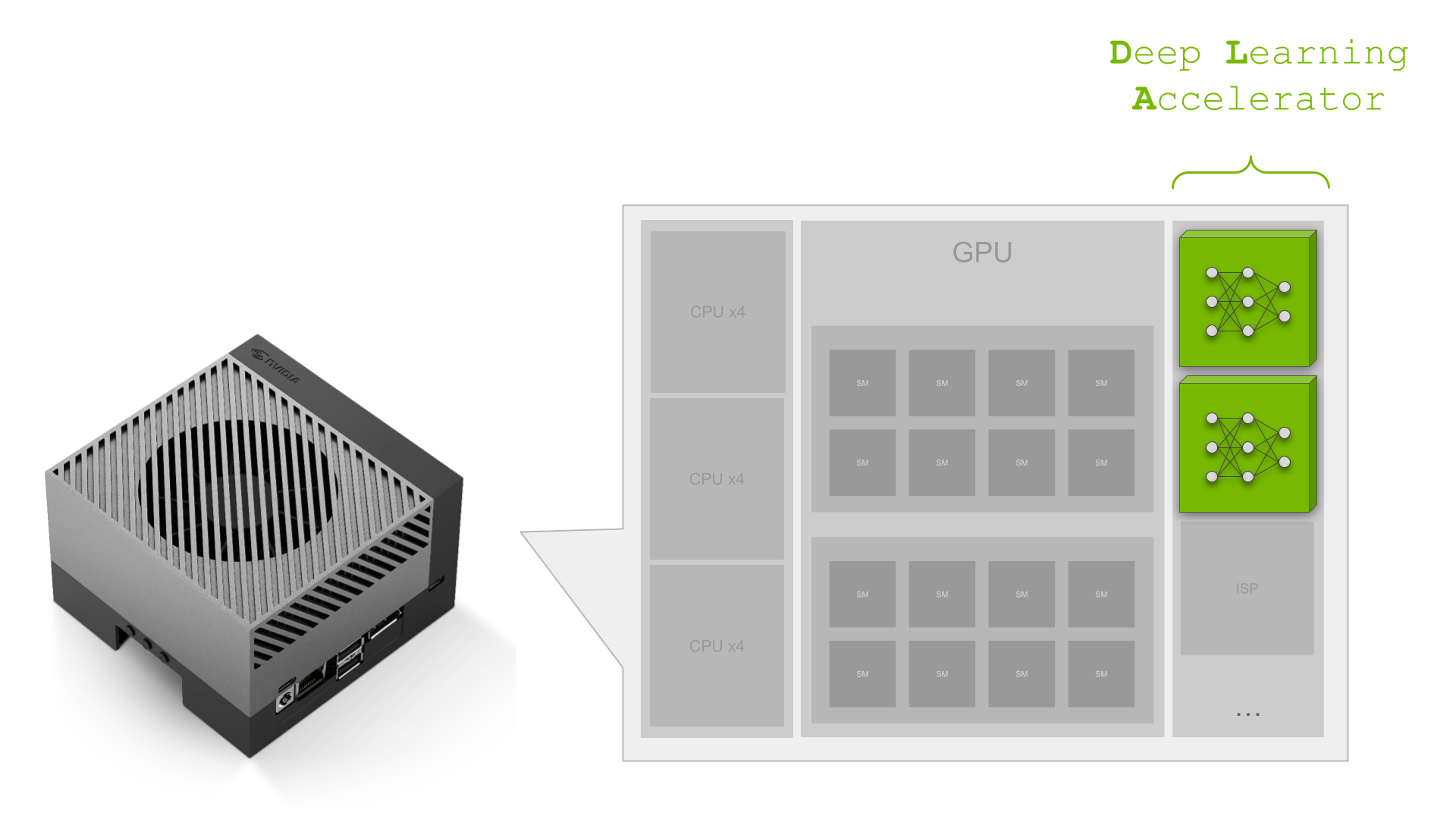
NVIDIA Jetson Orin は、最高クラスの組込み AI プラットフォームです。Jetson Orin SoC モジュールの NVIDIA Ampere アーキテクチャ GPU コアには、SoC にさらに多くの計算機能が組み込まれています:
- ディープラーニング アクセラレータ (DLA) に搭載された、ディープラーニング ワークロード専用の推論エンジン
- 画像処理とコンピューター ビジョン アルゴリズム用のプログラマブル ビジョン アクセラレータ (PVA) エンジン
- マルチ スタンダード ビデオ エンコーダ (NVENC) と、マルチスタンダード ビデオ デコーダー (NVDEC)
NVIDIA Orin SoC は 最大 275 TOPS の AI パフォーマンスを持つ強力な性能を持ち、最高の組込みと自動車向け AI プラットフォームとなっています。これら AI TOPS のほぼ 40% が、NVIDIA Orin の 2 つの DLA によるものであることをご存知でしょうか? NVIDIA Ampere GPU はクラス最高のスループットを持つ一方で、第 2 世代の DLA は最高の電力効率を持っています。 AI の応用が近年急速に成長しているだけでなく、効率的なコンピューティングへの需要も増加しています。特に組込み側では、電力効率が常に重要な KPI となっています。
ここで DLA が登場します。DLA はディープラーニングの推論専用に設計されており、コンボリューションのような計算負荷の高いディープラーニング操作を、CPU よりもはるかに効率的に実行できます。
Jetson AGX Orin や NVIDIA DRIVE Orin などの SoC に統合されると、GPU と DLA の組み合わせは、組込み AI アプリケーションに完全なソリューションを提供します。この記事では、Deep Learning Accelerator について詳しく説明し、DLA を活用するための情報を提供します。自動車およびロボティクスのいくつかのケース スタディを取り上げ、DLA が AI 開発者がアプリケーションに機能と性能を追加できるようにする方法を示します。最後に、ビジョン AI 開発者が DeepStream SDK を使用して、最適なパフォーマンスを提供するために DLA と Jetson SoC 全体を活用したアプリケーション パイプラインを構築する方法についても説明します。
まず、以下は DLA が大きな影響を与える主要なパフォーマンス指標です。
主要なパフォーマンス指標 (KPI)
