
Deep neural network (DNN) development for self-driving cars is a demanding workload. In this post, we validate DGX multi-node, multi-GPU, distributed training running on RedHat OpenShift in the DXC Robotic Drive environment.
We used OpenShift 3.11, also a part of the Robotic Drive containerized compute platform, to orchestrate and execute the deep learning (DL) workloads. At the present time, OpenShift 3.11 is deployed in many large, GPU-accelerated, autonomous driving (AD) development and test environments. The recipes shown here apply to new OpenShift versions as well and are transferable to other OpenShift based clusters.
DXC Robotic Drive is an autonomous driving data-driven development platform that drastically de-risks and accelerates the development, testing, and validation of ADAS/AD capabilities to support Level 2 plus – Level 5 autonomous functions. It’s the largest known exabyte-scale development solution, leveraging industry-proven, on-premises and cloud infrastructure, methodologies, tools, and accelerators for a highly automated AD development process.
The interoperability test environment was the Robotic Drive Innovation Labs, which runs OpenShift 3.11 and 4.3.
DL workloads at scale
Data parallelism, which scales training horizontally, is the most used design pattern to scale DL workloads. There are multiple references and practices on how to accelerate vision and recursive neural networks.
The DL model is instantiated multiple times and data is streamed in parallel through those instances. The instances exchange their gradients with each other to work together instead of independently.
This is a classic computation pattern for the Message Passing Interface (MPI) framework from the high performance computing (HPC) domain. Thus, orchestration of such workloads with the help of the well-known MPI is straightforward. MPI also makes it easy to scale even beyond multiple nodes.
Multi-GPU–enabled DL frameworks such as PyTorch and TensorFlow are excellent to use from the start of any project, to ensure that the workload can use a single GPU workstation up to a large-scale GPU cluster.
Such frameworks also support data parallel training using MPI natively and can trigger the workload using MPI tools, such as mpirun or mpiexec. Multiple implementations of the data parallelism pattern exist and follow this paradigm, such as Horovod.
RedHat OpenShift Container Platform (OCP) is a platform as a service built around either Docker or CRI-O runtime containers based on Kubernetes. OpenShift is focused on security and does include fixes for defects, security, and performance issues for upstream Kubernetes. As Kubernetes, OpenShift allows deploying and managing clusters at scale with support from RedHat.
Kubernetes and OpenShift can deal with the MPI workload easily. An integration exists in the form of the Kubeflow MPI Operator, which orchestrates the resources in the background and spins up the workload.
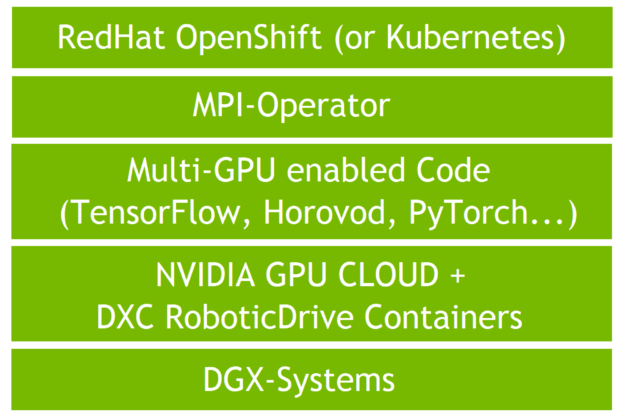
Figure 1 shows a DL workload using two DGX-1 systems. In this case, there are 16 individual processes. In Horovod, those are given a unique ID called rank to distinguish them from each other: rank 0 to rank 15. All individual processes are working in parallel on a different portion of the input data and exchange their gradients to work together.
For effective communication between the individual towers NVIDIA Collective Communications Library (NCCL) is used. NCCL implements multi-GPU and multi-node collective communication primitives that are performance optimized for NVIDIA GPUs.
The low latency-based POSIX storage for training data is realized by Robotic Drive persistent volumes. Handling storage at scale is crucial, but not the focus here.
Installation steps
Here’s how to install DGX systems in the DXC Robotic Drive environment running on OpenShift v3.11.
