデプロイメント環境に適合できます。
スパース性はこれらの目的を達成することを約束する最適化手法の 1 つです。ネットワークにゼロがある場合は、それに対して保存や操作をする必要はありません。スパース性のメリットは簡単なことのように思われます。スパース性の効果を実現するには以前から 3 つの課題がありました。
- 高速化 — 細粒度の構造化されていない重みのスパース性は構造に欠け、効率的なハードウェアで利用できるベクトル命令と行列命令を使用して一般的なネットワーク運用を高速化することはできません。標準のスパース形式はスパース性が高い以外はすべて非効率的です。
- 精度 — 細粒度の構造化されていないスパース性で有用なスピードアップを図るには、ネットワークをスパースにする必要があり、多くの場合、精度の低下を引き起こします。重み、チャネル、または層全体のブロックを取り除く粗粒度のプルーニングなど、高速化を容易にしようとする代替のプルーニング方法では、精度の問題がさらに早く発生する可能性があります。これにより、潜在的なパフォーマンス上のメリットが制限されます。
- ワークフロー — ネットワーク プルーニングにおける現在の研究の多くは有用な存在証明として機能します。ネットワーク A がスパース性 X を達成できることが示されています。ネットワーク B に 同様のスパース性 X を適用しようとすると問題が発生します。ネットワーク、タスク、オプティマイザー、ハイパーパラメーターの違いにより機能しない場合があります。
この投稿では、NVIDIA Ampere アーキテクチャがこのような課題にどのように対処しているかについて説明します。現在、NVIDIA は TensorRT バージョン 8.0 をリリースしています。このバージョンでは、NVIDIA Ampere アーキテクチャ GPU で利用できる Sparse Tensor コアがサポートされています。
TensorRT は高性能ディープラーニング推論用の SDK です。オプティマイザーとランタイムが含まれており、レイテンシを最小限に抑え、本番環境のスループットを最大化します。簡単なトレーニング ワークフローを使用して TensorRT 8.0 でデプロイすると、Sparse Tensor コアはニューラル ネットワークで不要な計算をなくし、デンス ネットワークと比較して 30% 以上のパフォーマンス当たりの電力消費量 (パフォーマンス/ワット) の効率化を実現します。
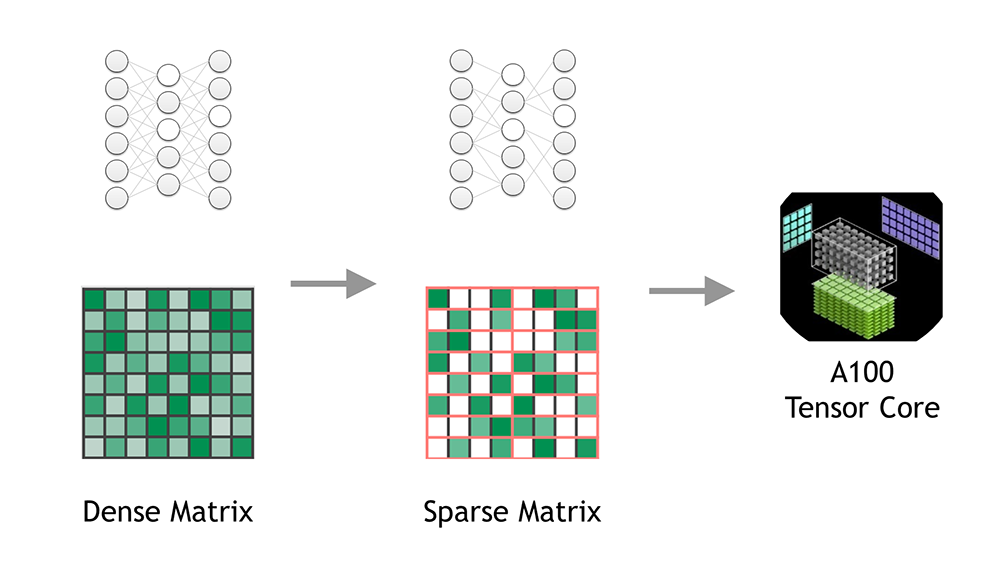
Sparse Tensor コアは 2:4 の細粒度の構造化されたスパース性を高速化
NVIDIA A100 GPU は Tensor コアで細粒度の構造化されたスパース性をサポートします。 Sparse Tensor コアは 2:4 スパース性パターンを高速化します。連続する 4 つの値からなるブロックのそれぞれにおいて、2 つの値はゼロでなければなりません。これは必然的に 50% のスパース性になり、粒度が高くなります。一緒にプルーニングするベクトル構造やブロック構造はありません。このような通常のパターンは簡単に圧縮でき、メタデータ オーバーヘッドは少なくなります (図 1)。
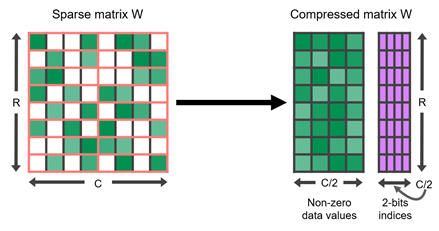
Sparse Tensor コアは、圧縮行列内のゼロ以外の値のみを操作することで、このフォーマットを高速化します。これらは、他の非圧縮オペランドから必要な値のみを引き出すために、ゼロ以外の値で保管されたメタデータを使用します。したがって、スパース性が 2 倍の場合、同じ有効な計算を半分の時間で完了できます。表 1 に、Sparse Tensor コアでサポートされているさまざまなデータ型の詳細を示します。
| 入力オペランド | アキュムレータ | Dense TOPS | 対 FFMA | Sparse TOPS | 対 FFMA |