アプリケーションを設計する際には、満たすべき主要パフォーマンス指標 (KPI) がいくつかあります。多くの場合、設計上のトレードオフ、例えば最大性能と電力効率の間で、開発チームは SoC 上の異なる IP を使用するアプリケーションを注意深く分析し、設計する必要があります。
アプリケーションの主要な KPI がレイテンシである場合、一定のレイテンシ バジェット内でアプリケーション内のタスクをパイプライン化する必要があります。DLA は、 GPU 上で実行されるより計算集約的なタスクと並列するタスクのための追加アクセラレータとして使用できます。DLA のピーク性能は、パワー モードにもよりますが、NVIDIA Orin のディープラーニング (DL) 総合性能に 38% から 74% 貢献します。
| Power mode: MAXN | Power mode: 50W | Power mode: 30W | Power mode: 15W | |
| GPU sparse INT8 peak DL performance | 171 TOPS | 109 TOPS | 41 TOPS | 14 TOPS |
| 2x DLA sparse INT8 peak performance | 105 TOPS | 92 TOPS | 90 TOPS | 40 TOPS |
| Total NVIDIA Orin peak INT8 DL performance | 275 TOPS | 200 TOPS | 131 TOPS | 54 TOPS |
| Percentage: DLA peak INT8 performance of total NVIDIA Orin peak DL INT8 performance | 38% | 46% | 69% | 74% |
Jetson AGX Orin 64GB の 30 W および 50 W の電力モードの DLA TOP は、自動車向けの NVIDIA DRIVE Orin プラットフォームの最大周波数と比較可能です。
電力が重要な KPI の 1 つであるならば、DLA の電力効率を活用することを検討すべきです。ワットあたりの DLA 性能は、電力モードと作業負荷にもよりますが、GPU に比べて平均 3-5 倍です。以下のチャートは、一般的な使用ケースを代表する 3 つのモデルのワットあたりの性能を示しています。
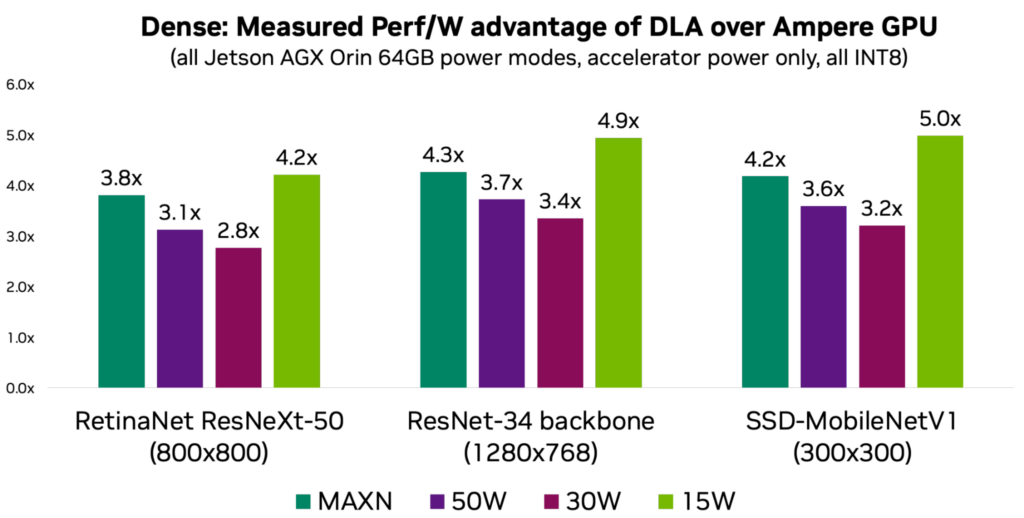
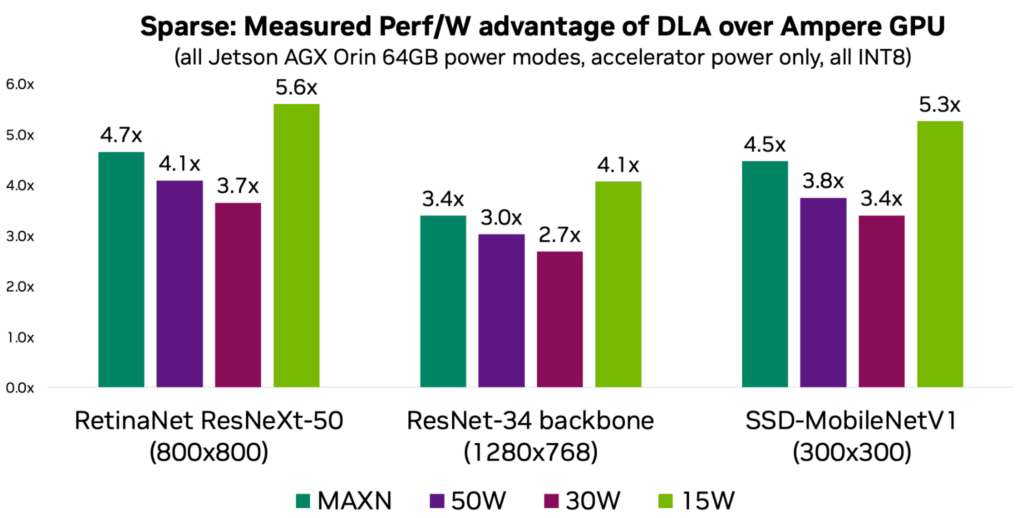
異なる言い回しで説明すると、DLA (Deep Learning Accelerator) の電力効率がなければ、NVIDIA の Orin プロセッサで最大 275 DL TOPS の処理性能を特定のプラットフォームの電力予算内で達成することは不可能でした。さらなるモデルの情報と測定結果については、DLA-SW GitHub リポジトリをご覧ください。