Test system overview
OpenShift v3.11 requires a minimum of one temporary bootstrap machine, three master nodes, and at least two compute nodes.
Because DL can be a data-intensive workload, the cluster requires an appropriate networking solution. The Robotic Drive Innovation Lab provided HPE FlexFabric 5945 32QSFP28 switches, which were used in combination with the Mellanox adapters of the DGX systems.
All cluster interconnect adapters of the DGX-1 are used in ethernet mode and are bundled together by using LACP teaming mode.
The following table summarizes the hardware and software configuration of the cluster.
| OpenShift and supporting infrastructure services | Three OpenShift master nodes + three infrastructure nodes |
| Networking and Connectivity up | One bastion / Two load balancers HAproxy and Keepalived |
| Software / versions | OpenShift v3.11 OS on DGX nodes: RHEL 7.6 |
Preparing the DGX-1 systems
To install RHEL 7.7 on DGX systems, use the installation instructions provided by NVIDIA. These steps also include the installation of DGX-specific software.
Joining the DGX system to the OpenShift cluster
Install the cluster as described in the RedHat documentation for OpenShift 3.11.
After the cluster is up and running, use the official playbooks provided by RedHat to scale up the cluster and include both DGX systems. Those playbooks add necessary packages and configure nodes, as well as adding them to the cluster itself.
Figure 2 shows the start screen of the OCP dashboard, which allows you to interact with an OpenShift cluster. Those interactions include monitoring resources, creating pods, and retrieving logs.
Enabling GPUs in the cluster
OpenShift (and Kubernetes) both support standard resources like CPU, memory, and monitoring available disk space. Additional resources are handled using device plugins or operators. In this setup, you use the NVIDIA GPU device plugin for OpenShift 3.11.
In newer versions of Kubernetes and OpenShift (v1.13+ , v4.1+), they introduced the operator framework. Using this operator framework, the NVIDIA GPU Operator allows you to automate the deployment of components that previously had to be deployed manually. These components include the NVIDIA driver, a Kubernetes device plugin for GPUs, the NVIDIA Container Runtime, automatic node labeling, and DCGM-based monitoring.
For more information, see device plugins and the NVIDIA GPU Operator.
Multi-GPU, single-node workload
Start with running a multi-GPU workload that scales up to the number of GPUs are available in a single DGX system. Both Kubernetes and OpenShift allow you to allocate a container on the DGX cluster with the specified number of GPUs. Within that container, you start the workload using the MPI paradigm.
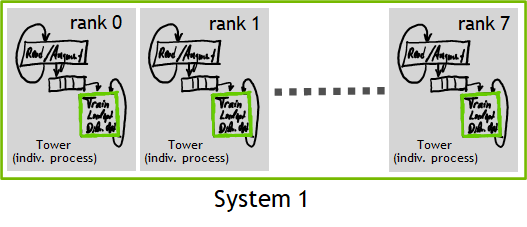
Figure 3 shows a parallel workload within just a single system. The rank enumeration is illustrated within this single system. We used the Horovod framework to parallelize the training.
In the following examples, we show you how to trigger an MPI-based, DL workload using the Horovod framework. For this test, we used an MPI-enabled Docker container with the required frameworks, such as NGC containers. NGC is a GPU-optimized software hub, simplifying AI and HPC workflows.
Start the workload, then wrap the command in an OpenShift YAML for orchestration.
To run a scalable ResNet-50 training with randomly generated data natively, run the following command:
docker run --gpus all -it horovod/horovod:0.18.1-tf1.14.0-torch1.2.0-mxnet1.5.0-py3.6
The previous example makes use of all GPUs available on the system with the --gpus all flag. To allocate only a smaller number of GPUs, change that to --gpus 1. You can also specify individual GPUs by using their device IDs.