| FP32 | FP32 | 19.5 | – | – | – |
| TF32 | FP32 | 156 | 8 倍 | 312 | 16 倍 |
| FP16 | FP32 | 312 | 16 倍 | 624 | 32 倍 |
| BF16 | FP32 | 312 | 16 倍 | 624 | 32 倍 |
| FP16 | FP16 | 312 | 16 倍 | 624 | 32 倍 |
| INT8 | INT32 | 624 | 32 倍 | 1248 | 64 倍 |
2:4 構造化されたスパース ネットワークで精度を維持
もちろん、パフォーマンスは正確さなしでは意味がありません。デンス ネットワークの精度に一致する 2:4 構造化されたスパース ネットワークを簡単に生成できるシンプルなトレーニング ワークフローを開発しました。
- デンス ネットワークから始めます。目的は重みが収束し、有用な結果が得られる既知の優れたモデルから始めることです。
- デンス ネットワークでは、重みをプルーニングし、2:4 構造化されたスパース性の基準を満たすようにします。4 つの要素から 2 つの要素のみを削除します。
- 元のトレーニング手順を繰り返します。
このワークフローでは、手順 2 でワンショット プルーニングを使用します。プルーニング段階の後、スパース性パターンが固定されます。プルーニングの決定にはさまざまな方法があります。どの重みを維持し、どれをゼロにすべきですか? その答えは単純です: それは重みの大きさです。既に 0 に近い値をプルーニングすることをお勧めします。
予測したとおり、ネットワーク内の重みの半分を突然ゼロにした場合、ネットワークの精度に影響が出る可能性があります。手順 3 では、重みの更新手順で精度が回復し、重みが収束し、十分に学習レートが高くなり、重みが効率的に動き回ります。 この方法は信じられないほどうまくいきます。広範囲のネットワークで、手順 1 からデンス ネットワークの精度を維持するスパース性モデルを生成します。
表 2 に、PyTorch ライブラリの Automatic SParsity (ASP) に実装されたこのワークフローを使用して取得した FP16 精度結果のサンプルを示します。FP16 と INT8 の両方の結果の詳細については、Accelerating Sparse Deep Neural Networks ホワイトペーパーを参照してください。
| ネットワーク | データ セット | メトリック | Dense FP16 | Sparse FP16 |
| ResNet-50 | ImageNet | Top-1 | 76.1 | 76.2 |
| ResNeXt-101_32x8d | ImageNet | Top-1 | 76.3 | 79.3 |
| Xception | ImageNet | Top-1 | 79.2 | 79.2 |
| SSD-RN50 | COCO2017 | bbAP | 24.8 | 24.8 |
| MaskRCNN-RN50 | COCO2017 | bbAP | 37.9 | 37.9 |
| FairSeq Transformer | EN-DE WMT’14 | BLEU | 28.2 | 28.5 |
| BERT-Large | SQuAD v1.1 | F1 | 91.9 | 91.9 |
導入事例: ResNeXt-101_32x8d
ResNeXt-101_32x8d をターゲットとして使用するワークフローは次のように簡単です。
スパース性モデルの生成
torchvision のトレーニング済みモデルを使用しているため、手順 1 は既に完了しています。ASP を使用しているため、最初のコードの変更はライブラリをインポートすることです。
try:
from apex.contrib.sparsity import ASP
except ImportError:
raise RuntimeError("Failed to import ASP. Please install Apex from https:// github.com/nvidia/apex .")このトレーニング実行用のトレーニング済みモデルを読み込みます。ただし、デンスの重みをトレーニングする代わりに、モデルをプルーニングし、トレーニング ループの前にオプティマイザーを準備します (ワークフローの手順 2)。
ASP.prune_trained_model(model, optimizer)
print("Start training")
start_time = time.time()
for epoch in range(args.start_epoch, args.epochs):
...それだけです。トレーニング ループは、デフォルトのコマンド拡張で通常どおりに進行し、トレーニング済みモデルから始まります。これは、元のハイパーパラメーターとオプティマイザーの設定を再利用して再トレーニングします。
python -m torch.distributed.launch --nproc_per_node=8 --use_env train.py\
--model resnext101_32x8d --epochs 100 --pretrained Trueトレーニングが完了すると (手順 3)、表 2 に示すように、トレーニング済みモデルと一致するようにネットワークの精度が回復しているはずです。通常、最高のパフォーマンスを発揮するチェックポイントは、最終的なエポックからではない可能性があります。
推論の準備
推論のために、TensorRT 8.0 を使用してトレーニング済みモデルのスパース チェックポイントをインポートします。TensorRT にインポートする前に、モデルをネイティブ フレームワーク形式から ONNX 形式に変換する必要があります。変換は、quickstart/IntroNotebooks の GitHub リポジトリにあるノートブックに従うことで行うことができます。
スパースの ResNeXt-101_32x8d を ONNX 形式に変換済みです。このモデルは NGC からダウンロードできます。NGC をインストールしていない場合は、次のコマンドを使用して NGC をインストールします。
cd /usr/local/bin && wget https://ngc.nvidia.com/downloads/ngccli_cat_linux.zip && unzip ngccli_cat_linux.zip && chmod u+x ngc-cli/ngc && rm ngccli_cat_linux.zip && echo "no-apikey\nascii\n" | /usr/local/bin/ngc-cli/ngc config setNGC のインストール後、次のコマンドを実行して、スパースの ResNeXt-101_32x8d を ONNX 形式でダウンロードします。
ngc-cli/ngc registry model download-version nvidia/resnext101_32x8d_sparse_onnx:1ONNX モデルを TensorRT にインポートするには、NVIDIA/TensorRT readme に記載されているように、TensorRT リポジトリのクローンを作成し、Docker 環境を設定します。
TensorRT のルート ディレクトリに移動後、trtexec を使用して、スパース化された ONNX モデルを TensorRT エンジンに変換します。モデルとエンジンを格納するディレクトリを作成します。
cd /workspace/TensorRT/