以下は、NVIDIA 内での DLA による AI 計算をどのように活用したかについての、自動車およびロボティクスのケース スタディです:
ケース スタディ: 自動車
NVIDIA DRIVE AV チームのエンジニアは、NVIDIA Orin SoC プラットフォーム全体を活用することで、知覚、マッピング、プランニング パイプラインの設計と最適化に取り組んでいます。自動運転スタックで処理すべきニューラル ネットワークやその他の非 DNN タスクの数が多いため、彼らは DNN タスクを実行するために、NVIDIA Orin SoC 上の専用推論エンジンとして DLA に依存しています。GPU コンピュートは非 DNN タスクの処理に予約されているため、これは非常に重要である。DLA のコンピュートなしでは、チームは KPI を達成できないでしょう。
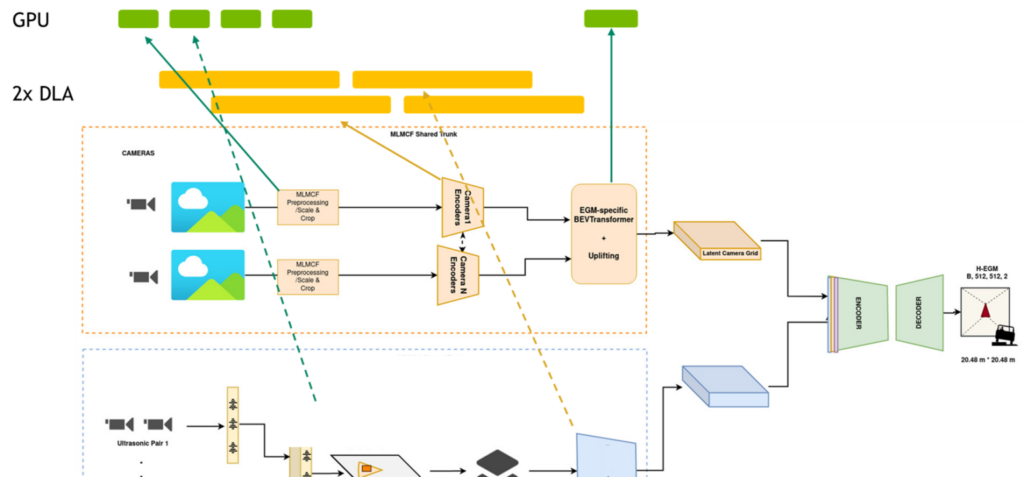
より詳細については、Near-Range Obstacle Perception with Early Grid Fusion をご覧ください。
例えば知覚パイプラインでは、8 つの異なるカメラ センサーからの入力があり、パイプライン全体のレイテンシはある閾値より低くなければなりません。知覚スタックは DNN を多用し、全計算量の 60% 以上を占めています。
これらの KPI を満たすため、並列パイプライン タスクは GPU と DLA にマッピングされ、パイプライン全体のレイテンシ目標を達成するために、ほぼすべての DNN が DLA で実行され、非 DNN タスクが GPU で実行されます。出力は、マッピングやプランニングのような他のパイプラインで、他の DNN によって順次または並列に消費されます。パイプラインは、GPU と DLA 上で並列に実行されるタスクによる巨大なグラフと見なすことができる。DLA を使用することで、チームはレイテンシを 2.5 倍に削減しました。

「SoC 全体、特に DLA の専用のディープラーニング 推論エンジンを活用することで、レイテンシ要件と KPI 目標を満たしつつ、ソフトウェア スタックに重要な機能を追加することができます。これは DLA だからこそ可能なことです。」と、NVIDIA の自律走行チームのエンジニアリング マネージャーである Abhishek Bajpayee は述べています。
ケース スタディ: ロボティクス