To start the workload in a container in interactive mode, a typical command looks like the following code example. In this example, eight GPUs are used:
horovodrun -np 8 -H localhost:8 python pytorch_synthetic_benchmark.py
A corresponding YAML file is used to start this workload through OpenShift, which can be deployed straight from OpenShift login node, OpenShift master node, or the GUI.
oc create -f horovod_example_8gpus.yaml kubectl create -f horovod_example_8gpus.yaml
This is the content of the YAML file used:
apiVersion: v1 kind: Pod metadata: name: horovod-new_test namespace: managed-machine-learning spec: serviceAccount: tensorflow-sa restartPolicy: OnFailure containers: - name: horovod-test image: horovod/horovod:0.18.1-tf1.14.0-torch1.2.0-mxnet1.5.0-py3.6 command: [ "horovodrun", "-np", "8", "python" , "pytorch_synthetic_benchmark.py" ] env: - name: NVIDIA_VISIBLE_DEVICES value: all - name: NVIDIA_DRIVER_CAPABILITIES value: "compute,utility" - name: NVIDIA_REQUIRE_CUDA value: "cuda>=9.0" resources: limits: nvidia.com/gpu: "8" requests: nvidia.com/gpu: "8" securityContext: privileged: true
To influence the scalability of the workload set the following parameters accordingly.
The command section specifies the command to be run, which is the same as used in the Docker example. The number of processes spawned can be controlled via the -np 8 flag.
command: [ "horovodrun", "-np", "8", "python" , "pytorch_synthetic_benchmark.py" ]
Allocate the proper number of GPUs in the resources section. The number should correspond to the number of processes set in the horovodrun command.
resources: limits: nvidia.com/gpu:"8" requests: nvidia.com/gpu:"8"
A pod is a group of one or more containers. Figure 4 shows the creation of pods using the web interface of OpenShift. As mentioned earlier, you can also use the CLI by either using oc or kubectl to create a new pod.
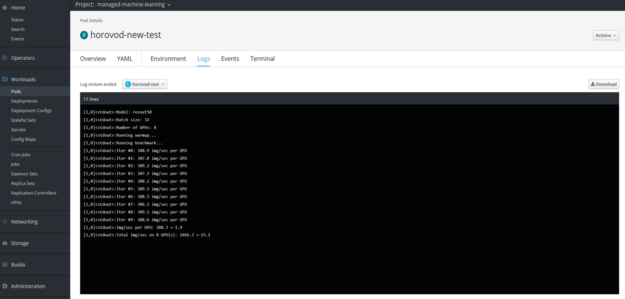
To retrieve outputs or logs of pods running in an OpenShift cluster, there are several possible ways. One way is to access the log through the CLI by using either kubectl logs, or oc logs:
kubectl logs <pod-name> -n <namespace> oc logs <pod-name> -n <namespace>
Figure 5 shows the other possibility, using the OpenShift GUI.
Multi-GPU, multi-node workload
There are a few ways to leverage the power of multiple systems for the benefit of a single DL training. Compute resources of multiple systems can be aggregated to accelerate training. This is especially beneficial for workloads such as DNN training in autonomous vehicle DNN development, as the turnaround time of an experiment is often a critical factor when running such workloads on large datasets.
Figure 1 shows two DGX systems working together in a single DL job. The DL workload uses 16 GPUs in total spreading across DGX-1 systems with 8 GPUs each. Each job processes its computation against a partition of the data.
All the workers synchronize their findings with their peers over NVIDIA NVLINK technology, which is a communication protocol developed by NVIDIA that allows transfers of data and control code between CPUs and GPUs or GPUs only, and the network. This synchronization step is visualized as the dashed line.
Reuse the same codebase and container from before. The only difference to the previous orchestration method is that you use the known MPI Operator. This simplifies the allocation and deployment of a workload across multiple DGX systems.
MPI Operator
There are several options to run multi-GPU, multi-node workloads on an OpenShift or Kubernetes cluster. One of the common frameworks is the MPI Operator, provided by the Kubeflow project. MPI Operator handles the orchestration of DL workloads, as shown earlier.
When you install the MPI Operator, you introduce a new kind of job type in the cluster: the MPIJob. The following code example of a job specification shows the corresponding YAML file to start this kind of MPIJob workload through OpenShift or Kubernetes. It can be deployed straight from the OpenShift login node, master node, or GUI.