mkdir modelダウンロードした ResNext ONNX モデルを /workspace/TensorRT/model ディレクトリにコピーし、次のように trtexec コマンドを実行します。
./workspace/TensorRT/build/out/trtexec \
--onnx=/workspace/TensorRT/model/resnext101_32x8d_pyt_torchvision_sparse.onnx \ --saveEngine=/workspace/TensorRT/model/resnext101_engine.trt \
--explicitBatch \
--sparsity=enable \
--fp16resnext101_engine.trt という名前の新しいファイルが /workspace/TensorRT/model/ に作成されます。これで resnext101_engine.trt ファイルをシリアル化し、次のいずれかの方法で推論を実行できるようになりました。
- このノートブックの例にある C++ または Python の TensorRT ランタイム
- NVIDIA Triton 推論サーバー
TensorRT 8.0 のパフォーマンス
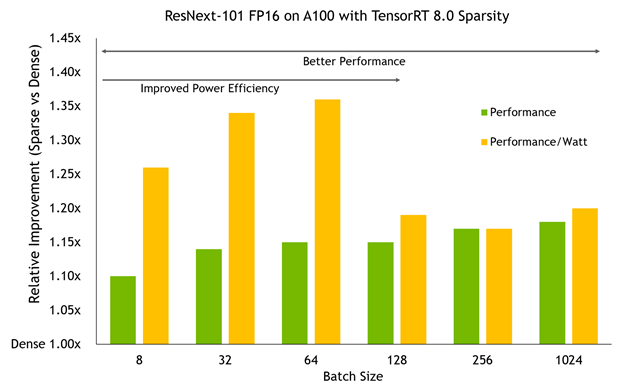
さまざまなバッチ サイズで A100 GPU で TensorRT 8.0 のこのスパース性モデルをベンチマークすると、2 つの重要な傾向が示されます。
- A100 が行っている作業量に応じて、パフォーマンス上の利点が増します。バッチ サイズが大きいほど、一般的に改善が大きくなり、ハイエンドでは 20% に近くなります。
- より小さなバッチ サイズでは、A100 クロック速度が低く抑えられ、スパース性を使用することで、同じパフォーマンスでさらに低く押し下げることができます。その結果、電力効率がパフォーマンス自体よりも大きく改善され、パフォーマンス/ワットが最大 36% 向上します。
このネットワークはデンス ベースラインとまったく同じ精度を持っていることを忘れないでください。この十分な効率性とパフォーマンスは精度を低下させるものではありません。
まとめ
スパース性はニューラル ネットワークの圧縮と単純化の研究で一般的です。しかしながら、今までは細粒度のスパース性はパフォーマンスと精度を約束するものではありませんでした。NVIDIA は 2:4 の細粒度の構造化されたスパース性を開発し、NVIDIA Ampere アーキテクチャの Sparse Tensor コアにサポートを直接組み込みました。このシンプルな 3 段階のスパース再トレーニング ワークフローにより、ベースラインの精度に一致するスパース ニューラル ネットワークを生成でき、TensorRT 8.0 はデフォルトで高速化します。
詳細については、Making the Most of Structured Sparsity in the NVIDIA Ampere Architecture の GTC2021 セッション、NVIDIA Ampere アーキテクチャのスパース性の高速化について、または Accelerating Sparse Deep Neural Networks ホワイトペーパーをご覧ください。
自分のネットワークで 2:4 スパース性を試す準備はできていますか? Automatic SParsity (ASP) PyTorch ライブラリを使用すると、スパース ネットワークを簡単に生成でき、TensorRT 8.0 で効率的にデプロイできます。
TensorRT 8.0 とその新機能の詳細については、Accelerate Deep Learning Inference with TensorRT 8.0 の GTC’21 セッションまたは TensorRT ページをご覧ください。