NVIDIA Isaac は、ロボット開発者が使用する AI 対応ロボットの開発、シミュレーション、および配備のための強力なエンドツーエンドのプラットフォームです。特にモバイル ロボットでは、利用可能な DL コンピュート、決定論的レイテンシ、バッテリー耐久性が重要な要素となります。これが、DL 推論を DLA にマッピングすることが重要な理由です。
NVIDIA Isaac チームのエンジニアチームは、DNN を用いた近接セグメンテーションのためのライブラリを開発しました。近接セグメンテーションは、障害物が近接フィールド内にあるかどうかを判断し、ナビゲーション中の障害物との衝突を回避するために使用できる。彼らは、ステレオ カメラからの二値深度分類を実行する BI3D ネットワークを DLA に実装します。
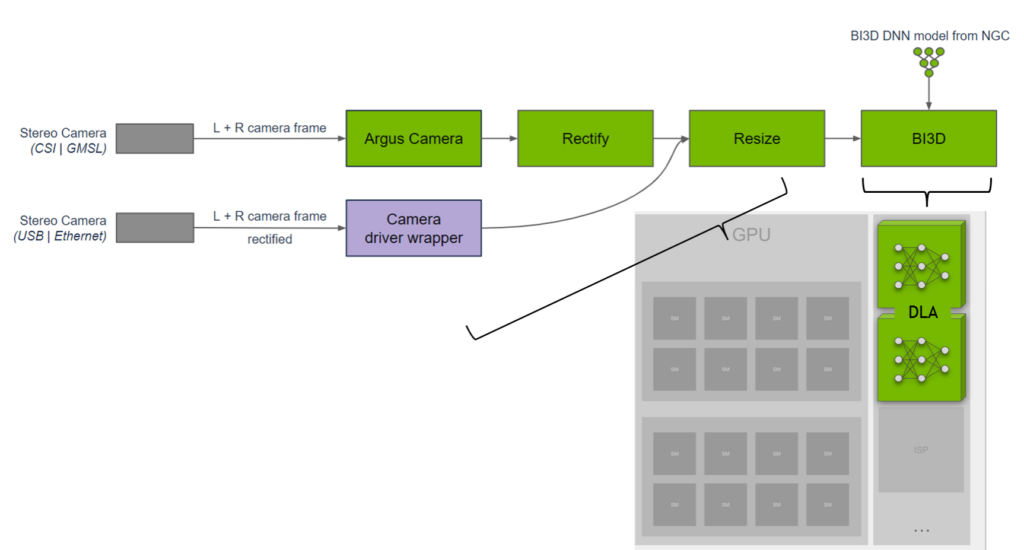
重要な KPI は、ステレオ カメラの入力からリアルタイムで 30fps の検出を確保することです。NVIDIA Isaac チームは、タスクを SoC に分散させ、DNN に DLA を使用する一方で、GPU 上で実行されるものからハードウェアとソフトウェアにおける機能安全の多様性を提供しています。詳細については、NVIDIA Isaac ROS Proximity Segmentation をご覧ください。

「私たちは、DNN の推論に TensorRT を DLA で使用しており、GPU とは異なるハードウェアの多様性を提供し、フォールト トレランスを向上させつつ、他のタスクを GPU からオフロードしています。DLA は Jetson AGX Orin で BI3D に対して約 46fps を提供し、3 つの DNN で構成され、ロボティクス アプリケーションにおいて 30ms 未満の低レイテンシを提供しています。」 と NVIDIA のロボティクス プラットフォーム ソフトウェアの副社長である Gordon Grigor は述べています。
NVIDIA DLA 用の DeepStream
DLA を探索する最も迅速な方法は、完全なストリーミング分析ツールキットである NVIDIA DeepStream SDK を使用することです。
ビジョン AI の開発者がビデオやセンサー データを分析する AI 搭載アプリケーションを構築する場合、DeepStream SDK を使用することで、最適なエンドツーエンドのパイプラインを構築することができます。小売分析、駐車場管理、物流管理、光学検査、ロボティクス、スポーツ分析などのクラウドまたはエッジのユース ケースに対して、DeepStream は SoC 全体、特に DLA をわずかな労力で使用できるようにします。