In contrast to the YAML file found in the preceding section, this example file uses the NVIDIA TensorFlow Docker image and is running a synthetic ResNet-50 benchmark on 16 GPUs from two DGX-1 systems. Using the TensorFlow Docker image provided through NGC allows you to benefit from NVIDIA constant performance improvements. The communication between the three created pods, one launcher pod and two worker pods, is taken care of by the MPI Operator.
Like the YAML definition of the Horovod distributed model, the number of threads using mpirun -np 16 again corresponds to the number of GPUs requested. In this case, it is two worker pods, each with eight GPUs attached. You can scale up this example easily by changing the number of worker pods and the number of threads spawned.
A job specification for a 16-GPU training job looks like the following code example:
apiVersion: kubeflow.org/v1alpha2 kind: MPIJob metadata: name: 16gpu-tensorflow-benchmark-imagenet spec: slotsPerWorker: 8 cleanPodPolicy: Running mpiReplicaSpecs: Launcher: replicas: 1 template: spec: containers: - image: nvcr.io/nvidia/tensorflow:19.10-py3 name: tensorflow-benchmarks env: - name: NVIDIA_DRIVER_CAPABILITIES value: compute,utility - name: NVIDIA_REQUIRE_CUDA value: cuda>=9.0 command: - mpirun - -np - "16" - -bind-to - none - -map-by - slot - -x - NCCL_DEBUG=INFO - -x - LD_LIBRARY_PATH - -x - PATH - -mca - pml - ob1 - -mca - btl - ^openib - python - nvidia-examples/resnet50v1.5/main.py - --mode=training_benchmark - --batch_size=128 - --num_iter=90 - --iter_unit=epoch - --results_dir=/efs Worker: replicas: 2 template: spec: containers: - image: nvcr.io/nvidia/tensorflow:19.10-py3 name: tensorflow-benchmarks env: - name: NVIDIA_DRIVER_CAPABILITIES value: compute,utility - name: NVIDIA_REQUIRE_CUDA value: cuda>=9.0 resources: limits: nvidia.com/gpu: 8
On Kubernetes, the YAML file looks like the one used in OpenShift. One important difference is that environment variables in OpenShift v3.11 must be set inside the spec of the pods.
env: - name: NVIDIA_DRIVER_CAPABILITIES value: compute,utility - name: NVIDIA_REQUIRE_CUDA value: cuda>=9.0
Aggregating cutoff resources
In large computing environments, there is often a cutoff or some unused resources. The MPI Operator is of great use in such a case, as it can aggregate those cutoffs and avoid waste. This is a property that only the MPI Operator can deliver.
The following code example shows an exemplary two-GPU job that can aggregate resources from multiple systems. The job requests two GPUs for the workload. You can customize this example to fit almost every situation, for example three GPUs on three different nodes or four GPUs on two different nodes.
apiVersion: kubeflow.org/v1alpha2 kind: MPIJob metadata: name: tensorflow-benchmarks-gpu-v1a2 spec: slotsPerWorker: 1 cleanPodPolicy: Running mpiReplicaSpecs: Launcher: replicas: 1 template: spec: containers: - image: mpioperator/tensorflow-benchmarks:latest name: tensorflow-benchmarks-gpu env: - name: NVIDIA_DRIVER_CAPABILITIES value: compute,utility - name: NVIDIA_REQUIRE_CUDA value: cuda>=9.0 command: - mpirun - -np - "2" - -bind-to - none - -map-by - slot - -x - NCCL_DEBUG=INFO - -x - LD_LIBRARY_PATH - -x - PATH - -mca - pml - ob1 - -mca - btl - ^openib - -mca - plm_base_verbose - "100" - -mca - btl_base_verbose - "30" - python - scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py - --model=resnet101 - --batch_size=64 - --variable_update=horovod resources: limits: nvidia.com/gpu: 1 Worker: replicas: 2 template: spec: containers: - image: mpioperator/tensorflow-benchmarks:latest name: tensorflow-benchmarks env: - name: NVIDIA_DRIVER_CAPABILITIES value: compute,utility - name: NVIDIA_REQUIRE_CUDA value: cuda>=9.0 resources: limits: nvidia.com/gpu: 1
Running this YAML file results in a log file like the following. It can either be collected using the GUI or CLI.