例えば、以下の表で強調されている Model Zoo から事前学習されたモデルを使用して、DLA 上で実行することができます。DLA 上でこれらのネットワークを実行するのは、フラグを設定するのと同じくらい簡単です。詳細については、Using DLA for inference を参照してください。
| Model arch | Inference resolution | GPU FPS | DLA1 + DLA2 FPS | GPU + DLA1 + DLA2 FPS |
| PeopleNet-ResNet18 | 960x544x3 | 218 | 128 | 346 |
| PeopleNet-ResNet34 (v2.3) | 960x544x3 | 169 | 94 | 263 |
| PeopleNet-ResNet34 (v2.5 unpruned) | 960x544x3 | 79 | 46 | 125 |
| TrafficCamNet | 960x544x3 | 251 | 174 | 425 |
| DashCamNet | 960x544x3 | 251 | 172 | 423 |
| FaceDetect-IR | 384x240x3 | 1407 | 974 | 2381 |
| VehicleMakeNet | 224x224x3 | 2434 | 1166 | 3600 |
| VehicleTypeNet | 224x224x3 | 1781 | 1064 | 2845 |
| FaceDetect (pruned) | 736x416x3 | 395 | 268 | 663 |
| License Plate Detection | 640x480x3 | 784 | 388 | 1172 |
Deep Learning Accelerator を始めましょう
準備はできましたか? 詳細な情報については、以下のリソースをご覧ください。
- Jetson DLA tutorial は 初めて DNN を DLA に展開する際の手助けとなる基本的な DLA ワークフローを示しています。
- DLA-SW GitHub リポジトリには、Jetson Orin の DLA 上で DNN を実行することを探求するために使用できるリファレンス ネットワーク コレクションがあります。
- samples page ページには、Jetson SoC を最大限に活用するための DLA の使用方法に関する他の例やリソースがあります。
- DLA forum には、他のユーザーからのアイデアやフィードバックがあります。
翻訳に関する免責事項
この記事は、「Maximizing Deep Learning Performance on NVIDIA Jetson Orin with DLA」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。