oc logs <pod-name> -n <namespace> kubectl logs <pod-name> -n <namespace>
tensorflow-benchmarks-gpu-v1a2-worker-1:26:156 [0] NCCL INFO Ring 01 : 1 -> 0 [send] via NET/Socket/0 tensorflow-benchmarks-gpu-v1a2-worker-0:26:156 [0] NCCL INFO Ring 01 : 0 -> 1 [send] via NET/Socket/0 tensorflow-benchmarks-gpu-v1a2-worker-0:26:156 [0] NCCL INFO Using 256 threads, Min Comp Cap 7, Trees disabled tensorflow-benchmarks-gpu-v1a2-worker-1:26:156 [0] NCCL INFO comm 0x7f887032e120 rank 1 nranks 2 cudaDev 0 nvmlDev 7 - Init COMPLETE tensorflow-benchmarks-gpu-v1a2-worker-0:26:156 [0] NCCL INFO comm 0x7f003434e940 rank 0 nranks 2 cudaDev 0 nvmlDev 3 - Init COMPLETE tensorflow-benchmarks-gpu-v1a2-worker-0:26:156 [0] NCCL INFO Launch mode Parallel Done warm up Step Img/sec total_loss Done warm up Step Img/sec total_loss 1 images/sec: 147.6 +/- 0.0 (jitter = 0.0) 8.308 1 images/sec: 147.8 +/- 0.0 (jitter = 0.0) 8.378 10 images/sec: 159.1 +/- 2.3 (jitter = 4.7) 8.526
Querying for the running pods inside the cluster does show that cutoff resources from two nodes are being used.
$ oc get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE tensorflow-benchmarks-gpu-v1a2-launcher-dqgsk 1/1 Running 0 3m45s 10.233.XXX.XXX dgx01.dev.XXX tensorflow-benchmarks-gpu-v1a2-worker-0 1/1 Running 0 3m45s 10.233.XXX.XXX dgx02.dev.XXX tensorflow-benchmarks-gpu-v1a2-worker-1 1/1 Running 0 3m45s 10.233.XXX.XXX dgx01.dev.XXX
Docker network configuration
NCCL is discovering the topology with its peers. The following output was taken from one of the running pods. It shows that, besides the standard local adapter, there is only one additional connection configured.
eth0 Link encap:Ethernet HWaddr 0a:58:0a:81:07:b2 inet addr:10.129.7.178 Bcast:10.129.7.255 Mask:255.255.254.0 inet6 addr: fe80::419:d8ff:fe19:1bbd/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1 RX packets:21275 errors:0 dropped:0 overruns:0 frame:0 TX packets:33993 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:11305584 (11.3 MB) TX bytes:4496191 (4.4 MB) lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:28205726 errors:0 dropped:0 overruns:0 frame:0 TX packets:28205726 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:12809324160 (12.8 GB) TX bytes:12809324160 (12.8 GB)
Having one in a Docker NIC (here, eth0) is a starting point. A more sophisticated setup may use multiple Docker network adapters.
Get started with multi-GPU, multi-node training running on OpenShift
Adopt industry state-of-the-art DL workloads and deploy them at scale today. In this post, we showed you that data parallel training making use of the MPI paradigm is highly flexible for different environments.
With this style, DL engineers of a scalable DGX system cluster get the following benefits, regardless of their orchestration software:
- Scale beyond the limitations of a single node and enable DL in a larger cluster.
- Prevent turning resource cutoffs in waste by aggregating leftover resources effectively.
The Robotic Drive containerized compute platform on OpenShift orchestrates DL workloads at scale, including multi-GPU, multi-node jobs using NVIDIA DGX systems. These start with vision-based ML models with the capability to deliver a good technology base for state-of-the-art complex driving behavior tasks, such as motion planning. Those tasks require a lot of exploration and experiments, which are addressed by the Robotic Drive Innovation Lab program. This program focuses on customers and their problems in processing and learning on AD data.
